主从复制
概述
Redis 支持 master-slave(主从)模式,一个 redis server 可以设置为另一个 redis server 的主机(从机),从机定期从主机拿数据。特殊的,一个从机同样可以设置为一个 redis server 的主机,这样一来 master-slave 的分布看起来就是一个有向无环图 DAG,如此形成 redis server 集群,无论是主机还是从机都是 redis server,都可以提供服务。
在配置后,主机可负责读写服务,从机只负责读。Redis 提高这种配置方式,为的是让其支持数据的弱一致性,即最终一致性。在业务中,选择强一致性还是弱一致性,应该取决于具体的业务需求,比如微博里的 timeline,可以使用弱一致性模型;比如支付宝的支付账单,要选用强一致性模型。
积压空间
binlog 是在 mysql 中的一种日志类型,它记录了所有数据库自备份一来的所有更新操作或潜在的更新操作,描述了数据的更改。因为 binlog 只记录了数据的更新,所以适合用来做实时备份和主从复制。同样,Redis 在主从复制上用的就是一种类似 binlog 的日志。在《AOF 持久化策略》中,介绍了更新缓存的概念,举一个例子:客户端发来命令:set name Jhon,这一数据更新被记录为:*3/r/n$3/r/nSET/r/n$4/r/nname/r/n$3/r/nJhon/r/n,并存储在更新缓存中。
同样,在主从连接中,也有更新缓存的概念。只是两者的用途不一样,前者被写入本地,后者被写入从机,这里我们把它成为积压空间。更新缓存存储在 server.repl_backlog,Redis 将其作为一个环形空间来处理,这样做节省了空间,避免内存再分配的情况。
struct redisServer {
......
/* Replication (master) */
// 最近一次使用(访问)的数据集
int slaveseldb; /* Last SELECTed DB in replication output */
// 全局的数据同步偏移量
long long master_repl_offset; /* Global replication offset */
// 主从连接心跳频率
int repl_ping_slave_period; /* Master pings the slave every N seconds */
// 积压空间指针
char *repl_backlog; /* Replication backlog for partial syncs */
// 积压空间大小
long long repl_backlog_size; /* Backlog circular buffer size */
// 积压空间中写入的新数据的大小
long long repl_backlog_histlen; /* Backlog actual data length */
// 下一次向积压空间写入数据的起始位置
long long repl_backlog_idx; /* Backlog circular buffer current offset */
// 积压数据的起始位置的所对应的全局主从复制偏移量
long long repl_backlog_off; /* Replication offset of first byte in the
backlog buffer. */
// 积压空间有效时间
time_t repl_backlog_time_limit; /* Time without slaves after the backlog
gets released. */
......
}积压空间中的数据变更记录是什么时候被写入的?在执行一个 Redis 命令的时候,如果存在数据的修改(写),那么就会把变更记录传播。Redis 源码中是这么实现的:call()->propagate()->replicationFeedSlaves()。
需注意,命令真正执行的地方在 call() 中,call() 如果发现数据被修改(dirty),则传播 propagrate(),replicationFeedSlaves() 将修改记录写入积压空间和所有已连接的从机。
同样,在《AOF 持久化策略》提到的,propagrate() 也会将数据的修改记录写入到更新缓存中。
这里可能会有疑问:为什么把数据添加入积压空间,又把数据分发给所有的从机?为什么不仅仅将数据分发给所有从机呢?
因为有一些从机会因特殊情况,与主机断开连接。从机断开前有暂存主机的状态信息,因此这些断开的从机就没有及时收到更新的数据。Redis 为了让断开的从机在下次连接后能够获取更新数据,将更新数据加入了积压空间。从replicationFeedSlaves() 实现来看,在线的 slave 能马上收到数据更新记录;因某些原因暂时断开连接的slave,需要从积压空间中找回断开期间的数据更新记录。如果断开的时间足够长,master 会拒绝 slave 的部分 同步请求,从而slave 只能进行全同步。
下面是更细积压空间的核心代码注释:首先,在命令执行函数中,如果发现是涉及写的命令,会将修改传播,即调用 propagrate()
// call() 函数是执行命令的核心函数,真正执行命令的地方
/* Call() is the core of Redis execution of a command */
void call(redisClient *c, int flags) {
......
/* Call the command. */
c->flags &= ~(REDIS_FORCE_AOF|REDIS_FORCE_REPL);
redisOpArrayInit(&server.also_propagate);
// 脏数据标记,数据是否被修改
dirty = server.dirty;
// 执行命令对应的函数
c->cmd->proc(c);
dirty = server.dirty-dirty;
duration = ustime()-start;
......
// 将客户端请求的数据修改记录传播给AOF 和从机
/* Propagate the command into the AOF and replication link */
if (flags & REDIS_CALL_PROPAGATE) {
int flags = REDIS_PROPAGATE_NONE;
// 强制主从复制
if (c->flags & REDIS_FORCE_REPL) flags |= REDIS_PROPAGATE_REPL;
// 强制AOF 持久化
if (c->flags & REDIS_FORCE_AOF) flags |= REDIS_PROPAGATE_AOF;
// 数据被修改
if (dirty)
flags |= (REDIS_PROPAGATE_REPL | REDIS_PROPAGATE_AOF);
// 传播数据修改记录
if (flags != REDIS_PROPAGATE_NONE)
propagate(c->cmd,c->db->id,c->argv,c->argc,flags);
}
......
}主要向两个方向传播修改记录,一个是 AOF 持久化,另一个则是主从复制。
// 向AOF 和从机发布数据更新
/* Propagate the specified command (in the context of the specified database id)
* to AOF and Slaves.
**
flags are an xor between:
* + REDIS_PROPAGATE_NONE (no propagation of command at all)
* + REDIS_PROPAGATE_AOF (propagate into the AOF file if is enabled)
* + REDIS_PROPAGATE_REPL (propagate into the replication link)
*/
void propagate(struct redisCommand *cmd, int dbid, robj **argv, int argc,
int flags)
{
// AOF 策略需要打开,且设置AOF 传播标记,将更新发布给本地文件
if (server.aof_state != REDIS_AOF_OFF && flags & REDIS_PROPAGATE_AOF)
feedAppendOnlyFile(cmd,dbid,argv,argc);
// 设置了从机传播标记,将更新发布给从机
if (flags & REDIS_PROPAGATE_REPL)
replicationFeedSlaves(server.slaves,dbid,argv,argc);
}向从机传播更新记录的时候,Redis 主机会向所有的从机发送变更记录,同时也会写入到积压空间,方便已经断开的从机,再下一次重新连接的时候,拷贝数据。
// 向积压空间和从机发送数据
void replicationFeedSlaves(list *slaves, int dictid, robj **argv, int argc) {
listNode *ln;
listIter li;
int j, len;
char llstr[REDIS_LONGSTR_SIZE];
// 没有积压数据且没有从机,直接退出
/* If there aren't slaves, and there is no backlog buffer to populate,
* we can return ASAP. */
if (server.repl_backlog == NULL && listLength(slaves) == 0) return;
/* We can't have slaves attached and no backlog. */
redisAssert(!(listLength(slaves) != 0 && server.repl_backlog == NULL));
/* Send SELECT command to every slave if needed. */
if (server.slaveseldb != dictid) {
robj *selectcmd;
// 小于等于10 的可以用共享对象
/* For a few DBs we have pre-computed SELECT command. */
if (dictid >= 0 && dictid < REDIS_SHARED_SELECT_CMDS) {
selectcmd = shared.select[dictid];
} else {
// 不能使用共享对象,生成SELECT 命令对应的redis 对象
int dictid_len;
dictid_len = ll2string(llstr,sizeof(llstr),dictid);
selectcmd = createObject(REDIS_STRING,
sdscatprintf(sdsempty(),
"*2\r\n$6\r\nSELECT\r\n$%d\r\n%s\r\n",
dictid_len, llstr));
}
// 这里可能会有疑问:为什么把数据添加入积压空间,又把数据分发给所有的从机?
// 为什么不仅仅将数据分发给所有从机呢?
// 因为有一些从机会因特殊情况,与主机断开连接。从机断开前有暂存
// 主机的状态信息,因此这些断开的从机就没有及时收到更新的数据。redis 为了让
// 断开的从机在下次连接后能够获取更新数据,将更新数据加入了积压空间。
// 将SELECT 命令对应的redis 对象数据添加到积压空间
/* Add the SELECT command into the backlog. */
if (server.repl_backlog) feedReplicationBacklogWithObject(selectcmd);
// 将数据分发所有的从机
/* Send it to slaves. */
listRewind(slaves,&li);
while((ln = listNext(&li))) {
redisClient *slave = ln->value;
addReply(slave,selectcmd);
}
// 销毁对象
if (dictid < 0 || dictid >= REDIS_SHARED_SELECT_CMDS)
decrRefCount(selectcmd);
}
// 更新最近一次使用(访问)的数据集
server.slaveseldb = dictid;
// 将命令写入积压空间
/* Write the command to the replication backlog if any. */
if (server.repl_backlog) {
char aux[REDIS_LONGSTR_SIZE+3];
// 命令个数
/* Add the multi bulk reply length. */
aux[0] = '*';
len = ll2string(aux+1,sizeof(aux)-1,argc);
aux[len+1] = '\r';
aux[len+2] = '\n';
feedReplicationBacklog(aux,len+3);
// 逐个命令写入
for (j = 0; j < argc; j++) {
long objlen = stringObjectLen(argv[j]);
/* We need to feed the buffer with the object as a bulk reply
* not just as a plain string, so create the $..CRLF payload len
* ad add the final CRLF */
aux[0] = '$';
len = ll2string(aux+1,sizeof(aux)-1,objlen);
aux[len+1] = '\r';
aux[len+2] = '\n';
/* 每个命令格式如下:
$3
*3
SET
*4
NAME
*4
Jhon*/
// 命令长度
feedReplicationBacklog(aux,len+3);
// 命令
feedReplicationBacklogWithObject(argv[j]);
// 换行
feedReplicationBacklog(aux+len+1,2);
}
}
// 立即给每一个从机发送命令
/* Write the command to every slave. */
listRewind(slaves,&li);
while((ln = listNext(&li))) {
redisClient *slave = ln->value;
// 如果从机要求全同步,则不对此从机发送数据
/* Don't feed slaves that are still waiting for BGSAVE to start */
if (slave->replstate == REDIS_REPL_WAIT_BGSAVE_START) continue;
/* Feed slaves that are waiting for the initial SYNC (so these commands
* are queued in the output buffer until the initial SYNC completes),
* or are already in sync with the master. */
// 向从机命令的长度
/* Add the multi bulk length. */
addReplyMultiBulkLen(slave,argc);
}
}主从数据同步机制概述
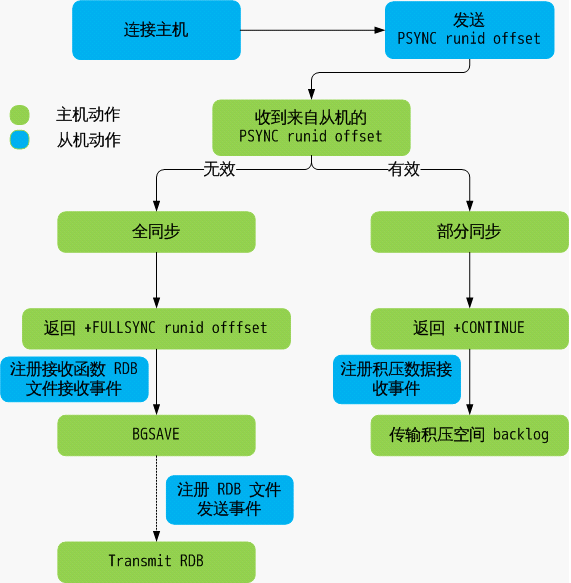
Redis 主从同步有两种方式(或者所两个阶段):全同步和部分同步。
主从刚刚连接的时候,进行全同步;全同步结束后,进行部分同步。如果有需要,slave 在任何时候都可以发起全同步。Redis 策略是,无论如何,首先会尝试进行部分同步,如不成功,要求从机进行全同步,并启动BGSAVE⋯⋯BGSAVE 结束后,传输 RDB 文件;如果成功,允许从机进行部分同步,并传输积压空间中的数据。
如需设置 slave,master 需要向slave 发送 SLAVEOF hostname port,从机接收到后会自动连接主机,注册相应读写事件(syncWithMaster())。
// 修改主机
void slaveofCommand(redisClient *c) {
if (!strcasecmp(c->argv[1]->ptr,"no") &&
!strcasecmp(c->argv[2]->ptr,"one")) {
// slaveof no one 断开主机连接
if (server.masterhost) {
replicationUnsetMaster();
redisLog(REDIS_NOTICE,"MASTER MODE enabled (user request)");
}
} else {
long port;
if ((getLongFromObjectOrReply(c, c->argv[2], &port, NULL) != REDIS_OK))
return;
// 可能已经连接需要连接的主机
/* Check if we are already attached to the specified slave */
if (server.masterhost && !strcasecmp(server.masterhost,c->argv[1]->ptr)
&& server.masterport == port) {
redisLog(REDIS_NOTICE,"SLAVE OF would result into synchronization with the master addReplySds(c,sdsnew("+OK Already connected to specified master\r\n"));
return;
}
// 断开之前连接主机的连接,连接新的。replicationSetMaster() 并不会真正连接主机,只是修改/* There was no previous master or the user specified a different one,
* we can continue. */
replicationSetMaster(c->argv[1]->ptr, port);
redisLog(REDIS_NOTICE,"SLAVE OF %s:%d enabled (user request)",
server.masterhost, server.masterport);
}
addReply(c,shared.ok);
}
// 设置新主机
/* Set replication to the specified master address and port. */
void replicationSetMaster(char *ip, int port) {
sdsfree(server.masterhost);
server.masterhost = sdsdup(ip);
server.masterport = port;
// 断开之前主机的连接
if (server.master) freeClient(server.master);
disconnectSlaves(); /* Force our slaves to resync with us as well. */
// 取消缓存主机
replicationDiscardCachedMaster(); /* Don't try a PSYNC. */
// 释放积压空间
freeReplicationBacklog(); /* Don't allow our chained slaves to PSYNC. */
// cancelReplicationHandshake() 尝试断开数据传输和主机连接
cancelReplicationHandshake();
server.repl_state = REDIS_REPL_CONNECT;
server.master_repl_offset = 0;
}
// 管理主从连接的定时程序定时程序,每秒执行一次
// 在serverCorn() 中调用
/* --------------------------- REPLICATION CRON ----------------------------- */
/* Replication cron funciton, called 1 time per second. */
void replicationCron(void) {
......
// 如果需要(EDIS_REPL_CONNECT),尝试连接主机,真正连接主机的操作在这里
/* Check if we should connect to a MASTER */
if (server.repl_state == REDIS_REPL_CONNECT) {
redisLog(REDIS_NOTICE,"Connecting to MASTER %s:%d",
server.masterhost, server.masterport);
if (connectWithMaster() == REDIS_OK) {
redisLog(REDIS_NOTICE,"MASTER <-> SLAVE sync started");
}
}
......
}全同步
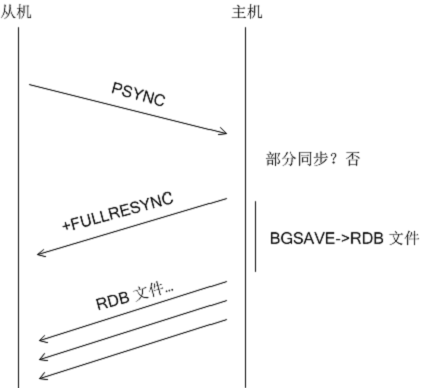
无论如何,Redis 首先会尝试部分同步,如果失败才尝试全同步。而刚刚建立连接的 master-slave 需要全同步。
从机连接主机后,会主动发起 PSYNC 命令,从机会提供 master_runid 和offset,主机验证 master_runid 和 offset 是否有效?master_runid 相当于主机身份验证码,用来验证从机上一次连接的主机,offset 是全局积压空间数据的偏移量。
验证未通过则,则进行全同步:主机返回+FULLRESYNC master_runid offset(从机接收并记录 master_runid 和 offset,并准备接收RDB 文件)接着启动 BGSAVE 生成 RDB 文件,BGSAVE 结束后,向从机传输,从而完成全同步。
主机和从机之间的交互图如下:
// 连接主机connectWithMaster() 的时候,会被注册为回调函数
void syncWithMaster(aeEventLoop *el, int fd, void *privdata, int mask) {
char tmpfile[256], *err;
int dfd, maxtries = 5;
int sockerr = 0, psync_result;
socklen_t errlen = sizeof(sockerr);
......
// 这里尝试向主机请求部分同步,主机会回复以拒绝或接受请求。如果拒绝部分同步,
// 会返回+FULLRESYNC master_runid offset
// 从机接收后准备进行全同步
psync_result = slaveTryPartialResynchronization(fd);
if (psync_result == PSYNC_CONTINUE) {
redisLog(REDIS_NOTICE, "MASTER <-> SLAVE sync: Master accepted a "
"Partial Resynchronization.");
return;
}
// 执行全同步
/* Fall back to SYNC if needed. Otherwise psync_result == PSYNC_FULLRESYNC
* and the server.repl_master_runid and repl_master_initial_offset are
* already populated. */
// 未知结果,进行出错处理
if (psync_result == PSYNC_NOT_SUPPORTED) {
redisLog(REDIS_NOTICE,"Retrying with SYNC...");
if (syncWrite(fd,"SYNC\r\n",6,server.repl_syncio_timeout*1000) == -1) {
redisLog(REDIS_WARNING,"I/O error writing to MASTER: %s",
strerror(errno));
goto error;
}
}
// 为什么要尝试5 次???
/* Prepare a suitable temp file for bulk transfer */
while(maxtries--) {
snprintf(tmpfile,256,
"temp-%d.%ld.rdb",(int)server.unixtime,(long int)getpid());
dfd = open(tmpfile,O_CREAT|O_WRONLY|O_EXCL,0644);
if (dfd != -1) break;
sleep(1);
}
if (dfd == -1) {
redisLog(REDIS_WARNING,"Opening the temp file needed for MASTER <-> "
"SLAVE synchronization: %s",strerror(errno));
goto error;
}
// 注册读事件,回调函数readSyncBulkPayload(), 准备读RDB 文件
/* Setup the non blocking download of the bulk file. */
if (aeCreateFileEvent(server.el,fd, AE_READABLE,readSyncBulkPayload,NULL)
== AE_ERR)
{
redisLog(REDIS_WARNING,
"Can't create readable event for SYNC: %s (fd=%d)",
strerror(errno),fd);
goto error;
}
// 设置传输RDB 文件数据的选项
// 状态
server.repl_state = REDIS_REPL_TRANSFER;
// RDB 文件大小
server.repl_transfer_size = -1;
// 已经传输的大小
server.repl_transfer_read = 0;
// 上一次同步的偏移,为的是定时写入磁盘
server.repl_transfer_last_fsync_off = 0;
// 本地RDB 文件套接字
server.repl_transfer_fd = dfd;
// 上一次同步IO 时间
server.repl_transfer_lastio = server.unixtime;
// 临时文件名
server.repl_transfer_tmpfile = zstrdup(tmpfile);
return;
error:
close(fd);
server.repl_transfer_s = -1;
server.repl_state = REDIS_REPL_CONNECT;
return;
}全同步请求的数据是RDB 数据文件和积压空间中的数据。关于 RDB 数据文件,请参见《RDB 持久化策略》。如果没有后台持久化 BGSAVE 进程,那么 BGSVAE 会被触发,否则所有请求全同步的 slave 都会被标记为等待 BGSAVE 结束。BGSAVE 结束后,master 会马上向所有的从机发送 RDB 文件。
下面 syncCommand() 摘取全同步的部分:
// 主机SYNC 和PSYNC 命令处理函数,会尝试进行部分同步和全同步
/* SYNC ad PSYNC command implemenation. */
void syncCommand(redisClient *c) {
......
// 主机尝试部分同步,失败的话向从机发送+FULLRESYNC master_runid offset,
// 接着启动BGSAVE
// 执行全同步:
/* Full resynchronization. */
server.stat_sync_full++;
/* Here we need to check if there is a background saving operation
* in progress, or if it is required to start one */
if (server.rdb_child_pid != -1) {
/* 存在BGSAVE 后台进程。
1. 如果master 现有所连接的所有从机slaves 当中有存在
REDIS_REPL_WAIT_BGSAVE_END 的从机,那么将从机c 设置为
REDIS_REPL_WAIT_BGSAVE_END;
2. 否则,设置为REDIS_REPL_WAIT_BGSAVE_START*/
/* Ok a background save is in progress. Let's check if it is a good
* one for replication, i.e. if there is another slave that is
* registering differences since the server forked to save */
redisClient *slave;
listNode *ln;
listIter li;
// 检测是否已经有从机申请全同步
listRewind(server.slaves,&li);
while((ln = listNext(&li))) {
slave = ln->value;
if (slave->replstate == REDIS_REPL_WAIT_BGSAVE_END) break;
}
if (ln) {
// 存在状态为REDIS_REPL_WAIT_BGSAVE_END 的从机slave,
// 就将此从机c 状态设置为REDIS_REPL_WAIT_BGSAVE_END,
// 从而在BGSAVE 进程结束后,可以发送RDB 文件,
// 同时将从机slave 中的更新复制到此从机c。
/* Perfect, the server is already registering differences for
* another slave. Set the right state, and copy the buffer. */
// 将其他从机上的待回复的缓存复制到从机c
copyClientOutputBuffer(c,slave);
// 修改从机c 状态为「等待BGSAVE 进程结束」
c->replstate = REDIS_REPL_WAIT_BGSAVE_END;
redisLog(REDIS_NOTICE,"Waiting for end of BGSAVE for SYNC");
} else {
// 不存在状态为REDIS_REPL_WAIT_BGSAVE_END 的从机,就将此从机c 状态设置为
// REDIS_REPL_WAIT_BGSAVE_START,即等待新的BGSAVE 进程的开启。
// 修改状态为「等待BGSAVE 进程开始」
/* No way, we need to wait for the next BGSAVE in order to
* register differences */
c->replstate = REDIS_REPL_WAIT_BGSAVE_START;
redisLog(REDIS_NOTICE,"Waiting for next BGSAVE for SYNC");
}
} else {
// 不存在BGSAVE 后台进程,启动一个新的BGSAVE 进程
* Ok we don't have a BGSAVE in progress, let's start one */
redisLog(REDIS_NOTICE,"Starting BGSAVE for SYNC");
if (rdbSaveBackground(server.rdb_filename) != REDIS_OK) {
redisLog(REDIS_NOTICE,"Replication failed, can't BGSAVE");
addReplyError(c,"Unable to perform background save");
return;
}
// 将此从机c 状态设置为REDIS_REPL_WAIT_BGSAVE_END,从而在BGSAVE
// 进程结束后,可以发送RDB 文件,同时将从机slave 中的更新复制到此从机c。
c->replstate = REDIS_REPL_WAIT_BGSAVE_END;
// 清理脚本缓存???
/* Flush the script cache for the new slave. */
replicationScriptCacheFlush();
}
if (server.repl_disable_tcp_nodelay)
anetDisableTcpNoDelay(NULL, c->fd); /* Non critical if it fails. */
c->repldbfd = -1;
c->flags |= REDIS_SLAVE;
server.slaveseldb = -1; /* Force to re-emit the SELECT command. */
listAddNodeTail(server.slaves,c);
if (listLength(server.slaves) == 1 && server.repl_backlog == NULL)
createReplicationBacklog();
return;
}主机执行完 BGSAVE 后,会将 RDB 文件发送给从机。
// BGSAVE 结束后,会调用
/* A background saving child (BGSAVE) terminated its work. Handle this. */
void backgroundSaveDoneHandler(int exitcode, int bysignal) {
// 其他操作
......
// 可能从机正在等待BGSAVE 进程的终止
/* Possibly there are slaves waiting for a BGSAVE in order to be served
* (the first stage of SYNC is a bulk transfer of dump.rdb) */
updateSlavesWaitingBgsave(exitcode == 0 ? REDIS_OK : REDIS_ERR);
}
// 当RDB 持久化(backgroundSaveDoneHandler()) 结束后,会调用此函数
// RDB 文件就绪,给所有的从机发送RDB 文件
/* This function is called at the end of every background saving.
* The argument bgsaveerr is REDIS_OK if the background saving succeeded
* otherwise REDIS_ERR is passed to the function.
**
The goal of this function is to handle slaves waiting for a successful
* background saving in order to perform non-blocking synchronization. */
void updateSlavesWaitingBgsave(int bgsaveerr) {
listNode *ln;
int startbgsave = 0;
listIter li;
listRewind(server.slaves,&li);
while((ln = listNext(&li))) {
redisClient *slave = ln->value;
// 等待BGSAVE 开始。调整状态为等待下一次BGSAVE 进程的结束
if (slave->replstate == REDIS_REPL_WAIT_BGSAVE_START) {
startbgsave = 1;
slave->replstate = REDIS_REPL_WAIT_BGSAVE_END;
// 等待BGSAVE 结束。准备向slave 发送RDB 文件
} else if (slave->replstate == REDIS_REPL_WAIT_BGSAVE_END) {
struct redis_stat buf;
// 如果RDB 持久化失败, bgsaveerr 会被设置为REDIS_ERR
if (bgsaveerr != REDIS_OK) {
freeClient(slave);
redisLog(REDIS_WARNING,"SYNC failed. BGSAVE child returned "
"an error");
continue;
}
// 打开RDB 文件
if ((slave->repldbfd = open(server.rdb_filename,O_RDONLY)) == -1 ||
redis_fstat(slave->repldbfd,&buf) == -1) {
freeClient(slave);
redisLog(REDIS_WARNING,"SYNC failed. Can't open/stat DB after"
" BGSAVE: %s", strerror(errno));
continue;
}
slave->repldboff = 0;
slave->repldbsize = buf.st_size;
slave->replstate = REDIS_REPL_SEND_BULK;
// 如果之前有注册写事件,取消
aeDeleteFileEvent(server.el,slave->fd,AE_WRITABLE);
// 注册新的写事件,sendBulkToSlave() 传输RDB 文件
if (aeCreateFileEvent(server.el, slave->fd, AE_WRITABLE,
sendBulkToSlave, slave) == AE_ERR) {
freeClient(slave);
continue;
}
}
}
// startbgsave == REDIS_ERR 表示BGSAVE 失败,再一次进行BGSAVE 尝试
if (startbgsave) {
/* Since we are starting a new background save for one or more slaves,
* we flush the Replication Script Cache to use EVAL to propagate every
* new EVALSHA for the first time, since all the new slaves don't know
* about previous scripts. */
replicationScriptCacheFlush();
if (rdbSaveBackground(server.rdb_filename) != REDIS_OK) {
/*BGSAVE 可能fork 失败,所有等待BGSAVE 的从机都将结束连接。这是
redis 自我保护的措施,fork 失败很可能是内存紧张*/
listIter li;
listRewind(server.slaves,&li);
redisLog(REDIS_WARNING,"SYNC failed. BGSAVE failed");
while((ln = listNext(&li))) {
redisClient *slave = ln->value;
if (slave->replstate == REDIS_REPL_WAIT_BGSAVE_START)
freeClient(slave);
}
}
}
}部分同步
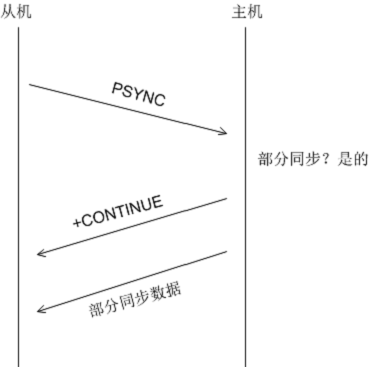
如上所说,无论如何,Redis 首先会尝试部分同步。部分同步即把积压空间缓存的数据,即更新记录发送给从机。
从机连接主机后,会主动发起 PSYNC 命令,从机会提供 master_runid 和offset,主机验证 master_runid 和 offset 是否有效?验证通过则,进行部分同步:主机返回 +CONTINUE(从机接收后会注册积压数据接收事件),接着发送积压空间数据。
主机和从机之间的交互图如下:
syncWithMaster() 已经被设置为回调函数,当与主机建立连接后,syncWithMaster() 会被回调,这一点查阅在 connectWithMaster() 函数。首先如果该从机从未与主机有过连接,那么会进行全同步,从主机拷贝所有的数据;否则,会尝试进行部分同步。
// 连接主机connectWithMaster() 的时候,会被注册为回调函数
void syncWithMaster(aeEventLoop *el, int fd, void *privdata, int mask) {
char tmpfile[256], *err;
int dfd, maxtries = 5;
int sockerr = 0, psync_result;
socklen_t errlen = sizeof(sockerr);
......
// 尝试部分同步,主机允许进行部分同步会返回+CONTINUE,从机接收后注册相应的事件
/* Try a partial resynchonization. If we don't have a cached master
* slaveTryPartialResynchronization() will at least try to use PSYNC
* to start a full resynchronization so that we get the master run id
* and the global offset, to try a partial resync at the next
* reconnection attempt. */
// 函数返回三种状态:
// PSYNC_CONTINUE:表示会进行部分同步,在slaveTryPartialResynchronization()
// 中已经设置回调函数readQueryFromClient()
// PSYNC_FULLRESYNC:全同步,会下载RDB 文件
// PSYNC_NOT_SUPPORTED:未知
psync_result = slaveTryPartialResynchronization(fd);
if (psync_result == PSYNC_CONTINUE) {
redisLog(REDIS_NOTICE, "MASTER <-> SLAVE sync: Master accepted a "
"Partial Resynchronization.");
return;
}
// 执行全同步
......
}slaveTryPartialResynchronization() 主要工作是判断是进行全同步还是部分同步。
// 函数返回三种状态:
// PSYNC_CONTINUE:表示会进行部分同步,已经设置回调函数
// PSYNC_FULLRESYNC:全同步,会下载RDB 文件
// PSYNC_NOT_SUPPORTED:未知
#define PSYNC_CONTINUE 0
#define PSYNC_FULLRESYNC 1
#define PSYNC_NOT_SUPPORTED 2
int slaveTryPartialResynchronization(int fd) {
char *psync_runid;
char psync_offset[32];
sds reply;
/* Initially set repl_master_initial_offset to -1 to mark the current
* master run_id and offset as not valid. Later if we'll be able to do
* a FULL resync using the PSYNC command we'll set the offset at the
* right value, so that this information will be propagated to the
* client structure representing the master into server.master. */
server.repl_master_initial_offset = -1;
if (server.cached_master) {
// 缓存了上一次与主机连接的信息,可以尝试进行部分同步,减少数据传输
psync_runid = server.cached_master->replrunid;
snprintf(psync_offset,sizeof(psync_offset),"%lld",
server.cached_master->reploff+1);
redisLog(REDIS_NOTICE,"Trying a partial resynchronization "
"(request %s:%s).", psync_runid, psync_offset);
} else {
// 未缓存上一次与主机连接的信息,进行全同步
// psync ? -1 可以获取主机的master_runid
redisLog(REDIS_NOTICE,"Partial resynchronization not possible "
"(no cached master)");
psync_runid = "?";
memcpy(psync_offset,"-1",3);
}
// 向主机发送命令,并接收回复
/* Issue the PSYNC command */
reply = sendSynchronousCommand(fd,"PSYNC",psync_runid,psync_offset,NULL);
// 全同步
if (!strncmp(reply,"+FULLRESYNC",11)) {
char *runid = NULL, *offset = NULL;
/* FULL RESYNC, parse the reply in order to extract the run id
* and the replication offset. */
runid = strchr(reply,' ');
if (runid) {
runid++;
offset = strchr(runid,' ');
if (offset) offset++;
}
if (!runid || !offset || (offset-runid-1) != REDIS_RUN_ID_SIZE) {
redisLog(REDIS_WARNING,
"Master replied with wrong +FULLRESYNC syntax.");
/* This is an unexpected condition, actually the +FULLRESYNC
* reply means that the master supports PSYNC, but the reply
* format seems wrong. To stay safe we blank the master
* runid to make sure next PSYNCs will fail. */
memset(server.repl_master_runid,0,REDIS_RUN_ID_SIZE+1);
} else {
// 拷贝runid
memcpy(server.repl_master_runid, runid, offset-runid-1);
server.repl_master_runid[REDIS_RUN_ID_SIZE] = '\0';
server.repl_master_initial_offset = strtoll(offset,NULL,10);
redisLog(REDIS_NOTICE,"Full resync from master: %s:%lld",
server.repl_master_runid,
server.repl_master_initial_offset);
}
/* We are going to full resync, discard the cached master structure. */
replicationDiscardCachedMaster();
sdsfree(reply);
return PSYNC_FULLRESYNC;
}
// 部分同步
if (!strncmp(reply,"+CONTINUE",9)) {
/* Partial resync was accepted, set the replication state accordingly */
redisLog(REDIS_NOTICE,
"Successful partial resynchronization with master.");
sdsfree(reply);
// 缓存主机替代现有主机,且为PSYNC(部分同步) 做好准备
replicationResurrectCachedMaster(fd);
return PSYNC_CONTINUE;
}
/* If we reach this point we receied either an error since the master does
* not understand PSYNC, or an unexpected reply from the master.
* Reply with PSYNC_NOT_SUPPORTED in both cases. */
// 接收到主机发出的错误信息
if (strncmp(reply,"-ERR",4)) {
/* If it's not an error, log the unexpected event. */
redisLog(REDIS_WARNING,
"Unexpected reply to PSYNC from master: %s", reply);
} else {
redisLog(REDIS_NOTICE,
"Master does not support PSYNC or is in "
"error state (reply: %s)", reply);
}
sdsfree(reply);
replicationDiscardCachedMaster();
return PSYNC_NOT_SUPPORTED;
}下面 syncCommand() 摘取部分同步的部分:
// 主机SYNC 和PSYNC 命令处理函数,会尝试进行部分同步和全同步
/* SYNC ad PSYNC command implemenation. */
void syncCommand(redisClient *c) {
......
// 主机尝试部分同步,允许则进行部分同步,会返回+CONTINUE,接着发送积压空间
/* Try a partial resynchronization if this is a PSYNC command.
* If it fails, we continue with usual full resynchronization, however
* when this happens masterTryPartialResynchronization() already
* replied with:
**
+FULLRESYNC <runid> <offset>
**
So the slave knows the new runid and offset to try a PSYNC later
* if the connection with the master is lost. */
if (!strcasecmp(c->argv[0]->ptr,"psync")) {
// 部分同步
if (masterTryPartialResynchronization(c) == REDIS_OK) {
server.stat_sync_partial_ok++;
return; /* No full resync needed, return. */
} else {
// 部分同步失败,会进行全同步,这时会收到来自客户端的runid
char *master_runid = c->argv[1]->ptr;
/* Increment stats for failed PSYNCs, but only if the
* runid is not "?", as this is used by slaves to force a full
* resync on purpose when they are not albe to partially
* resync. */
if (master_runid[0] != '?') server.stat_sync_partial_err++;
}
} else {
/* If a slave uses SYNC, we are dealing with an old implementation
* of the replication protocol (like redis-cli --slave). Flag the client
* so that we don't expect to receive REPLCONF ACK feedbacks. */
c->flags |= REDIS_PRE_PSYNC_SLAVE;
}
// 执行全同步:
......
}主机虽然收到了来自从机的部分同步的请求,但主机并不一定会允许进行部分同步。在主机侧,如果收到部分同步的请求,还需要验证从机是否适合进行部分同步。
// 主机尝试是否能进行部分同步
/* This function handles the PSYNC command from the point of view of a
* master receiving a request for partial resynchronization.
**
On success return REDIS_OK, otherwise REDIS_ERR is returned and we proceed
* with the usual full resync. */
int masterTryPartialResynchronization(redisClient *c) {
long long psync_offset, psync_len;
char *master_runid = c->argv[1]->ptr;
char buf[128];
int buflen;
/* Is the runid of this master the same advertised by the wannabe slave
* via PSYNC? If runid changed this master is a different instance and
* there is no way to continue. */
if (strcasecmp(master_runid, server.runid)) {
// 当因为异常需要与主机断开连接的时候,从机会暂存主机的状态信息,以便
// 下一次的部分同步。
// 1)master_runid 是从机提供一个因缓存主机的runid,
// 2)server.runid 是本机(主机)的runid。
// 匹配失败,说明是本机(主机)不是从机缓存的主机,这时候不能进行部分同步,
// 只能进行全同步
// "?" 表示从机要求全同步
// 什么时候从机会要求全同步???
/* Run id "?" is used by slaves that want to force a full resync. */
if (master_runid[0] != '?') {
redisLog(REDIS_NOTICE,"Partial resynchronization not accepted: "
"Runid mismatch (Client asked for '%s', I'm '%s')",
master_runid, server.runid);
} else {
redisLog(REDIS_NOTICE,"Full resync requested by slave.");
}
goto need_full_resync;
}
// 从参数中解析整数,整数是从机指定的偏移量
/* We still have the data our slave is asking for? */
if (getLongLongFromObjectOrReply(c,c->argv[2],&psync_offset,NULL) !=
REDIS_OK) goto need_full_resync;
// 部分同步失败的情况:
// 1、不存在积压空间
if (!server.repl_backlog ||
// 2、psync_offset 太过小,即从机错过太多更新记录,安全起见,实行全同步
// 我们知道,积压空间的大小是有限的,如果某个从机错过的更新过多,将无法
// 在积压空间中找到更新的记录
psync_offset 越界
psync_offset < server.repl_backlog_off ||
psync_offset > (server.repl_backlog_off + server.repl_backlog_histlen))
// 经检测,不满足部分同步的条件,转而进行全同步
{
redisLog(REDIS_NOTICE,
"Unable to partial resync with the slave for lack of backlog "
"(Slave request was: %lld).", psync_offset);
if (psync_offset > server. ) {
redisLog(REDIS_WARNING,
"Warning: slave tried to PSYNC with an offset that is "
"greater than the master replication offset.");
}
goto need_full_resync;
}
// 执行部分同步:
// 1)标记客户端为从机
// 2)通知从机准备接收数据。从机收到+CONTINUE 会做好准备
// 3)开发发送数据
/* If we reached this point, we are able to perform a partial resync:
* 1) Set client state to make it a slave.
* 2) Inform the client we can continue with +CONTINUE
* 3) Send the backlog data (from the offset to the end) to the slave. */
// 将连接的客户端标记为从机
c->flags |= REDIS_SLAVE;
// 表示进行部分同步
// #define REDIS_REPL_ONLINE 9 /* RDB file transmitted, sending just
// updates. */
c->replstate = REDIS_REPL_ONLINE;
// 更新ack 的时间
c->repl_ack_time = server.unixtime;
// 添加入从机链表
listAddNodeTail(server.slaves,c);
// 告诉从机可以进行部分同步,从机收到后会做相关的准备(注册回调函数)
/* We can't use the connection buffers since they are used to accumulate
* new commands at this stage. But we are sure the socket send buffer is
* emtpy so this write will never fail actually. */
buflen = snprintf(buf,sizeof(buf),"+CONTINUE\r\n");
if (write(c->fd,buf,buflen) != buflen) {
freeClientAsync(c);
return REDIS_OK;
}
// 向从机写积压空间中的数据,积压空间存储有「更新缓存」
psync_len = addReplyReplicationBacklog(c,psync_offset);
redisLog(REDIS_NOTICE,
"Partial resynchronization request accepted. Sending %lld bytes of "
"backlog starting from offset %lld.", psync_len, psync_offset);
/* Note that we don't need to set the selected DB at server.slaveseldb
* to -1 to force the master to emit SELECT, since the slave already
* has this state from the previous connection with the master. */
refreshGoodSlavesCount();
return REDIS_OK; /* The caller can return, no full resync needed. */
need_full_resync:
......
// 向从机发送+FULLRESYNC runid repl_offset
}缓存主机
从机因为某些原因,譬如网络延迟(PING 超时,ACK 超时等),可能会断开与主机的连接。这时候,从机会尝试保存与主机连接的信息,譬如全局积压空间数据偏移量等,以便下一次的部分同步,并且从机会再一次尝试连接主机。注意一点,如果断开的时间足够长,部分同步肯定会失败的。
void freeClient(redisClient *c) {
listNode *ln;
/* If this is marked as current client unset it */
if (server.current_client == c) server.current_client = NULL;
// 如果此机为从机,已经连接主机,可能需要保存主机状态信息,以便进行PSYNC
/* If it is our master that's beging disconnected we should make sure
* to cache the state to try a partial resynchronization later.
**
Note that before doing this we make sure that the client is not in
* some unexpected state, by checking its flags. */
if (server.master && c->flags & REDIS_MASTER) {
redisLog(REDIS_WARNING,"Connection with master lost.");
if (!(c->flags & (REDIS_CLOSE_AFTER_REPLY|
REDIS_CLOSE_ASAP|
REDIS_BLOCKED|
REDIS_UNBLOCKED)))
{
replicationCacheMaster(c);
return;
}
}
......
}
// 为了实现部分同步,从机会保存主机的状态信息后才会断开主机的连接,主机状态信息
// 保存在server.cached_master
// 会在freeClient() 中调用,保存与主机连接的状态信息,以便进行PSYNC
void replicationCacheMaster(redisClient *c) {
listNode *ln;
redisAssert(server.master != NULL && server.cached_master == NULL);
redisLog(REDIS_NOTICE,"Caching the disconnected master state.");
// 从客户端列表删除主机的信息
/* Remove from the list of clients, we don't want this client to be
* listed by CLIENT LIST or processed in any way by batch operations. */
ln = listSearchKey(server.clients,c);
redisAssert(ln != NULL);
listDelNode(server.clients,ln);
// 保存主机的状态信息
/* Save the master. Server.master will be set to null later by
* replicationHandleMasterDisconnection(). */
server.cached_master = server.master;
// 注销事件,关闭连接
/* Remove the event handlers and close the socket. We'll later reuse
* the socket of the new connection with the master during PSYNC. */
aeDeleteFileEvent(server.el,c->fd,AE_READABLE);
aeDeleteFileEvent(server.el,c->fd,AE_WRITABLE);
close(c->fd);
/* Set fd to -1 so that we can safely call freeClient(c) later. */
c->fd = -1;
// 修改连接的状态,设置server.master = NULL
/* Caching the master happens instead of the actual freeClient() call,
* so make sure to adjust the replication state. This function will
* also set server.master to NULL. */
replicationHandleMasterDisconnection();
}总结
简单来说,主从同步就是 RDB 文件的上传下载;主机有小部分的数据修改,就把修改记录传播给每个从机。这篇文章详述了 Redis 主从复制的内部协议和机制。