Redis 集群(下)
刚好 Redis 集群也 release 了,也顺带在这里展开一下。redis cluster 就是想要让一群的节点实现自治,有自我修复的功能,数据分片和负载均衡。
数据结构
基本上集群中的每一个节点都需要知道其他节点的情况,从而,如果网络中有五个节点就下面的图:
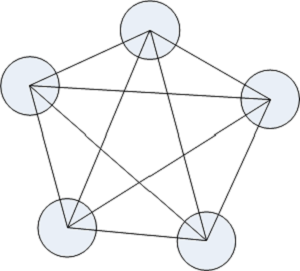
其中每条线都代表双向联通。特别的,如果 redis master 还配备了 replica,图画起来会稍微复杂一点。
redis cluster 中有几个比较重要的数据结构,一个用以描述节点 struct clusterNode,一个用以描述集群的状况 struct clusterState。
节点的信息包括:本身的一些属性,还有它的主从节点,心跳和主从复制信息,和与该节点的连接上下文。
typedef struct clusterNode {
mstime_t ctime; /* Node object creation time. */
char name[REDIS_CLUSTER_NAMELEN]; /* Node name, hex string, sha1-size */
int flags; /* REDIS_NODE_... */
uint64_t configEpoch; /* Last configEpoch observed for this node */
// 该节点会处理的slot
unsigned char slots[REDIS_CLUSTER_SLOTS/8]; /* slots handled by this node */
int numslots; /* Number of slots handled by this node */
// 从机信息
int numslaves; /* Number of slave nodes, if this is a master */
// 从机节点数组
struct clusterNode **slaves; /* pointers to slave nodes */
// 主机节点数组
struct clusterNode *slaveof; /* pointer to the master node */
// 一些有用的时间点
mstime_t ping_sent; /* Unix time we sent latest ping */
mstime_t pong_received; /* Unix time we received the pong */
mstime_t fail_time; /* Unix time when FAIL flag was set */
mstime_t voted_time; /* Last time we voted for a slave of this master */
mstime_t repl_offset_time; /* Unix time we received offset for this node */
long long repl_offset; /* Last known repl offset for this node. */
// 最近被记录的地址和端口
char ip[REDIS_IP_STR_LEN]; /* Latest known IP address of this node */
int port; /* Latest known port of this node */
// 与该节点的连接上下文
clusterLink *link; /* TCP/IP link with this node */
list *fail_reports; /* List of nodes signaling this as failing */
} clusterNode;
集群的状态包括下面的信息:
typedef struct clusterState {
clusterNode *myself; /* This node */
// 配置版本
uint64_t currentEpoch;
// 集群的状态
int state; /* REDIS_CLUSTER_OK, REDIS_CLUSTER_FAIL, ... */
// 存储所有节点的哈希表
int size; /* Num of master nodes with at least one slot */
dict *nodes; /* Hash table of name -> clusterNode structures */
// 黑名单节点,一段时间内不会再加入到集群中
dict *nodes_black_list; /* Nodes we don't re-add for a few seconds. */
// slot 数据正在迁移到migrating_slots_to[slot] 节点
clusterNode *migrating_slots_to[REDIS_CLUSTER_SLOTS];
// slot 数据正在从importing_slots_from[slot] 迁移到本机
clusterNode *importing_slots_from[REDIS_CLUSTER_SLOTS];
// slot 数据由slots[slot] 节点来处理
clusterNode *slots[REDIS_CLUSTER_SLOTS];
// slot 到key 的一个映射
zskiplist *slots_to_keys;
// 记录了故障修复的信息
/* The following fields are used to take the slave state on elections. */
mstime_t failover_auth_time; /* Time of previous or next election. */
int failover_auth_count; /* Number of votes received so far. */
int failover_auth_sent; /* True if we already asked for votes. */
int failover_auth_rank; /* This slave rank for current auth request. */
uint64_t failover_auth_epoch; /* Epoch of the current election. */
int cant_failover_reason; /* Why a slave is currently not able to
failover. See the CANT_FAILOVER_* macros. */
// 人工故障修复的一些信息
......
} clusterState;如上,在正常的 Redis 集群中的任何一个节点都能感知到其他节点。里面的细节有很多,就不一一解释了,当遇到的时候再有需要解释一下。
上面频繁出现 slot 单词。之前我们学哈希表的时候,可以把 slot 理解为哈希表中的桶(bucket)。为什么需要slot?这和 redis cluster 的数据分区和访问有关。建议大概看完 Redis 对数据结构后,接着看 clusterCommand() 这个函数,由此知道 redis cluster 能提供哪些服务和功能。接着往下看。
数据访问
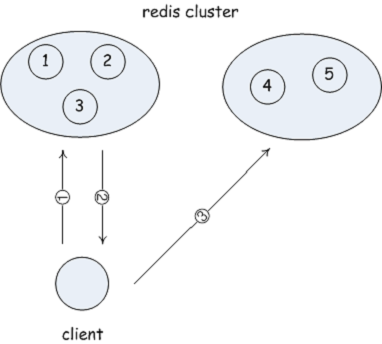
在 http 有 301 状态码:301 Moved Permanently,它表示用户所要访问的内容已经迁移到一个地址了,需要向新的地址发出请求。redis cluster 很明显也是这么做的。在前面讲到,redis cluster 中的每一个节点都需要知道其他节点的情况,这里就包括其他节点负责处理哪些键值对。
在主函数中,Redis 会检测在启用集群模式的情况下,会检测命令中指定的 key 是否该由自己来处理,如果不是的话,会返回一个类似于重定向的错误返回到客户端。而“是否由自己来处理”就是看 hash(key) 值是否落在自己所负责的 slot 中。
typedef struct clusterNode {
......
// 该节点会处理的slot
unsigned char slots[REDIS_CLUSTER_SLOTS/8]; /* slots handled by this node */
int numslots; /* Number of slots handled by this node */
......
} clusterNode;可能会有疑问:这样的数据访问机制在不是会浪费一个请求吗?确实,如果直接向集群中的节点盲目访问一个 key 的话,确实需要发起两个请求。为此,redis cluster 配备了 slot 表,用户通过 slots 命令先向集群请求这个 slot 表,得到这个表可以获取哪些节点负责哪些 slot,继而客户端可以访问再访问集群中的数据。这样,就可以在大多数的场景下节省一个请求,直达目标节点。当然,这个 slot 表是随时出现变更的,所以客户端不能够一 本万利一直使用这个 slot 表,可以实现一个定时器,超时后再向集群节点获取 slot 表。
你可以阅读 getNodeByQuery(),流程不难。
新的节点
Redis 刚刚启动时候会检测集群配置文件中是否有预配置好的节点,如果有的话,会添加到节点哈希表中,在适当的时候连接这个节点,并和它打招呼–握手。
// 加载集群配置文件
int clusterLoadConfig(char *filename) {
......
// 如果该节点不在哈希表中,会添加
/* Create this node if it does not exist */
n = clusterLookupNode(argv[0]);
if (!n) {
n = createClusterNode(argv[0],0);
clusterAddNode(n);
}
/* Address and port */
if ((p = strrchr(argv[1],':')) == NULL) goto fmterr;
*p = '\0';
memcpy(n->ip,argv[1],strlen(argv[1])+1);
n->port = atoi(p+1);
......
}注意,加载配置文件后,不会立即进入握手阶段。 另外两个新增节点的时机,当其他节点向该节点打招呼时候,该节点会记录下对端节点,以及对端所知悉的节点;Redis 管理人员告知,Redis 管理人员可以通过普通的 redis meet 命令,相当于是人工将某个节点加入到集群中。
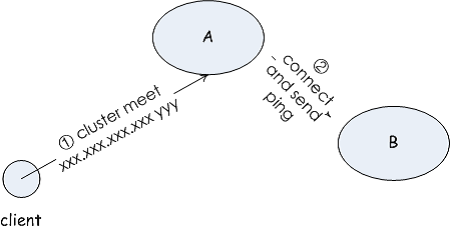
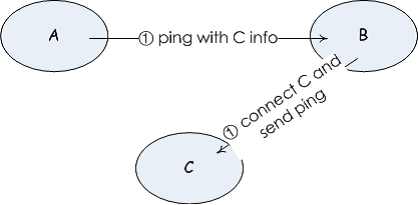
当和其他节点开始握手时,会调用 clusterStartHandshake(),它只会初始化握手的初始信息,并不会立刻向其他节点发起握手,:按照 Redis 的习惯是在集群定时处理函数 clusterCron() 中。
int clusterStartHandshake(char *ip, int port) {
clusterNode *n;
char norm_ip[REDIS_IP_STR_LEN];
struct sockaddr_storage sa;
// 分IPV4 和IPV6 两种情况
/* IP sanity check */
if (inet_pton(AF_INET,ip,
&(((struct sockaddr_in *)&sa)->sin_addr)))
{
sa.ss_family = AF_INET;
} else if (inet_pton(AF_INET6,ip,
&(((struct sockaddr_in6 *)&sa)->sin6_addr)))
{
sa.ss_family = AF_INET6;
} else {
errno = EINVAL;
return 0;
}
// 端口有效性检测
/* Port sanity check */
if (port <= 0 || port > (65535-REDIS_CLUSTER_PORT_INCR)) {
errno = EINVAL;
return 0;
}
// 标准化ip
/* Set norm_ip as the normalized string representation of the node
* IP address. */
memset(norm_ip,0,REDIS_IP_STR_LEN);
if (sa.ss_family == AF_INET)
inet_ntop(AF_INET,
(void*)&(((struct sockaddr_in *)&sa)->sin_addr),
norm_ip,REDIS_IP_STR_LEN);
else
inet_ntop(AF_INET6,
(void*)&(((struct sockaddr_in6 *)&sa)->sin6_addr),
norm_ip,REDIS_IP_STR_LEN);
// 如果这个节点正在握手状态,则不需要重复进入,直接退出
if (clusterHandshakeInProgress(norm_ip,port)) {
errno = EAGAIN;
return 0;
}
// 创建一个新的节点,并加入到节点哈希表中
/* Add the node with a random address (NULL as first argument to
* createClusterNode()). Everything will be fixed during the
* handshake. */
n = createClusterNode(NULL,REDIS_NODE_HANDSHAKE|REDIS_NODE_MEET);
memcpy(n->ip,norm_ip,sizeof(n->ip));
n->port = port;
clusterAddNode(n);
return 1;
}其他节点收到后在 clusterProcessGossipSection() 中将新的节点添加到哈希表中。
心跳机制
还是那句话,redis cluster 中的每一个节点都需要知道其他节点的情况。要达到这个目标,必须有一个心跳机制来保持每个节点是可达的,监控的,并且节点的信息变更,也可以通过心跳中的数据包来传递。这样就很容易理解Redis 的心跳机制是怎么实现的。这有点类似于主从复制中的实现方法,总之就是一个心跳。在 redis cluster 只,这种心跳又叫 gossip 机制。
集群之间交互信息是用其内部专用连接的。redis cluster 中的每一个节点都监听了一个集群专用的端口,专门用作集群节点之间的信息交换。在 redis cluster 初始化函数 clusterInit() 中监听了该端口,并在事件中心注册了 clusterAcceptHandler()。 从 clusterAcceptHandler()的逻辑来看,当有新的连接到来时,会为新的连接注册 clusterReadHandler()回调函数。这一点和 redis 本身初始化的行为是一致的。
clusterSendPing() 中发送心跳数据。发送的包括:所知节点的名称,ip 地址等。这样,改节点就将主机所知的信息传播到了其他的节点。注意,从 clusterSendPing() 的实现来看,redis cluster 并不是一开始就向所有的节点发送心跳数据,而选取几个节点发送,因为 redis 考虑到集群网的形成并不需要每个节点向像集群中的所有其他节点发送 ping。
故障修复
故障修复曾经在主从复制中提到过。redis cluster 的故障修复分两种途径,一种是集群自治实现的故障修复,一种是人工触发的故障修复。
集群自治实现的故障修复中,是由从机发起的。上面所说,集群中的每个节点都需要和其他节点保持连接。从机如果检测到主机节点出错了(标记为 REDIS_NODE_FAIL),会尝试进行主从切换。在 cluster 定时处理函数中,有一段只有从机才会执行的代码段:
// 集群定时处理函数
/* This is executed 10 times every second */
void clusterCron(void) {
......
// 从机才需要执行下面的逻辑
if (nodeIsSlave(myself)) {
......
// 从机-> 主机替换
clusterHandleSlaveFailover();
......
}
......
}从机的 clusterCron() 会调用 clusterHandleSlaveFailover() 已决定是否需要执行故障修复。通常,故障修复的触发点就是在其主机被标记为出错节点的时候。
故障修复的协议
在决定故障修复后,会开始进行协商是否可以将自己升级为主机。
// 主机已经是一个出错节点了,自己作为从机可以升级为主机
void clusterHandleSlaveFailover(void) {
......
// 故障修复超时,重新启动故障修复
if (auth_age > auth_retry_time) { // 两次故障修复间隔不能过短
// 更新一些时间
......
redisLog(REDIS_WARNING,
"Start of election delayed for %lld milliseconds "
"(rank #%d, offset %lld).",
server.cluster->failover_auth_time - mstime(),
server.cluster->failover_auth_rank,
replicationGetSlaveOffset());
// 告知其他从机
/* Now that we have a scheduled election, broadcast our offset
* to all the other slaves so that they'll updated their offsets
* if our offset is better. */
clusterBroadcastPong(CLUSTER_BROADCAST_LOCAL_SLAVES);
return;
}
......
// 开头投票
/* Ask for votes if needed. */
if (server.cluster->failover_auth_sent == 0) {
server.cluster->currentEpoch++;
server.cluster->failover_auth_epoch = server.cluster->currentEpoch;
redisLog(REDIS_WARNING,"Starting a failover election for epoch %llu.",
(unsigned long long) server.cluster->currentEpoch);
clusterRequestFailoverAuth();
server.cluster->failover_auth_sent = 1;
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|
CLUSTER_TODO_UPDATE_STATE|
CLUSTER_TODO_FSYNC_CONFIG);
return; /* Wait for replies. */
}
}上面有两个关键的函数:clusterBroadcastPong() 和clusterRequestFailoverAuth()。
在 clusterBroadcastPong()中,会向其他属于同一主从关系的其他从机发送 pong,以传递主机已经出错的信息。
clusterRequestFailoverAuth() 中,会向集群中的所有其他节点发送 CLUSTERMSG_-TYPE_FAILOVER_AUTH_REQUEST 信令,意即询问是否投票。
那收到这个信令的节点,是否会向源节点投票呢?先来看看 FAILOVERAUTH-REQUEST 信令中带有什么数据,顺着 clusterRequestFailoverAuth() 下去,会找到 cluster-BuildMessageHdr() 函数,它打包了一些数据。这里主要包括:
- RCmb 四个字符,相当于是 redis cluster 信令的头部校验值,
- type,命令号,这是属于什么信令
- sender info,发送信令节点的信息
- 发送信令节点的配置版本号
- 主从复制偏移量

在心跳机制那一节讲过,集群节点会为与其他节点的连接注册clusterReadHandler() 回调函数,FAILOVER_AUTH_REQUEST 信令的处理也在里面,对应的是 clusterSendFailover-AuthIfNeeded() 处理函数,在这里决定是否投对端节点一票。这里的决定因素有几个:配置版本号,节点本身和投票时间。
1.如果需要投票,索取投票的节点当前版本号必须比当前记录的版本一样,这样才有权索取投票;新的版本号必须是最新的。第二点,可能比较绕,譬如下面的场景,slave 是无法获得其他主机的投票的,other slave 才可以。这里的意思是,如果一个从机想要升级为主机,它与它的主机必须保持状态一致。
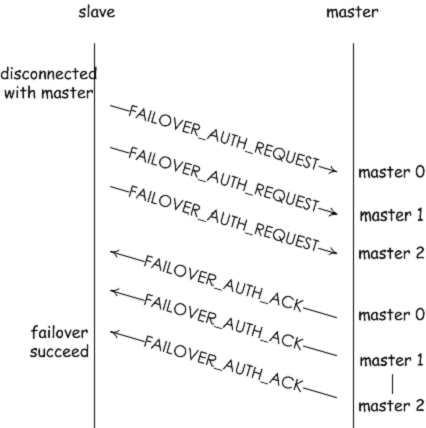
2.索取投票的节点必须是从机节点。这是当然,因为故障修复是由从机发起的
3.最后一个是投票的时间,因为当一个主机有多个从机的时候,多个从机都会发起故障修复,一段时间内只有一个从机会进行故障修复,其他的会被推迟。
这三点都在 clusterSendFailoverAuthIfNeeded() 中都有所体现。
当都满足了上述要求过后,即可开始投票:
// 决定是否投票,redis cluster 将根据配置的版本号决定是否投票
/* Vote for the node asking for our vote if there are the conditions. */
void clusterSendFailoverAuthIfNeeded(clusterNode *node, clusterMsg *request) {
......
// 投票走起
/* We can vote for this slave. */
clusterSendFailoverAuth(node);
server.cluster->lastVoteEpoch = server.cluster->currentEpoch;
node->slaveof->voted_time = mstime(); // 更新投票的时间
redisLog(REDIS_WARNING, "Failover auth granted to %.40s for epoch %llu",
node->name, (unsigned long long) server.cluster->currentEpoch);
}投票函数 lusterSendFailoverAuth() 只是放一个 CLUSTERMSG_TYPEFAILOVER-AUTH_ACK 信令到达索取投票的从机节点,从而该从机获取了一票。让我们再回到索取投票的从机节点接下来会怎么做。
// 主机已经是一个出错节点了,自己作为从机可以升级为主机
void clusterHandleSlaveFailover(void) {
......
// 获得的选票必须是集群节点数的一般以上
/* Check if we reached the quorum. */
if (server.cluster->failover_auth_count >= needed_quorum) {
/* We have the quorum, we can finally failover the master. */
redisLog(REDIS_WARNING,
"Failover election won: I'm the new master.");
/* Update my configEpoch to the epoch of the election. */
if (myself->configEpoch < server.cluster->failover_auth_epoch) {
myself->configEpoch = server.cluster->failover_auth_epoch;
redisLog(REDIS_WARNING,
"configEpoch set to %llu after successful failover",
(unsigned long long) myself->configEpoch);
}
// 正式转换为主机,代替主机的功能
/* Take responsability for the cluster slots. */
clusterFailoverReplaceYourMaster();
} else {
clusterLogCantFailover(REDIS_CLUSTER_CANT_FAILOVER_WAITING_VOTES);
}
}从机在获取集群节点数量半数以上的投票时,就可以正式升级为主机了。来回顾一下投票的全过程:

clusterFailoverReplaceYourMaster() 就是将其自身的配置从从机更新到主机,最后广播给所有的节点:我转正了。实际上,是发送一个 pong。
redis cluster 还提供了一种人工故障修复的模式,管理人员可以按需使用这些功能。你可以从 clusterCommand() 下找到人工故障修复流程开始执行的地方:
1.cluster failover takeover. 会强制将从机升级为主机,不需要一个投票的过程。
2.cluster failover force. 会强制启用故障修复,这和上面讲的故障修复过程一样。如果你留意 clusterHandleSlaveFailover() 中的处理逻辑的话,实际 cluster force 也是在其中处理的,同样需要一个投票的过程。
3.cluster failover. 默认的模式,会先告知主机需要开始进行故障修复流程,主机被告知会停止服务。之后再走接下来的主从修复的流程。
// cluster 命令处理。
void clusterCommand(redisClient *c) {
......
// 启动故障修复
} else if (!strcasecmp(c->argv[1]->ptr,"failover") &&
(c->argc == 2 || c->argc == 3))
{
......
if (takeover) {
......
// 产生一个新的配置版本号
clusterBumpConfigEpochWithoutConsensus();
// 直接将自己升级为主机,接着通知到所有的节点
clusterFailoverReplaceYourMaster();
} else if (force) {
......
// 直接标记为可以开始进行故障修复了,并不用告知主机
server.cluster->mf_can_start = 1;
} else {
// 先通知我的主机开始人工故障修复,再执行接下来的故障修复流程
clusterSendMFStart(myself->slaveof);
}
addReply(c,shared.ok);
}
......
}4.发送信令节点的配置版本号
5.主从复制偏移量
人工故障修复模式,和自治实现的故障修复模式最大的区别在于对于从机来说,其主机是否可达。人工故障修复模式,允许主机可达的情况下,实现故障修复。因此,相比自治的故障修复,人工的还会多一道工序:主从复制的偏移量相等过后,才开始进行故障修复的过程。
从下面两种模式的处理来看,有很明显的区别:
// cluster 命令处理
void clusterCommand(redisClient *c) {
......
// 启动故障修复
} else if (!strcasecmp(c->argv[1]->ptr,"failover") &&
(c->argc == 2 || c->argc == 3))
{
......
if (takeover) {
......
// 产生一个新的配置版本号
clusterBumpConfigEpochWithoutConsensus();
// 直接将自己升级为主机,接着通知到所有的节点
clusterFailoverReplaceYourMaster();
} else if (force) {
......
// 直接标记为可以开始进行故障修复了,并不用告知主机
server.cluster->mf_can_start = 1;
} else {
// 先通知我的主机开始人工故障修复,再执行接下来的故障修复流程
clusterSendMFStart(myself->slaveof);
}
addReply(c,shared.ok);
}
}- takeover 模式直接将自己升级为主机
- force 模式直接进入故障修复模式
- 默认模式会先告知(clusterSendMFStart())主机,接着再进行故障修复流程
来看看人工故障修复模式的状态机 clusterHandleManualFailover(),这个函数只会在 clusterCron() 中调用:
// 人工恢复状态机, 只在clusterCron() 中调用
void clusterHandleManualFailover(void) {
/* Return ASAP if no manual failover is in progress. */
if (server.cluster->mf_end == 0) return;
/* If mf_can_start is non-zero, the failover was already triggered so the
* next steps are performed by clusterHandleSlaveFailover(). */
if (server.cluster->mf_can_start) return;
if (server.cluster->mf_master_offset == 0) return; /* Wait for offset... */
if (server.cluster->mf_master_offset == replicationGetSlaveOffset()) {
/* Our replication offset matches the master replication offset
* announced after clients were paused. We can start the failover. */
server.cluster->mf_can_start = 1;
redisLog(REDIS_WARNING,
"All master replication stream processed, "
"manual failover can start.");
}
}主要的几个变量这里解说一下:
- mf_end:在触发人工故障修复的时候就会被设置
- mf_master_offset:从机需要等待主机发送主从复制偏移量,如上所说,从机升级为 主机,需要和主机的偏移量相等
- mf_can_start:主从机偏移量相等时,就可以进行故障修复了
自治故障修复和人工故障修复流程都是在 clusterHandleSlaveFailover() 中开始执行的。这里不再复述。
这里大概总结一下人工故障修复默认模式的流程:

数据迁移
在之前有讲过 migrate 系列的命令,即数据迁移。在 redis cluster 中,搬迁 slot 的时候,就会用到 migrate 系列的命令。
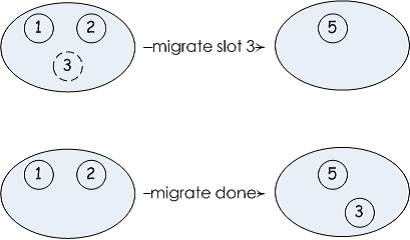
为了管理连接,redis cluster 还实现了长连接的管理,你可以在 migrateGetSocket() 中查看它的实现。
在集群状态结构体中存储了两个与数据迁移的数据:
typedef struct clusterState {
......
// slot 数据正在迁移到migrating_slots_to[slot] 节点
clusterNode *migrating_slots_to[REDIS_CLUSTER_SLOTS];
// slot 数据正在从importing_slots_from[slot] 迁移到本机
clusterNode *importing_slots_from[REDIS_CLUSTER_SLOTS];
......
} clusterState;这些信息在数据访问的时候会有用。
总结
这篇文章依据笔者感兴趣的几个问题分了几个大的部分介绍 redis cluster,一些小的细节大家可以在源码中寻找答案。