Redis 哨兵机制
Redis 哨兵的服务框架
哨兵也是 Redis 服务器,只是它与我们平时提到的 Redis 服务器职能不同,哨兵负责监视普通的 Redis 服务器,提高一个服务器集群的健壮和可靠性。哨兵和普通的 Redis 服务器所用的是同一套服务器框架,这包括:网络框架,底层数据结构,订阅发布机制等。
从主函数开始,来看看哨兵服务器是怎么诞生,它在什么时候和普通的 Redis 服务器分道扬镳:
int main(int argc, char **argv) {
// 随机种子,一般rand() 产生随机数的函数会用到
srand(time(NULL)^getpid());
gettimeofday(&tv,NULL);
dictSetHashFunctionSeed(tv.tv_sec^tv.tv_usec^getpid());
// 通过命令行参数确认是否启动哨兵模式
server.sentinel_mode = checkForSentinelMode(argc,argv);
// 初始化服务器配置,主要是填充redisServer 结构体中的各种参数
initServerConfig();
// 将服务器配置为哨兵模式,与普通的redis 服务器不同
/* We need to init sentinel right now as parsing the configuration file
* in sentinel mode will have the effect of populating the sentinel
* data structures with master nodes to monitor. */
if (server.sentinel_mode) {
// initSentinelConfig() 只指定哨兵服务器的端口
initSentinelConfig();
initSentinel();
}
......
// 普通redis 服务器模式
if (!server.sentinel_mode) {
......
// 哨兵服务器模式
} else {
// 检测哨兵模式是否正常配置
sentinelIsRunning();
}
......
// 进入事件循环
aeMain(server.el);
// 去除事件循环系统
aeDeleteEventLoop(server.el);
return 0;
}在上面,通过判断命令行参数来判断 Redis 服务器是否启用哨兵模式,会设置服务器参数结构体中的redisServer.sentinel_mode 的值。在上面的主函数调用了一个很关键的函数:initSentinel(),它完成了哨兵服务器特有的初始化程序,包括填充哨兵服务器特有的命令表,struct sentinel 结构体。
// 哨兵服务器特有的初始化程序
/* Perform the Sentinel mode initialization. */
void initSentinel(void) {
int j;
// 如果 redis 服务器是哨兵模式,则清空命令列表。哨兵会有一套专门的命令列表,
// 这与普通的 redis 服务器不同
/* Remove usual Redis commands from the command table, then just add
* the SENTINEL command. */
dictEmpty(server.commands,NULL);
// 将sentinelcmds 命令列表中的命令填充到server.commands
for (j = 0; j < sizeof(sentinelcmds)/sizeof(sentinelcmds[0]); j++) {
int retval;
struct redisCommand *cmd = sentinelcmds+j;
retval = dictAdd(server.commands, sdsnew(cmd->name), cmd);
redisAssert(retval == DICT_OK);
}
/* Initialize various data structures. */
// sentinel.current_epoch 用以指定版本
sentinel.current_epoch = 0;
// 哨兵监视的 redis 服务器哈希表
sentinel.masters = dictCreate(&instancesDictType,NULL);
// sentinel.tilt 用以处理系统时间出错的情况
sentinel.tilt = 0;
// TILT 模式开始的时间
sentinel.tilt_start_time = 0;
// sentinel.previous_time 是哨兵服务器上一次执行定时程序的时间
sentinel.previous_time = mstime();
// 哨兵服务器当前正在执行的脚本数量
sentinel.running_scripts = 0;
// 脚本队列
sentinel.scripts_queue = listCreate();
}我们查看 struct redisCommand sentinelcmds 这个全局变量就会发现,它里面只有七个命令,难道哨兵仅仅提供了这种服务?为了能让哨兵自动管理普通的 Redis 服务器,哨兵还添加了一个定时程序,我们从 serverCron() 定时程序中就会发现,哨兵的定时程序被调用执行了,这里包含了哨兵的主要工作:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
......
run_with_period(100) {
if (server.sentinel_mode) sentinelTimer();
}
}定时程序
定时程序是哨兵服务器的重要角色,所做的工作主要包括:监视普通的 Redis 服务器(包括主机和从机),执行故障修复,执行脚本命令。
// 哨兵定时程序
void sentinelTimer(void) {
// 检测是否需要启动sentinel TILT 模式
sentinelCheckTiltCondition();
// 对哈希表中的每个服务器实例执行调度任务,这个函数很重要
sentinelHandleDictOfRedisInstances(sentinel.masters);
// 执行脚本命令,如果正在执行脚本的数量没有超出限定
sentinelRunPendingScripts();
// 清理已经执行完脚本的进程,如果执行成功从脚本队列中删除脚本
sentinelCollectTerminatedScripts();
// 停止执行时间超时的脚本进程
sentinelKillTimedoutScripts();
// 为了防止多个哨兵同时选举,故意错开定时程序执行的时间。通过调整周期可以
// 调整哨兵定时程序执行的时间,即默认值REDIS_DEFAULT_HZ 加上一个任意值
server.hz = REDIS_DEFAULT_HZ + rand() % REDIS_DEFAULT_HZ;
}哨兵与 Redis 服务器的互联
每个哨兵都有一个 struct sentinel 结构体,里面维护了多个主机的连接,与每个主机连接的相关信息都存储在 struct sentinelRedisInstance。透过这两个结构体,很快就可以描绘出,一个哨兵服务器所维护的机器的信息:
typedef struct sentinelRedisInstance {
......
/* Master specific. */
// 其他正在监视此主机的哨兵
dict *sentinels; /* Other sentinels monitoring the same master. */
// 次主机的从机列表
dict *slaves; /* Slaves for this master instance. */
......
// 如果是从机,master 则指向它的主机
struct sentinelRedisInstance *master; /* Master instance if it's slave. */
......
} sentinelRedisInstance;哨兵服务器所能描述的 Redis 信息:
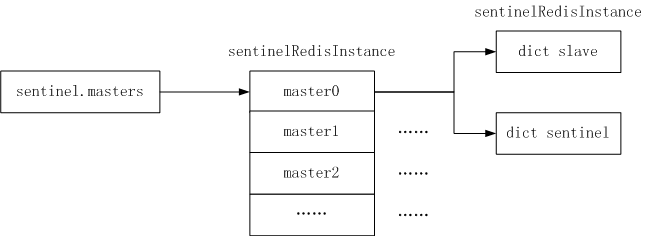
可见,哨兵服务器连接(监视)了多台主机,多台从机和多台哨兵服务器。有这样大概的脉络,我们继续往下看就会更有线索。
哨兵要监视 Redis 服务器,就必须连接 Redis 服务器。启动哨兵的时候需要指定一个配置文件,程序初始化的时候会读取这个配置文件,获取被监视 Redis 服务器的 IP 地址和端口等信息。
redis-server /path/to/sentinel.conf --sentinel
或者
redis-sentinel /path/to/sentinel.conf
如果想要监视一个 Redis 服务器,可以在配置文件中写入:
sentinel monitor <master-name> <ip> <redis-port> <quorum>
其中,master-name 是主机名,ip redis-port 分别是 IP 地址和端口,quorum 是哨兵用来判断某个 Redis 服务器是否下线的参数,之后会讲到。sentinelHandleConfiguration() 函数中,完成了对配置文件的解析和处理过程。
// 哨兵配置文件解析和处理
char *sentinelHandleConfiguration(char **argv, int argc) {
sentinelRedisInstance *ri;
if (!strcasecmp(argv[0],"monitor") && argc == 5) {
/* monitor <name> <host> <port> <quorum> */
int quorum = atoi(argv[4]);
// quorum >= 0
if (quorum <= 0) return "Quorum must be 1 or greater.";
if (createSentinelRedisInstance(argv[1],SRI_MASTER,argv[2],
atoi(argv[3]),quorum,NULL) == NULL)
{
switch(errno) {
case EBUSY: return "Duplicated master name.";
case ENOENT: return "Can't resolve master instance hostname.";
case EINVAL: return "Invalid port number";
}
}
......
}可以看到里面主要调用了 createSentinelRedisInstance() 函数。createSentinelRedisInstance() 函数的主要工作是初始化 sentinelRedisInstance 结构体。在这里,哨兵并没有选择立即去连接这指定的 Redis 服务器,而是将 sentinelRedisInstance.flag 标记 SRI_DISCONNECT,而将连接的工作丢到定时程序中去,可以联想到,定时程序中肯定有一个检测 sentinelRedisInstance.flag 的函数,如果发现连接是断开的,会发起连接。这个策略和我们之前的讲到的主从连接时候的策略是一样的,是 Redis 的惯用手法。因为哨兵要和 Redis 服务器保持连接,所以必然会定时检测和 Redis 服务器的连接状态。
在定时程序的调用链中,确实发现了哨兵主动连接 Redis 服务器的过程:
sentinelTimer()->sentinelHandleRedisInstance()->sentinelReconnectInstance()。
sentinelReconnectInstance() 负责连接被标记为 SRI_DISCONNECT 的 Redis 服务器。它对一个 Redis 服务器发起了两个连接:
- 普通连接(sentinelRedisInstance.cc,Commands connection)
- 订阅发布专用连接(sentinelRedisInstance.pc,publish connection)。为什么需要分这两个连接呢?因为对于一个客户端连接来说,redis 服务器要么专门处理普通的命令,要么专门处理订阅发布命令,这在之前订阅发布篇幅中专门有提及这个细节。
void sentinelReconnectInstance(sentinelRedisInstance *ri) {
if (!(ri->flags & SRI_DISCONNECTED)) return;
/* Commands connection. */
if (ri->cc == NULL) {
ri->cc = redisAsyncConnect(ri->addr->ip,ri->addr->port);
// 连接出错
if (ri->cc->err) {
// 错误处理
} else {
// 此连接被绑定到redis 服务器的事件中心
......
}
}
// 此哨兵会订阅所有主从机的hello 订阅频道,每个哨兵都会定期将自己监视的
// 服务器和自己的信息发送到主从服务器的hello 频道,从而此哨兵就能发现其
// 他服务器,并且也能将自己的监测的数据散播到其他服务器。这就是redis 所
// 谓的auto discover.
/* Pub / Sub */
if ((ri->flags & (SRI_MASTER|SRI_SLAVE)) && ri->pc == NULL) {
ri->pc = redisAsyncConnect(ri->addr->ip,ri->addr->port);
// 连接出错
if (ri->pc->err) {
// 错误处理
} else {
// 此连接被绑定到redis 服务器的事件中心
......
// 订阅了ri 上的__sentinel__:hello 频道
/* Now we subscribe to the Sentinels "Hello" channel. */
retval = redisAsyncCommand(ri->pc,
sentinelReceiveHelloMessages, NULL, "SUBSCRIBE %s",
SENTINEL_HELLO_CHANNEL);
......
}
}Redis 在定时程序中会尝试对所有的 master 作重连接。这里会有一个疑问,之前有提到从机(slave),哨兵又是在什么时候连接了从机和哨兵呢?
HELLO 命令
我们从上面 sentinelReconnectInstance() 的源码得知,哨兵对于一个 Redis 服务器管理了两个连接:普通命令连接和订阅发布专用连接。其中,哨兵在初始化订阅发布连接的时候,做了两个工作:一是,向 Redis 服务器发送 SUBSCRIBE SENTINEL_HELLO_CHANNEL命令;二是,注册了回调函数 sentinelReceiveHelloMessages()。稍稍理解大概可以画出下面的数据流向图:
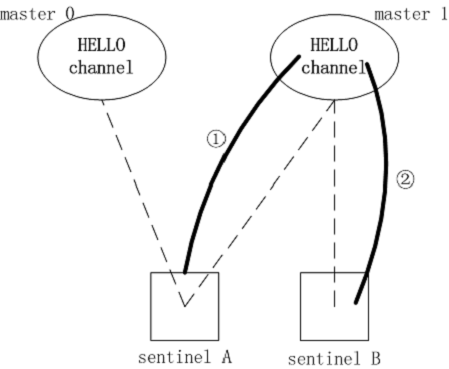
从源码来看,哨兵 A 向 master 1 的 HELLO 频道发布的数据有:哨兵 A 的 IP 地址,端口,runid,当前配置版本,以及 master 1 的 IP,端口,当前配置版本。从上图可以看出,其他所有监视同一 Redis 服务器的哨兵都能收到一份 HELLO 数据,这是订阅发布相关的内容。
在定时程序的调用链:sentinelTimer()->sentinelHandleRedisInstance()->sentinelPingInstance() 中,哨兵会向 Redis 服务器的 hello 频道发布数据。在 sentinel.c 文件中找到向 hello 频道发布数据的函数:
int sentinelSendHello(sentinelRedisInstance *ri) {
// ri 可以是一个主机,从机。
// 只是用主机和从机作为一个中转,主从机收到publish 命令后会将数据传输给
// 订阅了hello 频道的哨兵。这里可能会有疑问,为什么不直接发给哨兵???
char ip[REDIS_IP_STR_LEN];
char payload[REDIS_IP_STR_LEN+1024];
int retval;
sentinelRedisInstance *master = (ri->flags & SRI_MASTER) ? ri : ri->master;
sentinelAddr *master_addr = sentinelGetCurrentMasterAddress(master);
/* Try to obtain our own IP address. */
if (anetSockName(ri->cc->c.fd,ip,sizeof(ip),NULL) == -1) return REDIS_ERR;
if (ri->flags & SRI_DISCONNECTED) return REDIS_ERR;
// 格式化需要发送的数据,包括:
// 哨兵IP 地址,端口,runnid,当前配置版本,
// 主机IP 地址,端口,当前配置的版本
/* Format and send the Hello message. */
snprintf(payload,sizeof(payload),
"%s,%d,%s,%llu," /* Info about this sentinel. */
"%s,%s,%d,%llu", /* Info about current master. */
ip, server.port, server.runid,
(unsigned long long) sentinel.current_epoch,
/* --- */
master->name,master_addr->ip,master_addr->port,
(unsigned long long) master->config_epoch);
retval = redisAsyncCommand(ri->cc,
sentinelPublishReplyCallback, NULL, "PUBLISH %s %s",
SENTINEL_HELLO_CHANNEL,payload);
if (retval != REDIS_OK) return REDIS_ERR;
ri->pending_commands++;
return REDIS_OK;
}redisAsync 系列的函数底层也是《Redis 事件驱动详解》中的内容。
当 Redis 服务器收到来自哨兵的数据时候,会向所有订阅 hello 频道的哨兵发布数据,由此刚才注册的回调函数sentinelReceiveHelloMessages() 就被调用了。回调函数 sentinelReceiveHelloMessages() 做了两件事情:
- 发现其他监视同一 Redis 服务器的哨兵
- 更新配置版本,当其他哨兵传递的配置版本更高的时候,会更新 Redis 主服务器配置(IP 地址和端口)
总结一下这里的工作原理,哨兵会向 hello 频道发送包括:哨兵自己的IP 地址和端口,runid,当前的配置版本;其所监视主机的 IP 地址,端口,当前的配置版本。【这里要说清楚,什么是 runid 和配置版本】虽然未知的信息很多,但我们可以得知,当一个哨兵新加入到一个 Redis 集群中时,就能通过 hello 频道,发现其他更多的哨兵,而它自己也能够被其他的哨兵发现。这是 Redis 所谓 auto discover 的一部分。
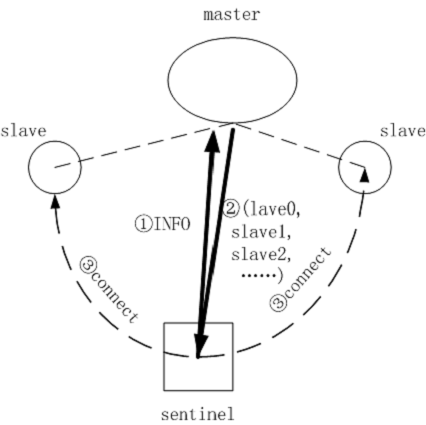
INFO 命令
同样,在定时程序的调用链:sentinelTimer()->sentinelHandleRedisInstance()->sentinelPingInstance() 中,哨兵向与 Redis 服务器的命令连接通道上,发送了一个INFO 命令(字符串);并注册了回调函数sentinelInfoReplyCallback()。Redis 服务器需要对 INFO 命令作出相应,能在 redis.c 主文件中找到 INFO 命令的处理函数:当 Redis 服务器收到INFO命令时候,会向该哨兵回传数据,包括:
关于该 Redis 服务器的细节信息,rRedis 软件版本,与其所连接的客户端信息,内存占用情况,数据落地(持久化)情况,各种各样的状态,主从复制信息,所有从机的信息,CPU 使用情况,存储的键值对数量等。
由此得到最值得关注的信息,所有从机的信息都在这个时候曝光给了哨兵,哨兵由此就可以监视此从机了。
Redis 服务器收集了这些信息回传给了哨兵,刚才所说哨兵的回调函数 sentinelInfoReplyCallback()会被调用,它的主要工作就是着手监视未被监视的从机;完成一些故障修复(failover)的工作。连同上面的一节,就是Redis 的 auto discover 的全貌了。
心跳
心跳是一种判断两台机器连接是否正常非常常用的手段,接收方在收到心跳包之后,会更新收到心跳的时间,在某个时间点如果检测到心跳包过久未收到(即超时),这证明网络环境不好,或者对方很忙,也为接收方接下来的行动提供指导:接收方可以等待心跳正常的时候再发送数据。在哨兵的定时程序中,哨兵会向所有的服务器,包括哨兵服务器,发送 PING 心跳,而哨兵收到来自 Redis 服务器的回应后,也会更新相应的时间点或者执行其他操作。

在线状态监测
哨兵有两种判断用户在线的方法,主观和客观方法,即 Check Subjectively Down 和 Check Objective Down。主观是说,Redis 服务器的在线判断依据是某个哨兵自己的信息;客观是说,Redis 服务器的在线判断依据是由其他监视此 Redis 服务器的哨兵的信息。
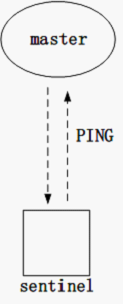
哨兵凭借的自己的信息判断 Redis 服务器是否下线的方法,称为主观方法,即通过判断前面有提到的 PING 心跳等其他通信时间是否超时来判断主机是否下线。主观的信息有可能是错的。
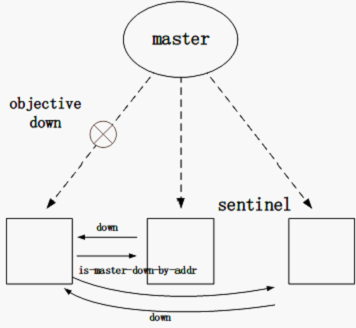
哨兵不仅仅凭借自己的信息,还依据其他哨兵提供的信息判断 Redis 服务器是否下线的方法称为客观方法,即通过所有其他哨兵报告的主机在线状态来判定某主机是否下线。前面提到,INFO 命令可以从其他哨兵服务器上获取信息,而这里面的信息就包含了他们共同关注主机的在线状态。客观判断方法是基于主观判断方法的,即如果一个 Redis 服务器被客观判定为下线,那么其早已被主观判断为下线了。因此客观判断的在线状态较有说服力,譬如在故障修复中就用到客观判断的结果。
void sentinelCheckObjectivelyDown(sentinelRedisInstance *master) {
dictIterator *di;
dictEntry *de;
int quorum = 0, odown = 0;
// 足够多的哨兵报告主机下线了,则设置Objectively down 标记
if (master->flags & SRI_S_DOWN) { // 此哨兵本身认为redis 服务器下线了
/* Is down for enough sentinels? */
quorum = 1; /* the current sentinel. */
/* Count all the other sentinels. */
// 查看其它哨兵报告的状况
di = dictGetIterator(master->sentinels);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *ri = dictGetVal(de);
if (ri->flags & SRI_MASTER_DOWN) quorum++;
}
dictReleaseIterator(di);
// 足够多的哨兵报告主机下线了,设置标记
if (quorum >= master->quorum) odown = 1;
}
/* Set the flag accordingly to the outcome. */
if (odown) {
// 写日志,设置SRI_O_DOWN
if ((master->flags & SRI_O_DOWN) == 0) {
sentinelEvent(REDIS_WARNING,"+odown",master,"%@ #quorum %d/%d",
quorum, master->quorum);
master->flags |= SRI_O_DOWN;
master->o_down_since_time = mstime();
}
} else {
// 写日志,取消SRI_O_DOWN
if (master->flags & SRI_O_DOWN) {
sentinelEvent(REDIS_WARNING,"-odown",master,"%@");
master->flags &= ~SRI_O_DOWN;
}
}
}故障修复
一个 Redis 集群难免遇到主机宕机断电的时候,哨兵如果检测主机被大多数的哨兵判定为下线,就很可能会执行故障修复,重新选出一个主机。一般在 Redis 服务器集群中,只有主机同时肩负读请求和写请求的两个功能,而从机只负责读请求,从机的数据更新都是由之前所提到的主从复制上获取的。因此,当出现意外情况的时候,很有必要新选出一个新的主机。

一般在 Redis 服务器集群中,只有主机同时肩负读请求和写请求的两个功能,而从机只负责读请求依然是在定时程序的调用链中, 我们能找到故障修复(failover) 诞生的地方:
sentinelTimer()->sentinelHandleRedisInstance()->sentinelStartFailoverIfNeeded()。
sentinelStartFailoverIfNeeded() 函数判断是否有必要进行故障修复,这里有三个条件:
- Redis 主机必须已经被客观判定为下线了
- 针对 Redis 主机的故障修复尚未开始
- 限定时间内,不能多次执行故障修复
三个条件都得到满足,故障修复就开始了。
继续往下走:sentinelTimer()->sentinelHandleRedisInstance()->sentinelStartFailoverIfNeeded()->sentinelStartFailover()。sentinelStartFailover() 设置了一些故障修复相关的标记等数据。故障修复分成了几个步骤完成,每个步骤对应一个状态。
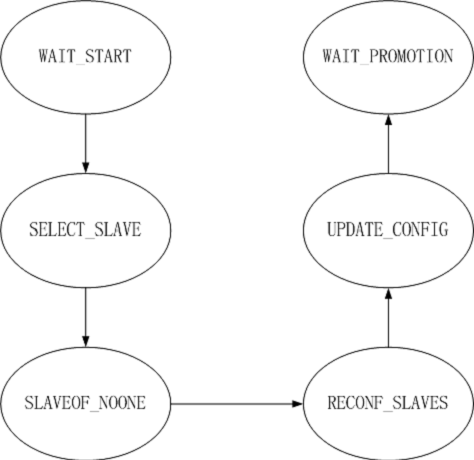
故障修复状态图
哨兵专门有一个故障修复状态机,
// 故障修复状态机,依据被标记的状态执行相应的动作
void sentinelFailoverStateMachine(sentinelRedisInstance *ri) {
redisAssert(ri->flags & SRI_MASTER);
if (!(ri->flags & SRI_FAILOVER_IN_PROGRESS)) return;
switch(ri->failover_state) {
case SENTINEL_FAILOVER_STATE_WAIT_START:
sentinelFailoverWaitStart(ri);
break;
case SENTINEL_FAILOVER_STATE_SELECT_SLAVE:
sentinelFailoverSelectSlave(ri);
break;
case SENTINEL_FAILOVER_STATE_SEND_SLAVEOF_NOONE:
sentinelFailoverSendSlaveOfNoOne(ri);
break;
case SENTINEL_FAILOVER_STATE_WAIT_PROMOTION:
sentinelFailoverWaitPromotion(ri);
break;
case SENTINEL_FAILOVER_STATE_RECONF_SLAVES:
sentinelFailoverReconfNextSlave(ri);
break;
}
}WAIT_START
在哨兵服务器群中,有首领(leader)的概念,这个首领可以是系统管理员根据具体情况指定的,也可以是众多的哨兵中按一定的条件选出的。在 WAIT_STATE 中执行故障修复的哨兵首先确定自己是不是首领,如果不是故障修复会被拖延,到下一个定时程序再次检测自己是否为首领,超过一定时间会强制停止故障修复。
怎么样才可以当选一个首领呢?每一个哨兵都会有一个当前的配置版本号 current_-epoch,此版本号会经由hello,is-master-down 命令交换,以便将自身的版本号告知其他所有监视同一 Redis 服务器的哨兵。
每一个哨兵手里都会有一票投给其中一个配置版本最高的哨兵,它的投票信息将会通过 is-master-down 命令交换。is-master-down 命令在故障修复的时候会被强制触发,收到它的哨兵将会进行投票并返回自己的投票结果,哨兵会将它保存在对应的 sentinelRedisInstance 中。如此一来,执行故障修复的哨兵就能得到其他哨兵的投票结果,它就能确定自己是不是哨兵了。
struct sentinelState {
// 哨兵的配置版本
uint64_t current_epoch;
......
} sentinel;
typedef struct sentinelRedisInstance {
......
// 故障修复相关的参数
/* Failover */
// 所选首领的runid。runid 其实就是一个redis 服务器唯一标识
char *leader; /* If this is a master instance, this is the runid of
the Sentinel that should perform the failover. If
this is a Sentinel, this is the runid of the Sentinel
that this Sentinel voted as leader. */
// 所选首领的配置版本
uint64_t leader_epoch; /* Epoch of the 'leader' field. */
......
} sentinelRedisInstance;因此, 只要某哨兵的配置版本足够高, 它就有机会当选为首领。在
sentinelTimer()-»sentinelHandleDictOfRedisInstances()-»sentinelHandleRedisInstance()-
»sentinelFailoverStateMachine()-»sentinelFailoverWaitStart()-»sentinelFailoverWaitStart()你可以看到详细的投票过程。
总结了一下选举首领的过程:
- 遍历哨兵表中的所有哨兵,统计每个哨兵的得票情况,注意,得票哨兵的版本号必须和执行故障修复哨兵的配置版本号相同,这样做是为了确认执行故障修复版本号已经将自己的版本告诉了其他的哨兵。【这里在画图的时候可以说明白,其实低版本号的哨兵是没有机会进行故障修复的】
- 计算得票最多的哨兵
- 执行故障修复的哨兵自己给得票数最高的哨兵投一票,如果没有投票结果,则给自己投一票。当然投票的前提还是配置版本号要比自己的高。
- 再次计算得票最多的哨兵
- 满足两个条件:得票最多的哨兵的票数必须超过选举数的一半以上;得票最多的哨兵的票数必须超过主机的法定人数(quorum)。
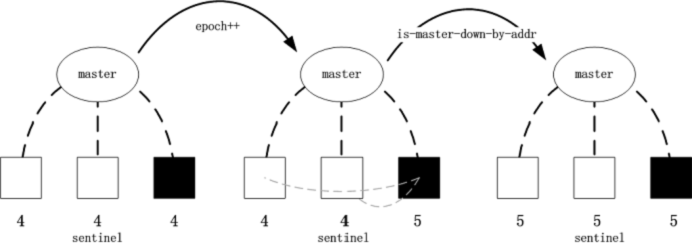
是一个比较曲折的过程。最终,如果确定当前执行故障修复的哨兵是首领,它则可以进入下一个状态:SELECT_SLAVE。
SELECT_SLAVE
SELECT_SLAVE 的意图很明确,因为当前的主机(master)已经挂了,需要重新指定一个主机,候选的服务器就是当前挂掉主机的所有从机(slave)。
在
sentinelTimer()-»sentinelHandleDictOfRedisInstances()-»sentinelHandleRedisInstance()-»sentinelFailoverStateMachine()-»sentinelFailoverSelectSlave()-»sentinelSelectSlave() 你可以看到详细的选举过程。
当前执行故障修复的哨兵会遍历主机的所有从机,只有足够健康的从机才能被成为候选主机。足够健康的条件包括:
- 不能有下面三个标记中的一个:SRI_S_DOWN|SRI_O_DOWN|SRI_DISCONNECTED
- ping 心跳正常
- 优先级不能为 0(slave->slave_priority)
- INFO 数据不能超时
- 主从连接断线会时间不能超时
满足以上条件就有机会成为候选主机,如果经过上面的筛选之后有多台从机,那么这些从机会按下面的条件排序:
- 优选选择优先级高的从机
- 优先选择主从复制偏移量高的从机,即从机从主机复制的数据越多
- 优先选择有 runid 的从机
- 如果上面条件都一样,那么将 runid 按字典顺序排序
所选用的排序算法是常用的快排。这是一个比较曲折的过程。如果没有从机符合要求,譬如最极端的情况,所有从机都跟着挂了,那么故障修复会失败;否则最终会确定一个从机成为候选主机。从机可以进入下一个状态:SLAVEOF_NOONE。
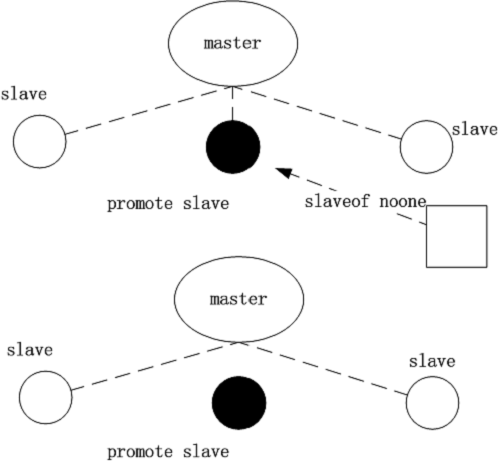
SLAVEOF_NOONE
这一步中,哨兵主要做的是向候选主机发送slaveof noone 命令。我们知道,slaveof noone 命令可以让一个从机转变为一个主机,Redis 从机收到会做从从机到主机的转换。发送 slaveof noone 命令之后,哨兵还会向候选主机发送 config rewrite 让候选主机当前配置信息写入配置文件,以方便候选从机下次重启的时候可以恢复。
void sentinelFailoverSendSlaveOfNoOne(sentinelRedisInstance *ri) {
int retval;
// 与候选从机的连接必须正常,且故障修复没有超时
/* We can't send the command to the promoted slave if it is now
* disconnected. Retry again and again with this state until the timeout
* is reached, then abort the failover. */
if (ri->promoted_slave->flags & SRI_DISCONNECTED) {
if (mstime() - ri->failover_state_change_time > ri->failover_timeout) {
sentinelEvent(REDIS_WARNING,"-failover-abort-slave-timeout",ri,"%@");
sentinelAbortFailover(ri);
}
return;
}
/* Send SLAVEOF NO ONE command to turn the slave into a master.
* We actually register a generic callback for this command as we don't
* really care about the reply. We check if it worked indirectly observing
* if INFO returns a different role (master instead of slave). */
retval = sentinelSendSlaveOf(ri->promoted_slave,NULL,0);
......
}
WAIT_PROMOTION
这一状态纯粹是为了等待上一个状态的执行结果(如候选主机的一些状态)被传播到此哨兵上,至于是如何传播的,之前我们有提到过 INFO 数据传输的过程。这一状态的执行函数 sentinelFailoverWaitPromotion() 只做了超时的判断,如果超时就会停止故障修复。那状态是如何转变的呢?就在哨兵捕捉到候选主机状态的时候。我们可以看到,在哨兵处理 Redis 服务器 INFO 输出的回调函数 sentinelInfoReplyCallback() 中,故障修复的状态从 WAIT_PROMOTION 转变到了下一个状态 RECONF_SLAVES。
RECONF_SLAVES
这是故障修复状态机里面的最后一个状态,后面还会有一个状态。这一状态主要做的是向其他非候选从机发送 slaveof promote_slave,即让候选主机成为他们的主机。其中会涉及几个 Redis 服务器状态的标记:SRI_RECONF_SENT,SRI_RECONFINPROG,SRI-RECONF_DONE,分别表示已经向从机发送 slaveof 命令,从机正在重新配置(这里需要一些时间),配置完成。同样,哨兵是通过 INFO 数据传输中获知这些状态变更的。
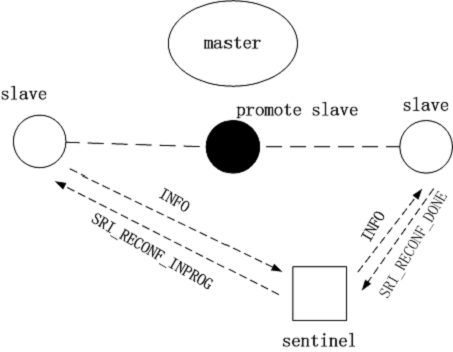
详细重新配置过程可以在
sentinelTimer()-»sentinelHandleDictOfRedisInstances()-
»sentinelHandleRedisInstance()-»sentinelFailoverStateMachine()-
»sentinelFailoverReconfNextSlave()-»sentinelSelectSlave()最后会做从机配置状况的检测,如果所有从机都重新配置完成或者超时了,会进入最后一个状态 UPDATE_CONFIG。
UPDATE_CONFIG
这里还存在最后一个状态 UPDATE_CONFIG。在定时程序中如果发现进入了这一状态,会调用sentinelFailoverSwitchToPromotedSlave()-»sentinelResetMasterAndChangeAddress()。因为主机和从机发生了修改,所以 sentinel.masters 肯定需要修改,譬如主机的IP 地址和端口,所以最后的工作是将修改并整理哨兵服务器保存的信息,而这正是 sentinelResetMasterAndChangeAddress()的主要工作。

int sentinelResetMasterAndChangeAddress(sentinelRedisInstance *master, char *ip, int port) {
sentinelAddr *oldaddr, *newaddr;
sentinelAddr **slaves = NULL;
int numslaves = 0, j;
dictIterator *di;
dictEntry *de;
newaddr = createSentinelAddr(ip,port);
if (newaddr == NULL) return REDIS_ERR;
// 保存从机实例
/* Make a list of slaves to add back after the reset.
* Don't include the one having the address we are switching to. */
di = dictGetIterator(master->slaves);
while((de = dictNext(di)) != NULL) {
sentinelRedisInstance *slave = dictGetVal(de);
if (sentinelAddrIsEqual(slave->addr,newaddr)) continue;
slaves = zrealloc(slaves,sizeof(sentinelAddr*)*(numslaves+1));
slaves[numslaves++] = createSentinelAddr(slave->addr->ip,
slave->addr->port);
}
dictReleaseIterator(di);
// 主机也被视为从机添加到从机数组
/* If we are switching to a different address, include the old address
* as a slave as well, so that we'll be able to sense / reconfigure
* the old master. */
if (!sentinelAddrIsEqual(newaddr,master->addr)) {
slaves = zrealloc(slaves,sizeof(sentinelAddr*)*(numslaves+1));
slaves[numslaves++] = createSentinelAddr(master->addr->ip,
master->addr->port);
}
// 重置主机
// sentinelResetMaster() 会将很多信息清空,也会设置很多信息
/* Reset and switch address. */
sentinelResetMaster(master,SENTINEL_RESET_NO_SENTINELS);
oldaddr = master->addr;
master->addr = newaddr;
master->o_down_since_time = 0;
master->s_down_since_time = 0;
// 将从机恢复
/* Add slaves back. */
for (j = 0; j < numslaves; j++) {
sentinelRedisInstance *slave;
slave = createSentinelRedisInstance(NULL,SRI_SLAVE,slaves[j]->ip,
slaves[j]->port, master->quorum, master);
releaseSentinelAddr(slaves[j]);
if (slave) {
sentinelEvent(REDIS_NOTICE,"+slave",slave,"%@");
sentinelFlushConfig();
}
}
zfree(slaves);
// 销毁旧的地址结构体
/* Release the old address at the end so we are safe even if the function
* gets the master->addr->ip and master->addr->port as arguments. */
releaseSentinelAddr(oldaddr);
sentinelFlushConfig();
return REDIS_OK;
}还有一个问题:故障修复过程中,一直没有发送 SLAVEOF promoted_slave 给旧的主机,因为已经和旧的主机断开连接,哨兵没有选择在故障修复的时候向它发送任何的数据。但在故障修复的最后一个状态中,哨兵依旧有将旧的主机塞到新主机的从机列表中,所以哨兵还是会超时发送 INFO HELLO 等数据,对旧的主机抱有希望。如果因为网络环境的不佳导致的故障修复,那旧的主机很可能恢复过来,只是这时它是一台从机了。哨兵选择在这个时候,发送 slaveof onone 重新配置旧的主机。
就此,故障修复结束。故障修复为 Redis 集群很好的自适应和自修复性。当某主机因为异常或者宕机而不能提供服务的时候,故障修复还能让 Redis 集群继续提供服务。