GPU 加速下的图像视觉
越来越多的移动计算设备都开始携带照相机镜头,这对于摄影界来说是一个好事情,不仅如此携带镜头也为这些设备提供了更多的可能性。除了最基本的拍摄功能,结合合适的软件这些更为强大的硬件设备可以像人脑一样理解它看到了什么。
仅仅具备一点点的理解能力就可以催生一些非常强大的应用,比如说条形码识别,文档识别和成像,手写文字的转化,实时图像防抖,增强现实等。随着处理能力变得更加强大,镜头保真程度更高,算法效率更好,机器视觉 (machine vision) 这个技术将会解决更加重大的问题。
有些人认为机器视觉是个非常复杂的领域,是程序员们的日常工作中绝不会遇到的。我认为这种观点是不正确的。我发起了一个开源项目 GPUImage,其实在很大程度上是因为我想探索一下高性能的机器视觉是怎么样的,并且让这种技术更易于使用。
GPU 是一种理想的处理图片和视频的设备,因为它是专门为并行处理大量数据而生的,图片和视频中的每一帧都包含大量的像素数据。在某些情况下 GPU 处理图片的速度可以是 CPU 的成千上百倍。
在我开发 GPUImage 的过程中我学到了一件事情,那就是即使是图片处理这样看上去很复杂的工作依然可以分解为一个个更小更简单的部分。这篇文章里我想将一些机器视觉中常见的过程分解开来,并且展示如何在现代的 GPU 设备上让这些过程运行地更快。
以下的每一步在 GPUImage 中都有完整的实现,你可以下载包含了 OS X 和 iOS 版本的示例工程 FilterShowcase,在其中体验一下各个功能。此外,这些功能都有基于 CPU (有些使用了 GPU 加速) 的实现,这些实现是基于 OpenCV 库的,在另一片文章中 Engin Kurutepe 详细地讲解了这个库。
索贝尔 (Sobel) 边界探测
我将要描述的第一种操作事实上在滤镜方面的应用比机器视觉方面更多,但是从这个操作讲起是比较合适的。索贝尔边界探测用于探测一张图片中边界的出现位置,边界是指由明转暗的突然变化或者反过来由暗转明的区域[1]。在被处理的图片中一个像素的亮度反映了这个像素周围边界的强度。
下面是一个例子,我们来看看同一张图片在进行索贝尔边界探测之前和之后:


正如我上面提到的,这项技术通常用来实现一些视觉效果。如果在上面的图片中将颜色进行反转,最明显的边界用黑色代表而不是白色,那么我们就得到了一张类似铅笔素描效果的图片。

那么这些边界是如何被探测出来的?第一步这张彩色图片需要减薄成一张亮度 (灰阶) 图。Janie Clayton 在她的文章中解释了这一步是如何在一个片断着色器 (fragment shader) 中完成的。简单地说这个过程就是将每个像素的红绿蓝部分加权合为一个代表这个像素亮度的值。
有的视频设备和相机提供的是 YUV 格式的图片,而不是 RGB 格式。YUV 这种色彩格式已经将亮度信息 (Y) 和色度信息 (UV) 分离,所以如果原图片是这种格式,颜色转换这个步骤就可以省略,直接用其中亮度的部分就可以。
图片一旦减薄到仅剩亮度信息,一个像素周围的边界强度就可以由它周围 3*3 个临近像素计算而得。在一组像素上进行图片处理的计算过程涉及到一个叫做卷积矩阵 (参考:convolution matrix) 的东西。卷积矩阵是一个由权重数据组成的矩阵,中心像素周围像素的亮度乘以这些权重然后再相加就能得到中心像素的转化后数值。
图片上的每一个像素都要与这个矩阵计算出一个数值。在处理的过程中像素的处理顺序是无关紧要的,所以这种计算很容易并行运行。因此,这个计算过程可以通过一个片断着色器的方式运行在可编程的 GPU 上,来极大地提高处理效率。正如在 Janie 的文章中所提到的,片断着色器是一些 C 语言风格的程序,运行在 GPU 上可以进行一些非常快速的图片处理。
下面这个是索贝尔算子的水平处理矩阵:
| −1 | 0 | +1 |
| −2 | 0 | +2 |
| −1 | 0 | +1 |
为了进行某一个像素的计算,每一个临近像素的亮度信息都要读取出来。如果要处理的图片已经被转化为灰阶图,亮度可以从红绿蓝任意颜色通道中抽样。临近像素的亮度乘以矩阵中对应的权重,然后加到最终值里去。
在一个方向上寻找边界的过程是这样的:转化之后对比一个像素左右两边像素的亮度差。如果当前这个像素左右两边的像素亮度相同也就是说在图片上是一个柔和的过度,它们的亮度值和正负权重会相互抵消,于是这个区域不会被判定为边界。如果左边像素和右边像素的亮度差别很大也就是说是一个边界,用其中一个亮度减去另一个,这种差异越大这个边界就越强 (越明显)。
索贝尔过程有两个步骤,首先是水平矩阵进行,同时一个垂直矩阵也会进行,这个垂直矩阵中的权重如下
| −1 | −2 | −1 |
| 0 | 0 | 0 |
| +1 | +2 | +1 |
两个方向转化后的加权和会被记录下来,它们的平方和的平方根也会被计算出来。之所以要进行平方是因为计算出来的值可能是正值也可能是负值,但是我们需要的是值的量级而不关心它们的正负。有一个好用内建的 GLSL 函数能够帮助我们快速完成这个过程。
最终计算出来的这个值会用来作为输出图片中像素的亮度。因为索贝尔算子会突出显示两边像素亮度的不同的地方,所以图片中由明转暗或者相反的突然转变会成为结果中明亮的像素。
索贝尔边界探测有一些相似的变体,例如普里维特 (Prewitt) 边界探测[2]。普里维特边界探测会在横向竖向矩阵中使用不同的权重,但是它们运作的基本过程是一样的。
作为索贝尔边界探测如何用代码实现的一个例子,下面是用 OpenGL ES 进行索贝尔边界探测的片断着色器:
precision mediump float;
varying vec2 textureCoordinate;
varying vec2 leftTextureCoordinate;
varying vec2 rightTextureCoordinate;
varying vec2 topTextureCoordinate;
varying vec2 topLeftTextureCoordinate;
varying vec2 topRightTextureCoordinate;
varying vec2 bottomTextureCoordinate;
varying vec2 bottomLeftTextureCoordinate;
varying vec2 bottomRightTextureCoordinate;
uniform sampler2D inputImageTexture;
void main()
{
float bottomLeftIntensity = texture2D(inputImageTexture, bottomLeftTextureCoordinate).r;
float topRightIntensity = texture2D(inputImageTexture, topRightTextureCoordinate).r;
float topLeftIntensity = texture2D(inputImageTexture, topLeftTextureCoordinate).r;
float bottomRightIntensity = texture2D(inputImageTexture, bottomRightTextureCoordinate).r;
float leftIntensity = texture2D(inputImageTexture, leftTextureCoordinate).r;
float rightIntensity = texture2D(inputImageTexture, rightTextureCoordinate).r;
float bottomIntensity = texture2D(inputImageTexture, bottomTextureCoordinate).r;
float topIntensity = texture2D(inputImageTexture, topTextureCoordinate).r;
float h = -bottomLeftIntensity - 2.0 * leftIntensity - topLeftIntensity + bottomRightIntensity + 2.0 * rightIntensity + topRightIntensity;
float v = -topLeftIntensity - 2.0 * topIntensity - topRightIntensity + bottomLeftIntensity + 2.0 * bottomIntensity + bottomRightIntensity;
float mag = length(vec2(h, v));
gl_FragColor = vec4(vec3(mag), 1.0);
}上面这段着色器中中心像素周围的像素都有用户定义的名称,是由一个自定义的顶点着色器提供的,这么做可以优化减少对移动设备环境的依赖。从 3*3 网格中抽样出这些命名了的像素,然后用自定义的代码来进行横向和纵向索贝尔探测。为简化计算权重为 0 的部分会被忽略。GLSL 函数 length() 计算出水平和垂直矩阵转化后值的平方和的平方根。然后这个代表量级的值会被拷贝进输出像素的红绿蓝通道中,这样就可以用来代表边界的明显程度。
坎尼 (Canny) 边界探测
索贝尔边界探测可以给你一张图片边界强度的直观印象,但是并不能明确地说明某一个像素是否是一个边界。如果要判断一个像素是否是一个边界,你要设定一个类似阈值的东西,亮度高于这个阈值的像素会被判定为边界的一部分。然而这样并不是最理想的,因为这样的做法判定出的边界可能会有好几个像素宽,并且不同的图片适合的阈值不同。
这里你更需要一种叫做坎尼边界探测[3]的边界探测方法。坎尼边界探测可以在一张图片中探测出连贯的只有一像素宽的边界:

坎尼边界探测包含了几个步骤。和索贝尔边界探测以及其他我们接下来将要讨论的方法一样,在进行边界探测之前首先图片需要转化成亮度图。一旦转化为灰阶亮度图紧接着进行一点点的高斯模糊,这么做是为了降低传感器噪音对边界探测的影响。
一旦图片已经准备好了,边界探测就可以开始进行。这里的 GPU 加速过程原本是在 Ensor 和 Hall 的文章 "GPU-based Image Analysis on Mobile Devices" [4]中所描述的。
首先,一个给定像素的边界强度和边界梯度要确定下来。边界梯度是指亮度发生变化最大的方向,也是边界延伸方向的垂直方向。
为了寻找边界梯度,我们要用到上一章中的索贝尔矩阵。索贝尔转化得到的横竖值加合后就是边界梯度的强度,这个值会编码进输出像素的红色通道。然后横向竖向索贝尔结果值会与八个方向 (对应一个中心像素周围的八个像素) 中的一个结合起来,一个方向上 X 部分值会作为输出像素的绿色通道值,Y 部分则作为蓝色通道值。
这个方法使用的着色器和索贝尔边界探测使用的类似,只是最后一个计算步骤用下面这段代码:
vec2 gradientDirection;
gradientDirection.x = -bottomLeftIntensity - 2.0 * leftIntensity - topLeftIntensity + bottomRightIntensity + 2.0 * rightIntensity + topRightIntensity;
gradientDirection.y = -topLeftIntensity - 2.0 * topIntensity - topRightIntensity + bottomLeftIntensity + 2.0 * bottomIntensity + bottomRightIntensity;
float gradientMagnitude = length(gradientDirection);
vec2 normalizedDirection = normalize(gradientDirection);
normalizedDirection = sign(normalizedDirection) * floor(abs(normalizedDirection) + 0.617316); // Offset by 1-sin(pi/8) to set to 0 if near axis, 1 if away
normalizedDirection = (normalizedDirection + 1.0) * 0.5; // Place -1.0 - 1.0 within 0 - 1.0
gl_FragColor = vec4(gradientMagnitude, normalizedDirection.x, normalizedDirection.y, 1.0);为确保坎尼边界一像素宽,只有边界中强度最高的部分会被保留下来。因此,我们需要在每一个切面边界梯度的宽度之内寻找最大值。
这就是我们在上一步中算出的梯度方向起作用的地方。对每一个像素,我们根据梯度值向前和向后取出最近的相邻像素,然后对比他们的梯度强度 (边界明显程度)。如果当前像素的梯度强度高于梯度方向前后的像素我们就保留当前像素。如果当前像素的梯度强度低于任何一个临近像素,我们就不再考虑这个像素并且将他变为黑色。
执行这个步骤的着色器如下:
precision mediump float;
varying highp vec2 textureCoordinate;
uniform sampler2D inputImageTexture;
uniform highp float texelWidth;
uniform highp float texelHeight;
uniform mediump float upperThreshold;
uniform mediump float lowerThreshold;
void main()
{
vec3 currentGradientAndDirection = texture2D(inputImageTexture, textureCoordinate).rgb;
vec2 gradientDirection = ((currentGradientAndDirection.gb * 2.0) - 1.0) * vec2(texelWidth, texelHeight);
float firstSampledGradientMagnitude = texture2D(inputImageTexture, textureCoordinate + gradientDirection).r;
float secondSampledGradientMagnitude = texture2D(inputImageTexture, textureCoordinate - gradientDirection).r;
float multiplier = step(firstSampledGradientMagnitude, currentGradientAndDirection.r);
multiplier = multiplier * step(secondSampledGradientMagnitude, currentGradientAndDirection.r);
float thresholdCompliance = smoothstep(lowerThreshold, upperThreshold, currentGradientAndDirection.r);
multiplier = multiplier * thresholdCompliance;
gl_FragColor = vec4(multiplier, multiplier, multiplier, 1.0);
}其中 texelWidth 和 texelHeight 是要处理的图片中临近像素之间的距离,lowerThreshold 和 upperThreshold 分别设定了我们预期的边界强度上下限。
在坎尼边界探测的最后一步,边界上出现像素间间隔的地方要被填充,出现间隔是因为有一些点不在阈值范围之内或者是因为非最大值转化没有起作用。这一步会完善边界使边界连续起来。
在最后一步中需要考虑一个中心像素周围的所有像素。如果这个中心像素是最大值,上一步中非最大值转化就不会影响它,它依然是白色。如果它不是最大值,就会变成黑色。对于中间的灰色像素,会考察它周围像素的信息。凡是与超过一个白色像素挨着的都会变为白色,相反就会变成黑色。这样就可以将边界分离的部分接合起来。
正如你所看到的,坎尼边界探测会比索贝尔边界探测更复杂一些,但是它会探测出一条物体边界的干净线条。这是线条探测、轮廓探测或者其他图片分析很好的起点。同时也可以被用来生成一些有趣的美学效果。
哈里斯 (Harris) 边角探测
虽然利用上一章中的边界探测技术我们可以获取关于图片边界的信息,我们会得到一张可以直观观察到边界所在位置的图片,但是并没有更高层面有关图片中所展示内容的信息。为了得到这些信息,我们需要一个可以处理场景中的像素然后返回场景中所展示内容的描述性信息的算法。
进行物体探测和匹配时一个常见的出发点是特征探测。特征是指一个场景中具有特殊意义的点,这些点可以唯一的区分出一些结构或者物体。由于边角的出现往往意味着亮度或者颜色的突然变化,所以边角常常会作为特征的一种。
在 Harris 和 Stephens 的文章 "A Combined Corner and Edge Detector."[5] 中他们提出一个边角探测的方法。这个命名为哈里斯边角探测的方法采用了一个多步骤的方法来探测场景中的边角。
像我们已经讨论过的其他方法一样,图片首先需要减薄到只剩亮度信息。通过索贝尔矩阵,普里维特矩阵或者其他相关的矩阵计算出一个像素 X 和 Y 方向上的梯度值,计算出的值并不会合并为边界的量级。而是将 X 梯度传入红色部分,Y 梯度传入绿色部分,X 与 Y 梯度的乘积传入蓝色部分。
然后对上述计算结果进行一个高斯模糊。从模糊后的照片中取出红绿蓝部分中的编码过的值,并将值带入一个计算像素是边角点可能性的公式:
R = Ix2 × Iy2 − Ixy × Ixy − k × (Ix2 + Iy2)2
其中 Ix 是 X 方向梯度值 (模糊后图片中红色部分),Iy 是 Y 梯度值 (绿色部分),Ixy 是 XY 值的乘积 (蓝色部分),k 是一个灵敏性常数,R 是计算出来的这个像素是边角的确定程度。Shi,Tomasi[6] 和 Noble[7] 提出过这种计算的另一种实现方法但是结果其实是十分接近的。
在公式中你可以会觉得头两项会抵消掉。但这就是前面高斯模糊那一步起作用的地方。通过在一些像素上分别模糊 X、Y 和 XY 的乘积,在边角附近就会出现可以被探测到的差异。
我们从 Stack Exchange 信号处理分站中的一个问题中取来一张测试图片:

经过前面的计算过程得到的结果如下图:

为了找出边角准确的位置,我们需要选出极点 (一个区域内亮度最高的地方)。这里需要使用一个非最大值转化。和我们在坎尼边界探测中所做的一样,我们要考察一个中心像素周围的临近像素 (从一个像素半径开始,半径可以扩大),只有当中心像素的亮度高于它所有临近像素时才保留他,否则就将这个像素变为黑色。这样一来最后留下的就应该是一片区域中亮度最高的像素,也就是最可能是边角的地方。
通过这个过程,我们现在可以从图片中看到任意不是黑色的像素都是一个边角所在的位置:
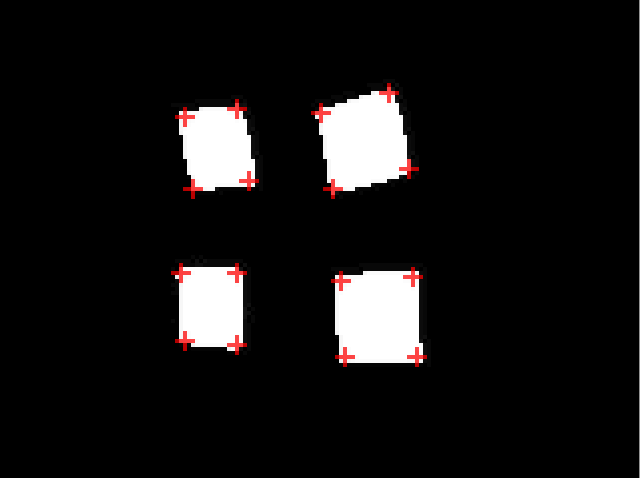
目前我是使用 CPU 来进行点的提取,这可能会是边角探测的一个瓶颈,不过在 GPU 上使用柱状图金字塔[8]可能会加速这个过程。
哈里斯边角探测只是在场景中寻找边角的方法之一。"Machine learning for high-speed corner detection,"[9] 中 Edward Rosten 的 FAST 边角探测方法是另一个性能更好的方法,甚至可能超越基于 GPU 的哈里斯探测。
霍夫 (Hough) 变换线段探测
笔直的线段是另一种我们会在一个场景需要探测的常见的特征。寻找笔直的线段可以帮助应用进行文档扫描和条形码读取。然而,传统的线段探测方法并不适合在 GPU 上实现,特别是在移动设备的 GPU 上。
许多线段探测过程都基于霍夫变换,这是一项将真实世界笛卡尔直角坐标空间中的点转化到另一个坐标空间中去的技术。转化之后在另一个坐标空间中进行计算,计算的结果又转化回正常空间代表线段的位置或者其他特征信息。不幸的是,许多已经提出的计算方法都不适合在 GPU 上运行,因为它们在特性上就不太可能充分地并行执行,并且都需要大量的数学计算,比如在每个像素上进行三角函数计算。
2011年,Dubská 等人 [10] [11] 提出了一种更简单并更有效的坐标空间转换方法和分析方法,这种方法更合适在 GPU 上运行。他们的方法依赖与一个叫做平行坐标空间的概念,听上去很抽象但是我会展示出它其实很容易理解。
我们首先选择一条线段和线段上的三个点:
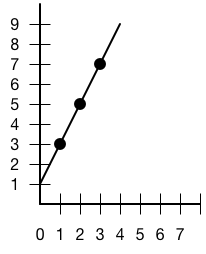
要将这条线段转化到平行坐标空间去,我们需要画出三个平行的垂直轴。在中间的轴上,我们选取三个点在 X 轴上的值,也就是 1,2,3 处画一个点。在左边的轴上,我们选取三个点在 Y 轴上的值,在 3,5,7 处画一个点。在右边的轴上我们做同样的事情,但是取 Y 轴的负值。
接下来我们将代表 Y 轴值的点和它对应的 X 轴值连接起来。连接后的效果像下图:

你会注意到在右边的三条线会相交于一点。这个点的坐标值代表了在真实空间中线段的斜率和截距。如果我们用一个向下斜的线段,那么相交会发生在图的左半边。
如果我们取交点到中间轴的距离作为 u (在这个例子中是 2),取竖直方向到 0 的距离作为 v (这里是 1/3),将轴之间的距离作为 d (这个例子中我使用的距离是 6),我们可以用这样的公式计算斜率和截距
斜率 = −1 + d/u
截距 = d × v/u
斜率是 2,截距是 1,和上面我们所画的线段一致。
这种简单有序的线段绘画非常适合 GPU 进行,所以这种方法是一种利用 GPU 进行线段探测理想的方式。
探测线段的第一步是寻找可能代表一个线段的点。我们寻找的是位于边界位置的点,并且我们希望将需要分析的点的数量控制在最少,所以之前谈论的坎尼边界探测是一个非常好的起点。
进行边界探测之后,边界点被用来在平行坐标空间进行画线。每一个边界点会画两条线,一条在中间轴和左边轴之间,另一条在中间轴和右边轴之间。我们使用一种混合添加的方式使线段的交点变得更亮。在一片区域内最亮的点代表了线段。
举例来说,我们可以从这张测试图片开始:

下面是我们在平行坐标空间中得到的 (我已经将负值对称过来使图片高度减半)

图中的亮点就是我们探测到线段的地方。进行一个非最大值转化来找到区域最值并将其他地方变为黑色。然后,点被转化回线段的斜率和截距,得到下面的结果:

我必须指出在 GPUImage 中这个非最大值转换过程是一个薄弱的环节。它可能会导致错误的探测出线段,或者在有噪点的地方将一条线段探测为多条线段。
正如之前所提到的,线段探测有许多有趣的应用。其中一种就是条形码识别。有关平行坐标空间转换有趣的一点是,在真实空间中平行的线段转换到平行坐标空间中后是垂直对齐的一排点。不论平行线段是怎样的都一样。这就意味着你可以通过一排有特定顺序间距的点来探测出条形码无论条形码是怎样摆放的。这对于有视力障碍的手机用户进行条形码扫描是有巨大帮助的,毕竟他们无法看到盒子也很难将条形码对齐。
对我而言,这种线段探测过程中的几何学优雅是令我感到十分着迷的,我希望将它介绍给更多开发者。
小结
这些就是在过去几年中发展出来的机器视觉方法中的几个,它们仅仅是适合在 GPU 上工作的方法中的一部分。我个人认为在这个领域还有着令人激动的开创性工作要去做,这将会诞生可以提高许多人生活质量的应用。希望这篇文章至少为你提供了一个机器视觉领域简要的总体介绍,并且展示了这个领域并不像许多开发者想象的那样无法进入。
参考文献
- I. Sobel. An Isotropic 3x3 Gradient Operator, Machine Vision for Three-Dimensional Scenes, Academic Press, 1990.
- J.M.S. Prewitt. Object Enhancement and Extraction, Picture processing and Psychopictorics, Academic Press, 1970.
- J. Canny. A Computational Approach To Edge Detection, IEEE Trans. Pattern Analysis and Machine Intelligence, 8(6):679–698, 1986.
- A. Ensor, S. Hall. GPU-based Image Analysis on Mobile Devices. Proceedings of Image and Vision Computing New Zealand 2011.
- C. Harris and M. Stephens. A Combined Corner and Edge Detector. Proc. Alvey Vision Conf., Univ. Manchester, pp. 147-151, 1988.
- J. Shi and C. Tomasi. Good features to track. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 593-600, June 1994.
- A. Noble. Descriptions of Image Surfaces. PhD thesis, Department of Engineering Science, Oxford University 1989, p45.
- G. Ziegler, A. Tevs, C. Theobalt, H.-P. Seidel. GPU Point List Generation through HistogramPyramids. Research Report, Max-Planck-Institut fur Informatik, 2006.
- E. Rosten and T. Drummond. Machine learning for high-speed corner detection. European Conference on Computer Vision 2006.
- M. Dubská, J. Havel, and A. Herout. Real-Time Detection of Lines using Parallel Coordinates and OpenGL. Proceedings of SCCG 2011, Bratislava, SK, p. 7.
- M. Dubská, J. Havel, and A. Herout. PClines — Line detection using parallel coordinates. 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), p. 1489- 1494.