了解垃圾收集器
由于ElasticSearch是基于Java语言的应用,所以它必须运行在Java虚拟机上。任何Java程序都被编译成字节码,然后才能运行在JVM上。用最常规的方式思考,可以想象JVM只是执行其它的程序,并且控制程序的行为。但是除非你是在为ElasticSearch开发新的插件(这部分的内容将在第9章 开发ElasticSearch插件中论述),否则这不是你关注的重点。你需要关注的重点是垃圾收集器,JVM中负责内存管理的那部分。当一个对象不再被程序用到时,用垃圾收集器可以将对象从内存中删除,当内存不足时,垃圾收集器就开始工作。在本章,我们将学习如何配置垃圾收集器,如果避免内存交换,如何记录垃圾收集器的工作日志,如何利用垃圾收集器诊断程序的问题,最后将会学习几种Java工具的使用。


读者可以从互联网上了解关于Java虚拟机架构的更多信息,比如,在维基百科: http://en.wikipedia.org/wiki/Java\_virtual\_machine
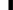
Java内存模型
当我们用Xms和Xmx参数(或者ES_MIN_MEN和ES_MAX_MEM属性)来设定内存的容量时,实际上就是指定了Java虚拟机堆内存的最大值和最小值。堆内存是为Java程序预留的空间,所谓的Java程序在本文中即ElasticSearch节点。一个Java程序能够使用的堆内存绝对不会超过Xmx属性(或者ES_MAX_MEM属性)中设定的内存值。当程序新创建一个java对象,这个对象就存储在了堆内存中。如果长时间该对象没有被引用,垃圾收集器就会从堆内存中删除该对象,回收内存空间,给后来的对象使用。可以设想,如果没有足够的堆内存空间给java应用程序来生成对象,程序运行就会出问题,比如JVM就会抛出OutOfMemory异常,这个异常表明程序的内存使用出错了,原因可能是堆内存空间不足,或者程序出现内存溢出,没有释放无用的对象。
JVM的内存被划分成如下的区域:
- Eden区域:堆内存的一部分,JVM启动时,绝大多数的对象都分配到该区域。
- Survivor区域:堆内存的一部分,存储Eden区经过垃圾收集器扫描后幸存的对象。Survivor区分成survivor 0区和survivor 1区两个部分
- tenured geneneration:堆内存的一部分,存储在survivor区幸存一段时间的对象。
- Permanent generation:非堆内存区域,存储虚拟机自己的数据,比如生成对象的类和方法。
- 代码缓存区:非堆内存区域,在HotSpot JVM中用于编译和存储本地方法。
上面的分类方法比较简单。eden区域和survivor区域合称为young generation。tenured geneneration又称为old generation。 (译者注:原文讲解Java的内存模型不并清晰直观,Java内存模型核心在堆内存,堆内存区域的划分要结合垃圾回收算法来理解才好理解这样做的原因,可以参考《深入理解Java虚拟机 JVM最佳特性与高级实践》一书)。
java对象的生存周期和垃圾回收过程
我们来通过一个简单Java对象的生命周期来了解垃圾收集器的工作原理。
当Java应用程序创建一个Java对象时,该对象会生成在堆内存的young generation中,即eden区域。接下来,如果对象在对young generation区域进行的垃圾回收操作中幸存下来(表明该对象非一次性对象,接下来还会被用到),该对象会被移动到堆内存young generation的surivor区域(首先是survivor 0区域,垃圾回收完成后,会移动到survivor 1区域)。
在survivor 1区中幸存的对象会被移动到tenured generation堆内存中,该对象就成为old generation的一部分了,young generation 的垃圾收集器就无法回收该对象了。该对象就会一直存活到它使命的终点。即,它在等待着一下次的整个堆空间的垃圾回收将它收走,为新的对象腾出空间。
通过前面的描述,我们可以认为(实际也是如此),至少目前为止Java使用分代垃圾回收策略;对象经历的垃圾回收次数越多,它幸存的机会越大。基于此,我们可以认为:JVM中有两类垃圾收集器同时运行着:young generation垃圾收集器(又称minor)和old generation 垃圾收集器(又称major)。
应对垃圾收集引发的问题
在处理垃圾收集相关的问题时,首先要确定问题的根源在哪里。当然,这并不是一目了然的,通常需要系统管理员或者集群管理员费心费力。在本节,我们将展示两种观察和鉴定垃圾收集器问题的方法:一是在ElasticSearch中打开垃圾收集器的日志;另一种是使用jstat命令,该命令工具在绝大多数Java发行版本中都存在。
开启垃圾收集器的工作日志
当垃圾收集器运行一段时间后,在ElasticSearch中可以观察到周期现象。在elasticsearch.yml文件的默认配置项中,可以看到如下的配置项,默认是被注释的:
monitor.jvm.gc.ParNew.warn: 1000ms
monitor.jvm.gc.ParNew.info: 700ms
monitor.jvm.gc.ParNew.debug: 400ms
monitor.jvm.gc.ConcurrentMarkSweep.warn: 10s
monitor.jvm.gc.ConcurrentMarkSweep.info: 5s
monitor.jvm.gc.ConcurrentMarkSweep.debug: 2s
可以看到,配置项指定了三种层级的日志,并级每种层级日志设定了阈值。比如,对于info层级的日志,如果young generation垃圾回收的时间超过700ms,ElasticSearch就会把相关信息写入到日志中。对于old generation来说,回收时间超过5s才会写入到日志中。
日志中记录的信息如下:
[EsTestNode] [gc][ConcurrentMarkSweep][964][1] duration [14.8s],
collections [1]/[15.8s], total [14.8s]/[14.8s], memory [8.6gb]->[3.4gb]/[11.9gb], all_pools {[Code Cache] [8.3mb]->[8.3mb]/[48mb]}{[Par Eden Space] [13.3mb]
>[3.2mb]/[266.2mb]}{[Par Survivor Space] [29.5mb]
>[0b]/[33.2mb]}{[CMS Old Gen] [8.5gb]->[3.4gb]/[11.6gb]}{[CMS
Perm Gen] [44.3mb]->[44.2mb]/[82mb]}
可以看到,通过日志文件的内容,我们可以知道,这是关于ConcurrentMarkSweep垃圾收集器的日志信息,因此这是一次old generation区域的垃圾清除。我们可以了解到整个垃圾清除过程耗时14.8s。在垃圾收集器进行内存回收前,整个堆内存11.9gb已经使用了8.6gb。内存回收后,使用内存下降到了3.4gb。接下来,我们还可以看到更细致的统计信息,即垃圾收集器处理了堆内存中的如下区域:代码缓存区、eden space、survivor space、old generation 堆内存区,以及perm generation区域。
开启基于阈值记录日志的垃圾收集器工作日志后,只需通过日志信息可以查看系统是否工作正常。当然,如果想了解更多的细节信息,Java提供了一个新的工具,即jstat命令。
使用JStat
运行jstat命令来查看垃圾收集器的运行过程非常简单,命令如下:
jstat -gcutil 123456 2000 1000
-gcutil选项表明命令的任务是监控垃圾收集器的工作,123456是ElasticSearch运行的虚拟机的ID,2000代表采样的时间间隔(单位为毫秒),1000代表采样样本的数量。因此本例中,上述命令的执行时间将超过33分钟(2000 * 1000 / 1000 / 60)。
绝大多数情况下,虚拟机的ID与线程的ID相差不大,有时甚至就是线程ID,但是这不是绝对的。想要检测运行程序的Java进程号和虚拟机ID号,只需执行jps命令即可,绝大多数的Java虚拟机都支持该命令。样例命令如下:
jps
命令的结果如下:
16232 Jps
11684 ElasticSearch
从上面的结果中,可以看到每行以JVM ID开头,随后就是进程的名称。如果想了解更多关于jps命令的内容,可以参考Java文档:http://docs.oracle.com/javase/7/docs/technotes/tools/share/jps.html 。
还有一件事情需要记住,做虚拟机优化的目的在于实现多次小规模的回收行为,而非一次长时间的回收行为。这是因为对于应用来说,其性能应该是平稳的,垃圾收集器的工作对ElasticSearch应该是透明的(即感受不到它的存在)。当一次大规模的垃圾收集行为出现时,会导致整个虚拟机工作线程的暂停,这会导致查询变慢,而且会导致索引进程暂停。
调整ElasticSearch中垃圾收集器的行为
我们既然已经了解了垃圾收集器的工作原理和相关问题的对策,那么就有必要了解如何通过修改ElasticSearch启动参数来改变垃圾收集器运行方式。具体方案取决于ElasticSearch的启动方式。我们将介绍两种最常见方法:使用ElasticSearch内置的启动脚本以及使用service wrapper。
使用标准启动脚本
在使用标准的启动脚本时,我们需要把相关的JVM参数添加到JAVA_OPTS系统属性中。例如,如果我们希望添加-XX:+UseParNewGC -XX:+UseConcMarkSweepGC到类Linux操作系统的ElasticSearch启动参数中,我们应该添加如下的命令:
export JAVA_OPTS="-XX:+UseParNewGC -XX:+UseConcMarkSweepGC"
如果想检测参数是否生效,我们可以执行如下的命令:
echo $JAVA_OPTS
在本例中,这个命令应该返回如下的结果:
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC
Service Wrapper
在ElasticSearch中,可以用Java service wrapper(https://github.com/elasticsearch/elasticsearch-servicewrapper)以服务的方式安装service wrapper。如果使用service wrapper,那么设置JVM 参数的方式与前面的方法就会有所不同。 我们需要做的就是修改elasticsearch.conf文件,这个文件一般存在于/opt/elasticsearch/bin/service/(如果你的ElasticSearch安装目录是/opt/elasticsearch)。在前面提到的文件中,你将看到如下的参数:
set.default.ES_HEAP_SIZE=1024
wrapper.java.additional.1=-Delasticsearch-service
wrapper.java.additional.2=-Des.path.home=%ES_HOME%
wrapper.java.additional.3=-Xss256k
wrapper.java.additional.4=-XX:+UseParNewGC
wrapper.java.additional.5=-XX:+UseConcMarkSweepGC
wrapper.java.additional.6=-XX:CMSInitiatingOccupancyFraction=75
wrapper.java.additional.7=-XX:+UseCMSInitiatingOccupancyOnly
wrapper.java.additional.8=-XX:+HeapDumpOnOutOfMemoryError
wrapper.java.additional.9=-Djava.awt.headless=true
第一个属性用于设置ElasticSearch的堆内存容量,其它的都JVM相关的命令。如果要添加新的命令参数,只需要添加新的wrapper.java.additional,页面接一个圆点,再接上一个可用的数字即可,例如:
wrapper.java.additional.10=-server
需要记住的是,垃圾收集器调优工作并非一劳永逸。需要经过多次实验才能确定最优参数,最优参数取决于应用的数据、查询等多种因素。出现问题时不要怕修改参数会让事情变得更糟,相反要观察改变参数后ElasticSearch的运行状态。大胆调整,细心观察;这样才是系统调优的正确态度。
避免类Unix系统的swapping操作
尽管本节的内容与JVM垃圾收集和堆内存占用分析并没紧密的联系,但是了解如何关闭交换区对于系统调优至关重要。swapping是这样一个过程:当物理内存不足或者操作系统基于某些原因时,系统将部分内存数据写入到硬盘交换分区(只有基于Unix的操作系统才有此分区)的过程。如果被交换的内存页面需要再次用到,操作系统又重新将这部分的数据从交换分区回写到内存中,给线程使用。可以看出,这个过程不仅费时,而且消耗资源。
使用ElasticSearch时,我们必须避免内存数据被交换出内存。不难想象,如果ElasticSearch中用到的内存空间被写入到硬盘,接着又读入到内存中,这会造成搜索过程和索引过程的性能急剧下降。因此,ElasticSearch允许用户禁止相关的swap操作。在elasticsearch.yml文件中设置bootstrap.mlockall属性值true可以实现这一点。
但是这还只是第一步。还需要确保JVM的xmx和xms参数值相同(为ES_MIN_MEME和ES_MAX_MEM属性设置相同的值即可)。同时需要注意设置的数值不能超过物理内存的值。
接下来,如果我们运行ElasticSearch,则可以在日志中看到如下的内容:
[2013-06-11 19:19:00,858][WARN ][common.jna ]
Unknown mlockall error 0
这意味着我们的内存锁定功能没有生效。因此接下来,我们需要修改Linux操作系统中的两个文件(这需要管理员权限)。我们假定运行ElasticSearch的用户名为elasticsearch。
首先,修改/etc/security/limits.conf文件,添加如下的内容:
elasticsearch - nofile 64000
elasticsearch - memlock unlimited
接下来,修改/etc/pam.d/common-session文件,添加如下的内容:
session required pam_limits.so
重新使用es用户账号登录后,启动ElasticSearch就不会再有mlockall error信息了。