并发编程:API 及挑战
并发所描述的概念就是同时运行多个任务。这些任务可能是以在单核 CPU 上分时(时间共享)的形式同时运行,也可能是在多核 CPU 上以真正的并行方式来运行。
OS X 和 iOS 提供了几种不同的 API 来支持并发编程。每一个 API 都具有不同的功能和使用限制,这使它们适合不同的任务。同时,这些 API 处在不同的抽象层级上。我们有可能用其进行非常深入底层的操作,但是这也意味着背负起将任务进行良好处理的巨大责任。
实际上,并发编程是一个很有挑战的主题,它有许多错综复杂的问题和陷阱。当开发者在使用类似 Grand Central Dispatch(GCD)或 NSOperationQueue 的 API 时,很容易遗忘这些问题和陷阱。本文首先对 OS X 和 iOS 中不同的并发编程 API 进行一些介绍,然后再深入了解并发编程中独立于与你所使用的特定 API 的一些内在挑战。
OS X 和 iOS 中的并发编程
苹果的移动和桌面操作系统中提供了相同的并发编程API。 本文会介绍 pthread 、 NSThread 、GCD 、NSOperationQueue,以及 NSRunLoop。实际上把 run loop 也列在其中是有点奇怪,因为它并不能实现真正的并行,不过因为它与并发编程有莫大的关系,因此值得我们进行一些深入了解。
由于高层 API 是基于底层 API 构建的,所以我们首先将从底层的 API 开始介绍,然后逐步扩展到高层 API。不过在具体编程中,选择 API 的顺序刚好相反:因为大多数情况下,选择高层的 API 不仅可以完成底层 API 能完成的任务,而且能够让并发模型变得简单。
如果你对我们为何坚持推荐使用高抽象层级以及简单的并行代码有所疑问的话,那么你可以看看这篇文章的第二部分并发编程中面临的挑战,以及 Peter Steinberger 写的关于线程安全的文章。
线程
线程(thread)是组成进程的子单元,操作系统的调度器可以对线程进行单独的调度。实际上,所有的并发编程 API 都是构建于线程之上的 —— 包括 GCD 和操作队列(operation queues)。
多线程可以在单核 CPU 上同时(或者至少看作同时)运行。操作系统将小的时间片分配给每一个线程,这样就能够让用户感觉到有多个任务在同时进行。如果 CPU 是多核的,那么线程就可以真正的以并发方式被执行,从而减少了完成某项操作所需要的总时间。
你可以使用 Instruments 中的 CPU strategy view 来得知你的代码或者你在使用的框架代码是如何在多核 CPU 中调度执行的。
需要重点关注的是,你无法控制你的代码在什么地方以及什么时候被调度,以及无法控制执行多长时间后将被暂停,以便轮换执行别的任务。这种线程调度是非常强大的一种技术,但是也非常复杂,我们稍后研究。
先把线程调度的复杂情况放一边,开发者可以使用 POSIX 线程 API,或者 Objective-C 中提供的对该 API 的封装 NSThread,来创建自己的线程。下面这个小示例利用 pthread 来在一百万个数字中查找最小值和最大值。其中并发执行了 4 个线程。从该示例复杂的代码中,应该可以看出为什么你不会希望直接使用 pthread 。
#import <pthread.h>
struct threadInfo {
uint32_t * inputValues;
size_t count;
};
struct threadResult {
uint32_t min;
uint32_t max;
};
void * findMinAndMax(void *arg)
{
struct threadInfo const * const info = (struct threadInfo *) arg;
uint32_t min = UINT32_MAX;
uint32_t max = 0;
for (size_t i = 0; i < info->count; ++i) {
uint32_t v = info->inputValues[i];
min = MIN(min, v);
max = MAX(max, v);
}
free(arg);
struct threadResult * const result = (struct threadResult *) malloc(sizeof(*result));
result->min = min;
result->max = max;
return result;
}
int main(int argc, const char * argv[])
{
size_t const count = 1000000;
uint32_t inputValues[count];
// 使用随机数字填充 inputValues
for (size_t i = 0; i < count; ++i) {
inputValues[i] = arc4random();
}
// 开始4个寻找最小值和最大值的线程
size_t const threadCount = 4;
pthread_t tid[threadCount];
for (size_t i = 0; i < threadCount; ++i) {
struct threadInfo * const info = (struct threadInfo *) malloc(sizeof(*info));
size_t offset = (count / threadCount) * i;
info->inputValues = inputValues + offset;
info->count = MIN(count - offset, count / threadCount);
int err = pthread_create(tid + i, NULL, &findMinAndMax, info);
NSCAssert(err == 0, @"pthread_create() failed: %d", err);
}
// 等待线程退出
struct threadResult * results[threadCount];
for (size_t i = 0; i < threadCount; ++i) {
int err = pthread_join(tid[i], (void **) &(results[i]));
NSCAssert(err == 0, @"pthread_join() failed: %d", err);
}
// 寻找 min 和 max
uint32_t min = UINT32_MAX;
uint32_t max = 0;
for (size_t i = 0; i < threadCount; ++i) {
min = MIN(min, results[i]->min);
max = MAX(max, results[i]->max);
free(results[i]);
results[i] = NULL;
}
NSLog(@"min = %u", min);
NSLog(@"max = %u", max);
return 0;
}NSThread 是 Objective-C 对 pthread 的一个封装。通过封装,在 Cocoa 环境中,可以让代码看起来更加亲切。例如,开发者可以利用 NSThread 的一个子类来定义一个线程,在这个子类的中封装需要在后台线程运行的代码。针对上面的那个例子,我们可以定义一个这样的 NSThread 子类:
@interface FindMinMaxThread : NSThread
@property (nonatomic) NSUInteger min;
@property (nonatomic) NSUInteger max;
- (instancetype)initWithNumbers:(NSArray *)numbers;
@end
@implementation FindMinMaxThread {
NSArray *_numbers;
}
- (instancetype)initWithNumbers:(NSArray *)numbers
{
self = [super init];
if (self) {
_numbers = numbers;
}
return self;
}
- (void)main
{
NSUInteger min;
NSUInteger max;
// 进行相关数据的处理
self.min = min;
self.max = max;
}
@end要想启动一个新的线程,需要创建一个线程对象,然后调用它的 start 方法:
NSMutableSet *threads = [NSMutableSet set];
NSUInteger numberCount = self.numbers.count;
NSUInteger threadCount = 4;
for (NSUInteger i = 0; i < threadCount; i++) {
NSUInteger offset = (count / threadCount) * i;
NSUInteger count = MIN(numberCount - offset, numberCount / threadCount);
NSRange range = NSMakeRange(offset, count);
NSArray *subset = [self.numbers subarrayWithRange:range];
FindMinMaxThread *thread = [[FindMinMaxThread alloc] initWithNumbers:subset];
[threads addObject:thread];
[thread start];
}现在,我们可以通过检测到线程的 isFinished 属性来检测新生成的线程是否已经结束,并获取结果。我们将这个练习留给感兴趣的读者,这主要是因为不论使用 pthread 还是 NSThread 来直接对线程操作,都是相对糟糕的编程体验,这种方式并不适合我们以写出良好代码为目标的编码精神。
直接使用线程可能会引发的一个问题是,如果你的代码和所基于的框架代码都创建自己的线程时,那么活动的线程数量有可能以指数级增长。这在大型工程中是一个常见问题。例如,在 8 核 CPU 中,你创建了 8 个线程来完全发挥 CPU 性能。然而在这些线程中你的代码所调用的框架代码也做了同样事情(因为它并不知道你已经创建的这些线程),这样会很快产生成成百上千的线程。代码的每个部分自身都没有问题,然而最后却还是导致了问题。使用线程并不是没有代价的,每个线程都会消耗一些内存和内核资源。
接下来,我们将介绍两个基于队列的并发编程 API :GCD 和 operation queue 。它们通过集中管理一个被大家协同使用的线程池,来解决上面遇到的问题。
Grand Central Dispatch
为了让开发者更加容易的使用设备上的多核CPU,苹果在 OS X 10.6 和 iOS 4 中引入了 Grand Central Dispatch(GCD)。在下一篇关于底层并发 API 的文章中,我们将更深入地介绍 GCD。
通过 GCD,开发者不用再直接跟线程打交道了,只需要向队列中添加代码块即可,GCD 在后端管理着一个线程池。GCD 不仅决定着你的代码块将在哪个线程被执行,它还根据可用的系统资源对这些线程进行管理。这样可以将开发者从线程管理的工作中解放出来,通过集中的管理线程,来缓解大量线程被创建的问题。
GCD 带来的另一个重要改变是,作为开发者可以将工作考虑为一个队列,而不是一堆线程,这种并行的抽象模型更容易掌握和使用。
GCD 公开有 5 个不同的队列:运行在主线程中的 main queue,3 个不同优先级的后台队列,以及一个优先级更低的后台队列(用于 I/O)。 另外,开发者可以创建自定义队列:串行或者并行队列。自定义队列非常强大,在自定义队列中被调度的所有 block 最终都将被放入到系统的全局队列中和线程池中。
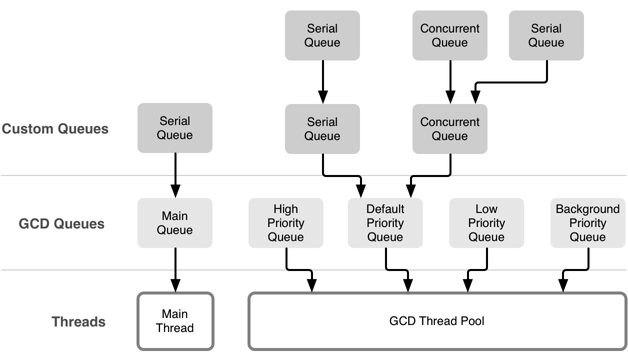
使用不同优先级的若干个队列乍听起来非常直接,不过,我们强烈建议,在绝大多数情况下使用默认的优先级队列就可以了。如果执行的任务需要访问一些共享的资源,那么在不同优先级的队列中调度这些任务很快就会造成不可预期的行为。这样可能会引起程序的完全挂起,因为低优先级的任务阻塞了高优先级任务,使它不能被执行。更多相关内容,在本文的优先级反转部分中会有介绍。
虽然 GCD 是一个低层级的 C API ,但是它使用起来非常的直接。不过这也容易使开发者忘记并发编程中的许多注意事项和陷阱。读者可以阅读本文后面的并发编程中面临的挑战,这样可以注意到一些潜在的问题。本期的另外一篇优秀文章:底层并发 API 中,包含了很多深入的解释和一些有价值的提示。
Operation Queues
操作队列(operation queue)是由 GCD 提供的一个队列模型的 Cocoa 抽象。GCD 提供了更加底层的控制,而操作队列则在 GCD 之上实现了一些方便的功能,这些功能对于 app 的开发者来说通常是最好最安全的选择。
NSOperationQueue 有两种不同类型的队列:主队列和自定义队列。主队列运行在主线程之上,而自定义队列在后台执行。在两种类型中,这些队列所处理的任务都使用 NSOperation 的子类来表述。
你可以通过重写 main 或者 start 方法 来定义自己的 operations 。前一种方法非常简单,开发者不需要管理一些状态属性(例如 isExecuting 和 isFinished),当 main 方法返回的时候,这个 operation 就结束了。这种方式使用起来非常简单,但是灵活性相对重写 start 来说要少一些。
@implementation YourOperation
- (void)main
{
// 进行处理 ...
}
@end如果你希望拥有更多的控制权,以及在一个操作中可以执行异步任务,那么就重写 start 方法:
@implementation YourOperation
- (void)start
{
self.isExecuting = YES;
self.isFinished = NO;
// 开始处理,在结束时应该调用 finished ...
}
- (void)finished
{
self.isExecuting = NO;
self.isFinished = YES;
}
@end注意:这种情况下,你必须手动管理操作的状态。 为了让操作队列能够捕获到操作的改变,需要将状态的属性以配合 KVO 的方式进行实现。如果你不使用它们默认的 setter 来进行设置的话,你就需要在合适的时候发送合适的 KVO 消息。
为了能使用操作队列所提供的取消功能,你需要在长时间操作中时不时地检查 isCancelled 属性:
- (void)main
{
while (notDone && !self.isCancelled) {
// 进行处理
}
}当你定义好 operation 类之后,就可以很容易的将一个 operation 添加到队列中:
NSOperationQueue *queue = [[NSOperationQueue alloc] init];
YourOperation *operation = [[YourOperation alloc] init];
[queue addOperation:operation];另外,你也可以将 block 添加到操作队列中。这有时候会非常的方便,比如你希望在主队列中调度一个一次性任务:
[[NSOperationQueue mainQueue] addOperationWithBlock:^{
// 代码...
}];虽然通过这种的方式在队列中添加操作会非常方便,但是定义你自己的 NSOperation 子类会在调试时很有帮助。如果你重写 operation 的description 方法,就可以很容易的标示出在某个队列中当前被调度的所有操作 。
除了提供基本的调度操作或 block 外,操作队列还提供了在 GCD 中不太容易处理好的特性的功能。例如,你可以通过 maxConcurrentOperationCount 属性来控制一个特定队列中可以有多少个操作参与并发执行。将其设置为 1 的话,你将得到一个串行队列,这在以隔离为目的的时候会很有用。
另外还有一个方便的功能就是根据队列中 operation 的优先级对其进行排序,这不同于 GCD 的队列优先级,它只影响当前队列中所有被调度的 operation 的执行先后。如果你需要进一步在除了 5 个标准的优先级以外对 operation 的执行顺序进行控制的话,还可以在 operation 之间指定依赖关系,如下:
[intermediateOperation addDependency:operation1];
[intermediateOperation addDependency:operation2];
[finishedOperation addDependency:intermediateOperation];这些简单的代码可以确保 operation1 和 operation2 在 intermediateOperation 之前执行,当然,也会在 finishOperation 之前被执行。对于需要明确的执行顺序时,操作依赖是非常强大的一个机制。它可以让你创建一些操作组,并确保这些操作组在依赖它们的操作被执行之前执行,或者在并发队列中以串行的方式执行操作。
从本质上来看,操作队列的性能比 GCD 要低那么一点,不过,大多数情况下这点负面影响可以忽略不计,操作队列是并发编程的首选工具。
Run Loops
实际上,Run loop并不像 GCD 或者操作队列那样是一种并发机制,因为它并不能并行执行任务。不过在主 dispatch/operation 队列中, run loop 将直接配合任务的执行,它提供了一种异步执行代码的机制。
Run loop 比起操作队列或者 GCD 来说容易使用得多,因为通过 run loop ,你不必处理并发中的复杂情况,就能异步地执行任务。
一个 run loop 总是绑定到某个特定的线程中。main run loop 是与主线程相关的,在每一个 Cocoa 和 CocoaTouch 程序中,这个 main run loop 都扮演了一个核心角色,它负责处理 UI 事件、计时器,以及其它内核相关事件。无论你什么时候设置计时器、使用 NSURLConnection 或者调用 performSelector:withObject:afterDelay:,其实背后都是 run loop 在处理这些异步任务。
无论何时你使用 run loop 来执行一个方法的时候,都需要记住一点:run loop 可以运行在不同的模式中,每种模式都定义了一组事件,供 run loop 做出响应。这在对应 main run loop 中暂时性的将某个任务优先执行这种任务上是一种聪明的做法。
关于这点,在 iOS 中非常典型的一个示例就是滚动。在进行滚动时,run loop 并不是运行在默认模式中的,因此, run loop 此时并不会响应比如滚动前设置的计时器。一旦滚动停止了,run loop 会回到默认模式,并执行添加到队列中的相关事件。如果在滚动时,希望计时器能被触发,需要将其设为 NSRunLoopCommonModes 的模式,并添加到 run loop 中。
主线程一般来说都已经配置好了 main run loop。然而其他线程默认情况下都没有设置 run loop。你也可以自行为其他线程设置 run loop ,但是一般来说我们很少需要这么做。大多数时间使用 main run loop 会容易得多。如果你需要处理一些很重的工作,但是又不想在主线程里做,你仍然可以在你的代码在 main run loop 中被调用后将工作分配给其他队列。Chris 在他关于常见的后台实践的文章里阐述了一些关于这种模式的很好的例子。
如果你真需要在别的线程中添加一个 run loop ,那么不要忘记在 run loop 中至少添加一个 input source 。如果 run loop 中没有设置好的 input source,那么每次运行这个 run loop ,它都会立即退出。
并发编程中面临的挑战
使用并发编程会带来许多陷阱。只要一旦你做的事情超过了最基本的情况,对于并发执行的多任务之间的相互影响的不同状态的监视就会变得异常困难。 问题往往发生在一些不确定性(不可预见性)的地方,这使得在调试相关并发代码时更加困难。
关于并发编程的不可预见性有一个非常有名的例子:在1995年, NASA (美国宇航局)发送了开拓者号火星探测器,但是当探测器成功着陆在我们红色的邻居星球后不久,任务嘎然而止,火星探测器莫名其妙的不停重启,在计算机领域内,遇到的这种现象被定为为优先级反转,也就是说低优先级的线程一直阻塞着高优先级的线程。稍后我们会看到关于这个问题的更多细节。在这里我们想说明的是,即使拥有丰富的资源和大量优秀工程师的智慧,并发也还是会在不少情况下反咬你你一口。
资源共享
并发编程中许多问题的根源就是在多线程中访问共享资源。资源可以是一个属性、一个对象,通用的内存、网络设备或者一个文件等等。在多线程中任何一个共享的资源都可能是一个潜在的冲突点,你必须精心设计以防止这种冲突的发生。
为了演示这类问题,我们举一个关于资源的简单示例:比如仅仅用一个整型值来做计数器。在程序运行过程中,我们有两个并行线程 A 和 B,这两个线程都尝试着同时增加计数器的值。问题来了,你通过 C 语言或 Objective-C 写的代码大多数情况下对于 CPU 来说不会仅仅是一条机器指令。要想增加计数器的值,当前的必须被从内存中读出,然后增加计数器的值,最后还需要将这个增加后的值写回内存中。
我们可以试着想一下,如果两个线程同时做上面涉及到的操作,会发生怎样的偶然。例如,线程 A 和 B 都从内存中读取出了计数器的值,假设为 17 ,然后线程A将计数器的值加1,并将结果 18 写回到内存中。同时,线程B也将计数器的值加 1 ,并将结果 18 写回到内存中。实际上,此时计数器的值已经被破坏掉了,因为计数器的值 17 被加 1 了两次,而它的值却是 18。
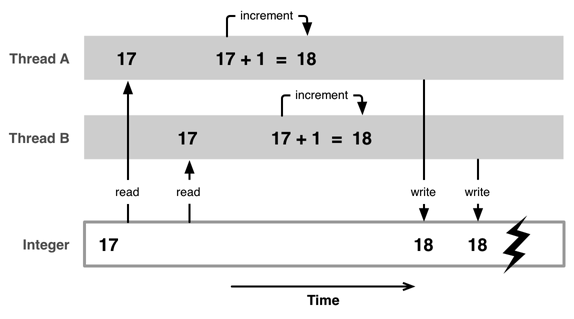
这个问题被叫做竞态条件,在多线程里面访问一个共享的资源,如果没有一种机制来确保在线程 A 结束访问一个共享资源之前,线程 B 就不会开始访问该共享资源的话,资源竞争的问题就总是会发生。如果你所写入内存的并不是一个简单的整数,而是一个更复杂的数据结构,可能会发生这样的现象:当第一个线程正在写入这个数据结构时,第二个线程却尝试读取这个数据结构,那么获取到的数据可能是新旧参半或者没有初始化。为了防止出现这样的问题,多线程需要一种互斥的机制来访问共享资源。
在实际的开发中,情况甚至要比上面介绍的更加复杂,因为现代 CPU 为了优化目的,往往会改变向内存读写数据的顺序(乱序执行)。
互斥锁
互斥访问的意思就是同一时刻,只允许一个线程访问某个特定资源。为了保证这一点,每个希望访问共享资源的线程,首先需要获得一个共享资源的互斥锁,一旦某个线程对资源完成了操作,就释放掉这个互斥锁,这样别的线程就有机会访问该共享资源了。
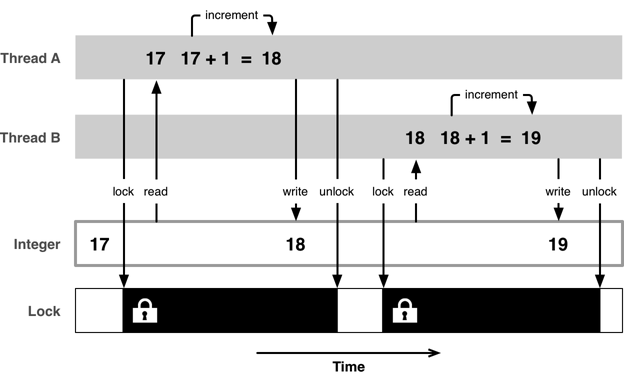
除了确保互斥访问,还需要解决代码无序执行所带来的问题。如果不能确保 CPU 访问内存的顺序跟编程时的代码指令一样,那么仅仅依靠互斥访问是不够的。为了解决由 CPU 的优化策略引起的副作用,还需要引入内存屏障。通过设置内存屏障,来确保没有无序执行的指令能跨过屏障而执行。
当然,互斥锁自身的实现是需要没有竞争条件的。这实际上是非常重要的一个保证,并且需要在现代 CPU 上使用特殊的指令。更多关于原子操作(atomic operation)的信息,请阅读 Daniel 写的文章:底层并发技术。
从语言层面来说,在 Objective-C 中将属性以 atomic 的形式来声明,就能支持互斥锁了。事实上在默认情况下,属性就是 atomic 的。将一个属性声明为 atomic 表示每次访问该属性都会进行隐式的加锁和解锁操作。虽然最把稳的做法就是将所有的属性都声明为 atomic,但是加解锁这也会付出一定的代价。
在资源上的加锁会引发一定的性能代价。获取锁和释放锁的操作本身也需要没有竞态条件,这在多核系统中是很重要的。另外,在获取锁的时候,线程有时候需要等待,因为可能其它的线程已经获取过资源的锁了。这种情况下,线程会进入休眠状态。当其它线程释放掉相关资源的锁时,休眠的线程会得到通知。所有这些相关操作都是非常昂贵且复杂的。
锁也有不同的类型。当没有竞争时,有些锁在没有锁竞争的情况下性能很好,但是在有锁的竞争情况下,性能就会大打折扣。另外一些锁则在基本层面上就比较耗费资源,但是在竞争情况下,性能的恶化会没那么厉害。(锁的竞争是这样产生的:当一个或者多个线程尝试获取一个已经被别的线程获取过了的锁)。
在这里有一个东西需要进行权衡:获取和释放锁所是要带来开销的,因此你需要确保你不会频繁地进入和退出临界区段(比如获取和释放锁)。同时,如果你获取锁之后要执行一大段代码,这将带来锁竞争的风险:其它线程可能必须等待获取资源锁而无法工作。这并不是一项容易解决的任务。
我们经常能看到本来计划并行运行的代码,但实际上由于共享资源中配置了相关的锁,所以同一时间只有一个线程是处于激活状态的。对于你的代码会如何在多核上运行的预测往往十分重要,你可以使用 Instrument 的 CPU strategy view 来检查是否有效的利用了 CPU 的可用核数,进而得出更好的想法,以此来优化代码。
死锁
互斥锁解决了竞态条件的问题,但很不幸同时这也引入了一些其他问题,其中一个就是死锁。当多个线程在相互等待着对方的结束时,就会发生死锁,这时程序可能会被卡住。
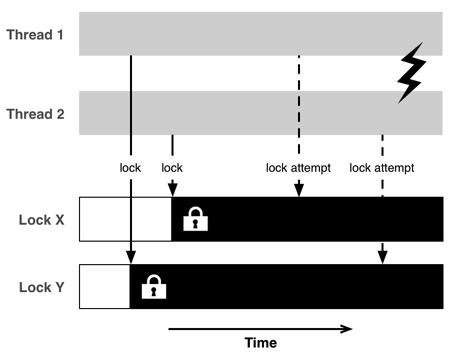
看看下面的代码,它交换两个变量的值:
void swap(A, B)
{
lock(lockA);
lock(lockB);
int a = A;
int b = B;
A = b;
B = a;
unlock(lockB);
unlock(lockA);
}大多数时候,这能够正常运行。但是当两个线程使用相反的值来同时调用上面这个方法时:
swap(X, Y); // 线程 1
swap(Y, X); // 线程 2此时程序可能会由于死锁而被终止。线程 1 获得了 X 的一个锁,线程 2 获得了 Y 的一个锁。 接着它们会同时等待另外一把锁,但是永远都不会获得。
再说一次,你在线程之间共享的资源越多,你使用的锁也就越多,同时程序被死锁的概率也会变大。这也是为什么我们需要尽量减少线程间资源共享,并确保共享的资源尽量简单的原因之一。建议阅读一下底层并发编程 API 中的全部使用异步分发一节。
资源饥饿(Starvation)
当你认为已经足够了解并发编程面临的问题时,又出现了一个新的问题。锁定的共享资源会引起读写问题。大多数情况下,限制资源一次只能有一个线程进行读取访问其实是非常浪费的。因此,在资源上没有写入锁的时候,持有一个读取锁是被允许的。这种情况下,如果一个持有读取锁的线程在等待获取写入锁的时候,其他希望读取资源的线程则因为无法获得这个读取锁而导致资源饥饿的发生。
为了解决这个问题,我们需要使用一个比简单的读/写锁更聪明的方法,例如给定一个 writer preference,或者使用 read-copy-update 算法。Daniel 在底层并发编程 API 中有介绍了如何用 GCD 实现一个多读取单写入的模式,这样就不会被写入资源饥饿的问题困扰了。
优先级反转
本节开头介绍了美国宇航局发射的开拓者号火星探测器在火星上遇到的并发问题。现在我们就来看看为什么开拓者号几近失败,以及为什么有时候我们的程序也会遇到相同的问题,该死的优先级反转。
优先级反转是指程序在运行时低优先级的任务阻塞了高优先级的任务,有效的反转了任务的优先级。由于 GCD 提供了拥有不同优先级的后台队列,甚至包括一个 I/O 队列,所以我们最好了解一下优先级反转的可能性。
高优先级和低优先级的任务之间共享资源时,就可能发生优先级反转。当低优先级的任务获得了共享资源的锁时,该任务应该迅速完成,并释放掉锁,这样高优先级的任务就可以在没有明显延时的情况下继续执行。然而高优先级任务会在低优先级的任务持有锁的期间被阻塞。如果这时候有一个中优先级的任务(该任务不需要那个共享资源),那么它就有可能会抢占低优先级任务而被执行,因为此时高优先级任务是被阻塞的,所以中优先级任务是目前所有可运行任务中优先级最高的。此时,中优先级任务就会阻塞着低优先级任务,导致低优先级任务不能释放掉锁,这也就会引起高优先级任务一直在等待锁的释放。
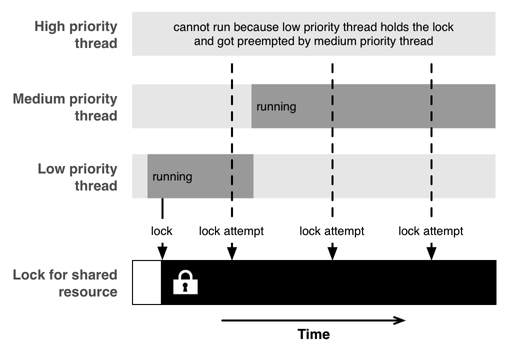
在你的实际代码中,可能不会像发生在火星的事情那样戏剧性地不停重启。遇到优先级反转时,一般没那么严重。
解决这个问题的方法,通常就是不要使用不同的优先级。通常最后你都会以让高优先级的代码等待低优先级的代码来解决问题。当你使用 GCD 时,总是使用默认的优先级队列(直接使用,或者作为目标队列)。如果你使用不同的优先级,很可能实际情况会让事情变得更糟糕。
从中得到的教训是,使用不同优先级的多个队列听起来虽然不错,但毕竟是纸上谈兵。它将让本来就复杂的并行编程变得更加复杂和不可预见。如果你在编程中,遇到高优先级的任务突然没理由地卡住了,可能你会想起本文,以及那个美国宇航局的工程师也遇到过的被称为优先级反转的问题。
总结
我们希望通过本文你能够了解到并发编程带来的复杂性和相关问题。并发编程中,无论是看起来多么简单的 API ,它们所能产生的问题会变得非常的难以观测,而且要想调试这类问题往往也都是非常困难的。
但另一方面,并发实际上是一个非常棒的工具。它充分利用了现代多核 CPU 的强大计算能力。在开发中,关键的一点就是尽量让并发模型保持简单,这样可以限制所需要的锁的数量。
我们建议采纳的安全模式是这样的:从主线程中提取出要使用到的数据,并利用一个操作队列在后台处理相关的数据,最后回到主队列中来发送你在后台队列中得到的结果。使用这种方式,你不需要自己做任何锁操作,这也就大大减少了犯错误的几率。