RAC 特殊问题和实战经验
共享存储
在需要将一个 LUN (逻辑单元号)映射给多个节点、为集群提供一个共享的存储卷时,同一个存储 LUN 在各个主机端的 LUNID 必须是相同的。比如:
- 在为多个 ESX 节点创建一个 VMFS 卷的时候
- 在双机 HA 集群创建共享存储的时候
时间一致性
集群模式下,各个节点要协同工作,因此,各主机的时间必须一致。因此,各主机的时间必须一致。各个节点之间的时间差不能超时,一般如果超过 30s,节点很可能会重启,所以要同步各节点的时间。例如,需要配置一个 ntp 时钟服务器,来给 RAC 的各个节点进行时间同步。或者让节点之间进行时间同步,保证各个节点的时间同步,但是无法保证 RAC 数据库的时间的准确性。
互联网络(或者私有网络、心跳线)
集群必须依赖内部的互联网络实现数据通讯或者心跳功能。因此,采用普通的以太网还是其他的高速网络(比如 IB),就很有讲究,当然了,还有拿串口线实现心跳信息传递。此外,采用什么样的网络参数对集群整体的性能和健壮性都大有关系。
案例:
XX 市,4 节点 Oracle 10g RAC
操作系统采用的是 RHEL 4,按照默认的安装文档,设置网络参数为如下值:
net.core.rmem_default = 262144
net.core.rmem_max = 262144执行一个查询语句,需要 11 分钟,修改参数:
net.core.rmem_default = 1048576
net.core.rmem_max = 1048576再次执行仅需 16.2 秒。
固件、驱动、升级包的一致性
案例:
XX 市,HPC 集群,运行 LS-DYNA(通用显示非线性有限元分析程序)。
集群存储系统的环境说明:存储系统的 3 个 I/O 节点通过 FC SAN 交换机连接到一个共享的存储。
- 节点使用的 FC HBA 卡为 Qlogic QLE2460;
- 光纤交换机为 Brocade 200E
- 磁盘阵列为 Dawning DS8313FF
故障现象
集群到货后发现盘阵与机器直连能通,两个设备接 200E 交换机不通。后经测试交换机 IOS 版本问题导致不能正常认出盘阵的光纤端口,与交换机的供货商联系更新了两次 IOS,盘阵的端口能正常识别,但盘阵与机器相连还是无法找到盘阵。经过今天的测试发现三台 I/O 节点采用的 HBA 卡 firmware 版本不一致。最早接光纤交换机及与盘阵直连的的 I/O1 的 firmware 为 v4.03.02,今天又拿出来的两台 I/O 节点 firmware 为 v4.06.03。用后两台测试后盘阵、机器、交换机之间可以正常通信,到今天晚上为止没有发现异常情况。从目前的情况判断是QLE2460 firmware 为 v4.03.01 的 HBA 卡与 200E IOS V5.3.1 有冲突者不兼容导致的故障。至于新的 HBA 卡 firmware为 v4.06.03 与 200E IOS V5.3.1 连接的稳定性如何还要做进一步测试。
诊断处理结果
I/O 1 节点 HBA 卡的 fimware 升级到 v4.06.03 后连接 200E 找不到盘阵的故障已经得到解决。其实是一个 FCHBA 卡的固件版本不一致引起的问题。
共享文件 OCR 及 VOTING DISK
Oracle Cluster Registry(OCR):记录 OCR 记录节点成员的配置信息,如 database、ASM、instance、 listener、VIP 等 CRS 资源的配置信息,可存储于裸设备或者群集文件系统上。Voting disk : 即仲裁盘,保存节点的成员信息,当配置多个投票盘的时候个数必须为奇数,每个节点必须同时能够连接半数以上的投票盘才能够存活。初次之外包含哪些节点成员、节点的添加和删除信息。
安装
在 Oracle RAC 中,软件不建议安装在共享文件系统上,包括 CRS_HOME 和 ORACLE_HOME,尤其是 CRS 软件,推荐安装在本地文件系统中,这样在进行软件升级,以及安装 patch 和 patchset 的时候可以使用滚动升级(rolling upgrade)的方式,减少计划当机时间。另外如果软件安装在共享文件系统也会增加单一故障点。如果使用 ASM 存储,需要为 asm 单独安装 ORACLE 软件,独立的 ORACLE_HOME,易于管理和维护,比如当遇到 asm 的 bug 需要安装补丁时,就不会影响 RDBMS 文件和软件。
脑裂症(SPLIT BRAIN)
在一个共享存储的集群中,当集群中 heartbeat 丢失时,如果各节点还是同时对共享存储去进行操作,那么在这种情况下所引发的情况是灾难的。ORACLE RAC 采用投票算法来解决这个问题,思想是这样的:每个节点都有一票,考虑有 A,B,C 三个节点的集群情形,当 A 节点由于各种原因不能与 B,C 节点通信时,那么这集群分成了两个 DOMAIN,A 节点成为一个 DOMAIN,拥有一票;B,C 节点成为一个 DOMAIN 拥有两票,那么这种情况B,C 节点拥有对集群的控制权,从而把 A 节点踢出集群,对要是通 IO FENCING 来实现。如果是两节点集群,则引入了仲裁磁盘,当两个节点不能通信时,请求最先到达仲裁磁盘的节点拥用对集群的控制权。网络问题(interconnect 断了),时间不一致;misscount 超时 等等,才发生 brain split,而此时为保护整个集群不受有问题的节点影响,而发生 brain split。oracle 采用的是 server fencing,就是重启有问题的节点,试图修复问题。当然有很多问题是不能自动修复的。比如时间不一致,而又没有 ntp;网线坏了。。。这些都需要人工介入修复问题。而此时的表现就是有问题的节点反复重启。
集群软件
从 Oracle10g 起,Oracle 提供了自己的集群软件,叫做 Oracle Clusterware,简称 CRS,这个软件是安装 oraclerac 的前提,而上述第三方集群则成了安装的可选项 。同时提供了另外一个新特性叫做 ASM,可以用于 RAC 下的共享磁盘设备的管理,还实现了数据文件的条带化和镜像,以提高性能和安全性 (S.A.M.E: stripe and mirroreverything ) ,不再依赖第三方存储软件来搭建 RAC 系统。尤其是 Oracle11gR2 版本不再支持裸设备,Oracle 将全力推广 ASM,彻底放弃第三方集群组件支持。
ORACLE CLUSTERWARE 的心跳
Oracle Clusterware 使用两种心跳设备来验证成员的状态,保证集群的完整性。
- 一是对 voting disk 的心跳,ocssd 进程每秒向 votedisk 写入一条心跳信息。
- 二是节点间的私有以太网的心跳。 两种心跳机制都有一个对应的超时时间,分别叫做 misscount 和 disktimeout:
- misscount 用于定义节点间心跳通信的超时,单位为秒;
- disktimeout ,默认 200 秒,定义 css 进程与 vote disk 连接的超时时间;
reboottime ,发生裂脑并且一个节点被踢出后,这个节点将在 reboottime 的时间内重启;默认是 3 秒 用下面的命令查看上述参数的实际值:
# crsctl get css misscount# grep misscount $CRS_HOME/log/hostname/cssd/ocssd.log
在下面两种情况发生时,css 会踢出节点来保证数据的完整:
(一) Private Network IO time > misscount,会发生 split brain 即裂脑现象,产生多个“子集群”(subcluster) ,这些子集群进行投票来选择哪个存活,踢出节点的原则按照下面的原则:节点数目不一致的,节点数多的 subcluster 存活;节点数相同的,node ID 小的节点存活。
(二) VoteDisk I/O Time > disktimeout ,踢出节点原则如下:失去半数以上 vote disk 连接的节点将在 reboottime 的时间内重启。例如有 5 个 vote disk,当由于网络或者存储原因某个节点与其中>=3 个 vote disk 连接超时时,该节点就会重启。当一个或者两个 vote disk 损坏时则不会影响集群的运行。
如何查看现有系统的配置
对于一个已经有的系统,可以用下面几种方法来确认数据库实例的心跳配置,包括网卡名称、IP 地址、使用的网络协议。
最简单的方法,可以在数据库后台报警日志中得到。使用 oradebug
SQL> oradebug setmypid
Statement processed.
SQL> oradebug ipc
Information written to trace file.
SQL> oradebug tracefile_name
/oracle/admin/ORCL/udump/orcl2_ora_24208.trc找到对应 trace 文件的这一行:socket no 7 IP 10.0.0.55 UDP 16878
从数据字典中得到:
SQL> select * from v$cluster_interconnects;
SQL> select * from x$ksxpia;
心跳调优和设置
为了避免心跳网络成为系统的单一故障点,简单地我们可以使用操作系统绑定的网卡来作为 Oracle 的心跳网络,以 AIX 为例,我们可以使用 etherchannel 技术,假设系统中有 ent0/1/2/3 四块网卡,我们绑定 2 和 3 作为心跳:在 HPUX 和 Linux 对应的技术分别叫 APA 和 bonding。
UDP 私有网络的调优当使用 UDP 作为数据库实例间 cache fusion 的通信协议时,在操作系统上需要调整相关参数,以提高 UDP 传输效率,并在较大数据时避免出现超出 OS 限制的错误:
- UDP 数据包发送缓冲区:大小通常设置要大于(db_block_size * db_multiblock_read_count )+4k,
- UDP 数据包接收缓冲区:大小通常设置 10 倍发送缓冲区;
- UDP 缓冲区最大值:设置尽量大(通常大于 2M)并一定要大于前两个值;
各个平台对应查看和修改命令如下:
Solaris 查看 ndd /dev/udp udp_xmit_hiwat udp_recv_hiwat udp_max_buf ;
修改 ndd -set /dev/udp udp_xmit_hiwat 262144
ndd -set /dev/udp udp_recv_hiwat 262144
ndd -set /dev/udp udp_max_buf 2621440
AIX 查看 no -a |egrep “udp_|tcp_|sb_max”
修改 no -p -o udp_sendspace=262144
no -p -o udp_recvspace=1310720
no -p -o tcp_sendspace=262144
no -p -o tcp_recvspace=262144
no -p -o sb_max=2621440
Linux 查看 文件/etc/sysctl.conf
修改 sysctl -w net.core.rmem_max=2621440
sysctl -w net.core.wmem_max=2621440
sysctl -w net.core.rmem_default=262144
sysctl -w net.core.wmem_default=262144
HP-UX 不需要
HP TRU64 查看 /sbin/sysconfig -q udp
修改: 编辑文件/etc/sysconfigtab
inet: udp_recvspace = 65536
udp_sendspace = 65536
Windows 不需要锁
LOCK(锁)是用来控制并发的数据结构,如果有两个进程同时修改同一个数据, 为了防止出现混乱和意外,用锁来控制访问数据的次序。有锁的可以先访问,另外一个进程要等到第一个释放了锁,才能拥有锁,继续访问。总体来说,RAC 里面的锁分两种, 一种是本地主机的进程之间的锁,另外一种是不同主机的进程之间的锁。本地锁的机制有两类,一类叫做 lock(锁),另外一类叫做 latch 闩。
全局锁就是指 RAC lock,就是不同主机之间的锁,Oracle 采用了 DLM(Distributed Lock Management,分布式锁管理)机制。在 Oracle RAC 里面,数据是全局共享的,就是说每个进程看到的数据块都是一样的,在不同机器间,数据块可以传递。给出了 GRD目录结构。
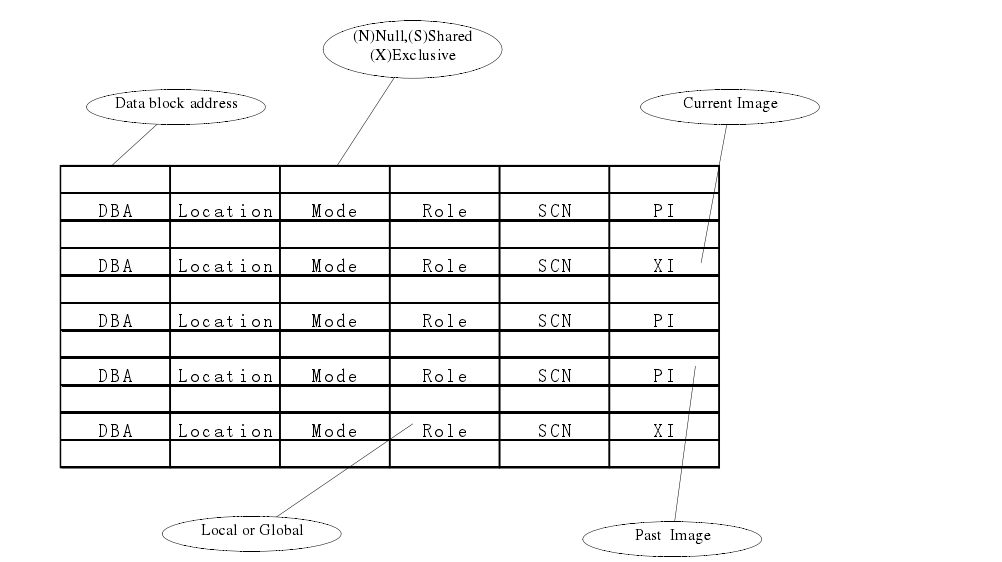
可以看出 Mode、Role、n 构成了 RAC lock 的基本结构
- Mode 有 N、S、X3 种方式
- Role 有 Local 和 Global 两种
- N 有 PI 和 XI 两种,一般 0 表示 XI,1 表示 PI
- 全局内存管理
- RAC 中的数据库文件
- RAC 中读的一致性
- 群集就绪服务(CRS)
- 全局资源目录
一致性管理
数据一致性和并发性描述了 Oracle 如何维护多用户数据库环境中的数据一致性问题。在单用户数据库中,用户修改数据库中的数据,不用担心其他用户同时修改相同的数据。但是,在多用户数据库中,同时执行的多个事务中的语句可以修改同一数据。同时执行的事务需要产生有意义的和一致性的结果。因而,在多用户数据库中,数据并发性和数据一致性的控制非常重要:数据并发性:每个用户可以看到数据的一致性结果。ANSI/IOS SQL 标准(SQL 92)定义了 4 个事务隔离级别,对事务处理性能的影响也个不相同。这些隔离级别是考虑了事务并发执行必须避免的 3 个现象提出的。3 个应该避免的现象为:
- 脏读:一个事务可以读取其他事务写入但还没有提交的数据。
- 不可重复读(模糊读):一个事务重复读到以前读到的和查询到的数据,这些数据是其他的已提交事务已经修改或者删除的数据。
- 幻影读:一个事务重复运行查询返回的一些列行,这些行包括其他已经提交的事务已经插入的额外的行。
SQL92 根据这些对象定义了 4 个隔离级别,事务运行在特定的隔离级别允许特别的一些表现。如下表表示隔离级别阻止的读现象。
