正则表达式
正则表达式是对字符串的结构进行的形式化描述,非常简洁优美,而且功能十分强大。很多的语言都不同程度的支持正则表达式,而在很多的文本编辑器如 Emacs,vim,UE 中,都支持正则表达式来进行字符串的搜索替换工作。UNIX 下的很多命令行程序,如 awk,grep,find 更是对正则表达式有良好的支持。
JavaScript 同样也对正则表达式有很好的支持,RegExp 是 JavaScript 中的内置“类”,通过使用RegExp,用户可以自己定义模式来对字符串进行匹配。而 JavaScrip t中的 String 对象的 replace 方法也支持使用正则表达式对串进行匹配,一旦匹配,还可以通过调用预设的回调函数来进行替换。
正则表达式的用途十分广泛,比如在客户端的 JavaScript 环境中的用户输入验证,判断用户输入的身份证号码是否合法,邮件地址是否合法等。另外,正则表达式可用于查找替换工作,首先应该关注的是正则表达式的基本概念。
关于正则表达式的完整内容完全是另外一个主题了,事实上,已经有很多本专著来解释这个主题,限于篇幅,我们在这里只关注 JavaScript 中的正则表达式对象。
正则表达式基础概念
本节讨论正则表达式中的基本概念,这些基本概念在很多的正则表达式实现中是一致的,当然,细节方面可能会有所不同,毕竟正则表达式是来源于数学定义的,而不是程序员。JavaScriipt 的正则表达式对象实现了 perl 正则表达式规范的一个子集,如果你对 perl 比较熟悉的话,可以跳过这个小节。脚本语言 perl 的正则表达式规范是目前广泛采用的一个规范,Java 中的 regex 包就是一个很好的例子,另外,如 vim 这样的应用程序中,也采用了该规范。
元字符与特殊字符
元字符,是一些数学符号,在正则表达式中有特定的含义,而不仅仅表示其“字面”上的含义,比如星号(*),表示一个集合的零到多次重复,而问号(?)表示零次或一次。如果你需要使用元字符的字面意义,则需要转义。
下面是一张元字符的表:
| 元字符 | 含义 |
|---|---|
| ^ | 串的开始 |
| $ | 串的结束 |
| * | 零到多次匹配 |
| + | 一到多次匹配 |
| ? | 零或一次匹配 |
| \b | 单词边界 |
特殊字符,主要是指注入空格,制表符,其他进制(十进制之外的编码方式)等,它们的特点是以转义字符()为前导。如果需要引用这些特殊字符的字面意义,同样需要转义。
下面为转移字符的一张表:
| 字符 | 含义 |
|---|---|
| 字符本身 | 匹配字符本身 |
| \r | 匹配回车 |
| \n | 匹配换行 |
| |t制表符 | |
| \f | 换页 |
| \x# | 匹配十六进制数 |
| \cX | 匹配控制字符 |
范围及重复
我们经常会遇到要描述一个范围的例子,比如,从 0 到 3 的数字,所有的英文字母,包含数字,英文字母以及下划线等等,正则表达式规定了如何表示范围:
| 标志符 | 含义 |
|---|---|
| […] | 在集合中的任一个字符 |
| [^…] | 不在集合中的任一个字符 |
| . | 出\n之外的任一个字符 |
| \w | 所有的单字,包括字母,数字及下划线 |
| \W | 不包括所有的单字,\w的补集 |
| \s | 所有的空白字符,包括空格,制表符 |
| \S | 所有的非空白字符 |
| \d | 所有的数字 |
| \D | 所有的非数字 |
| \b | 退格字符 |
结合元字符和范围,我们可以定义出很强大的模式来,比如,一个简化版的匹配 Email 的正则表达是为:
var emailval = /^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$/;
emailval.test("kmustlinux@hotmail.com");//true
emailval.test("john.abruzzi@pl.kunming.china");//true
emailval.test("@invalid.com");//false,不合法[\w-]表示所有的字符,数字,下划线及减号,[\w-]+ 表示这个集合最少重复一次,然后紧接着的这个括号表示一个分组(分组的概念参看下一节),这个分组的修饰符为星号(*),表示重复零或多次。这样就可以匹配任意字母,数字,下划线及中划线的集合,且至少重复一次。
而@符号之后的部分与前半部分唯一不同的是,后边的一个分组的修饰符为(+),表示至少重复一次,那就意味着后半部分至少会有一个点号(.),而且点号之后至少有一个字符。这个修饰主要是用来限制输入串中必须包含域名。 最后,脱字符(^)和美元符号($)限制,以……开始,且以……结束。这样,整个表达式的意义就很明显了。
再来看一个例子:在 C/Java 中,变量命名的规则为:以字母或下划线开头,变量中可以包含数字,字母以及下划线(有可能还会规定长度,我们在下一节讨论)。这个规则描述成正则表达式即为下列的定义:
var variable = /[a-zA-Z_][a-zA-Z0-9_]*/;
print(variable.test("hello"));
print(variable.test("world"));
print(variable.test("_main_"));
print(variable.test("0871"));将会打印:
true
true
true
false前三个测试字符均为合法,而最后一个是数字开头,因此为非法。应该注意的是,test 方法只是测试目标串中是否有表达式匹配的部分,而不一定整个串都匹配。比如上例中:
print(variable.test("0871_hello_world"));//true
print(variable.test("@main"));//true同样返回 true,这是因为,test 在查找整个串时,发现了完整匹配 variable 表达式的部分内容,同样也是匹配。为了避免这种情况,我们需要给 variable 做一些修改:
var variable = /^[a-zA-Z_][a-zA-Z0-9_]*$/;通过加推导(+),星推导(*),以及谓词,我们可以灵活的对范围进行重复,但是我们仍然需要一种机制来提供诸如 4 位数字,最多 10 个字符等这样的精确的重复方式。这就需要用到下表中的标记:
| 标记 | 含义 |
|---|---|
| {n} | 重复n次 |
| {n,} | 重复n或更多次 |
| {n,m} | 重复至少n次,至多m次 |
有了精确的重复方式,我们就可以来表达如身份证号码,电话号码这样的表达式,而不用担心出做,比如:
var pid = /^[\d{15}|\d{18}]$/;//身份证
var mphone = /\d{11}/;//手机号码
var phone = /\d{3,4}-\d{7,8}/;//电话号码
mphone.test("13893939392");//true
phone.test("010-99392333");//true
phone.test("0771-3993923");//true 分组与引用
在正则表达式中,括号是一个比较特殊的操作符,它可以有三中作用,这三种都是比较常见的:
第一种情况,括号用来将子表达式标记起来,以区别于其他表达式,比如很多的命令行程序都提供帮助命令,键入 h 和键入 help 的意义是一样的,那么就会有这样的表达式:
h(elp)?//字符h之后的elp可有可无这里的括号仅仅为了将elp自表达式与整个表达是隔离(因为h是必选的)。
第二种情况,括号用来分组,当正则表达式执行完成之后,与之匹配的文本将会按照规则填入各个分组,比如,某个数据库的主键是这样的格式:四个字符表示省份,然后是四个数字表示区号,然后是两位字符表示区县,如 yunn0871cg 表示云南省昆明市呈贡县(当然,看起来的确很怪,只是举个例子),我们关心的是区号和区县的两位字符代码,怎么分离出来呢?
var pattern = /\w{4}(\d{4})(\w{2})/;
var result = pattern.exec("yunn0871cg");
print("city code = "+result[1]+", county code = "+result[2]);
result = pattern.exec("shax0917cc");
print("city code = "+result[1]+", county code = "+result[2]);正则表达式的 exec 方法会返回一个数组(如果匹配成功的话),数组的第一个元素(下标为 0)表示整个串,第一个元素为第一个分组,第二个元素为第二个分组,以此类推。因此上例的执行结果即为:
city code = 0871, county code = cg
city code = 0917, county code = cc第三种情况,括号用来对引用起辅助作用,即在同一个表达式中,后边的式子可以引用前边匹配的文本,我们来看一个非常常见的例子:我们在设计一个新的语言,这个语言中有字符串类型的数据,与其他的程序设计语言并无二致,比如:
var str = "hello, world";
var str = 'fair enough'; 均为合法字符,我们可能会设计出这样的表达式来匹配该声明:
var pattern = /['"][^'"]*['"]/; 看来没有什么问题,但是如果用户输入:
var str = 'hello, world";
var str = "hello, world'; 我们的正则表达式还是可以匹配,注意这两个字符串两侧的引号不匹配!我们需要的是,前边是单引号,则后边同样是单引号,反之亦然。因此,我们需要知道前边匹配的到底是“单”还是“双”。这里就需要用到引用,JavaScript 中的引用使用斜杠加数字来表示,如\1表示第一个分组(括号中的规则匹配的文本),\2表示第二个分组,以此类推。因此我们就设计出了这样的表达式:
var pattern = /(['"])[^'"]*\1/; 在我们新设计的这个语言中,为了某种原因,在单引号中我们不允许出现双引号,同样,在双引号中也不允许出现单引号,我们可以稍作修改即可完成:
var pattern = /(['"])[^\1]*\1/;这样,我们的语言中对于字符串的处理就完善了。
使用正则表达式
创建一个正则表达式有两种方式,一种是借助 RegExp 对象来创建,另一种方式是使用正则表达式字面量来创建。在 JavaScript 内部的其他对象中,也有对正则表达式的支持,比如 String 对象的 replace,match 等。我们可以分别来看:
创建正则表达式
使用字面量:
var regex = /pattern/; 使用 RegExp 对象:
var regex = new RegExp("pattern", switchs);而正则表达式的一般形式描述为:
var regex = /pattern/[switchs];这里的开关(switchs)有以下三种:
| 修饰符 | 描述 |
|---|---|
| i | 忽略大小写开关 |
| g | 全局搜索开关 |
| m | 多行搜索开关(重定义^与$的意义) |
比如,/java/i 就可以匹配 java/Java/JAVA,而 /java/ 则不可。而 g 开关用来匹配整个串中所有出现的子模式,如 /java/g 匹配”javascript&java”中的两个”java”。而 m 开关定义是否多行搜索,比如:
var pattern = /^javascript/;
print(pattern.test("java\njavascript"));//false
pattern = /^javascript/m;
print(pattern.test("java\njavascript"));//trueRegExp 对象的方法:
| 方法名 | 描述 |
|---|---|
| test() | 测试模式是否匹配 |
| exec() | 对串进行匹配 |
| compile() | 编译正则表达式 |
RegExp 对象的 test 方法用于检测字符串中是否具有匹配的模式,而不关心匹配的结果,通常用于测试,如上边提到的例子:
var variable = /[a-zA-Z_][a-zA-Z0-9_]*/;
print(variable.test("hello"));//true
print(variable.test("world"));//true
print(variable.test("_main_"));//true
print(variable.test("0871"));//false而 exec 则通过匹配,返回需要分组的信息,在分组及引用小节中我们已经做过讨论,而 compile 方法用来改变表达式的模式,这个过程与重新声明一个正则表达式对象的作用相同,在此不作深入讨论。
String 中的正则表达式
除了正则表达式对象及字面量外,String 对象中也有多个方法支持正则表达式操作,我们来通过例子讨论这些方法:
| 方法 | 作用 |
|---|---|
| match | 匹配正则表达式,返回匹配数组 |
| replace | 替换 |
| split | 分割 |
| search | 查找,返回首次发现的位置 |
var str = "life is very much like a mirror.";
var result = str.match(/is|a/g);
print(result);//返回[“is”, “a”]这个例子通过 String 的 match 来匹配 str 对象,得到返回值为[“is”, “a”]的一个数组。
var str = "<span>Welcome, John</span>";
var result = str.replace(/span/g, "div");
print(str);
print(result);得到结果:
<span>Welcome, John</span>
<div>Welcome, John</div> 也就是说,replace 方法不会影响原始字符串,而将新的串作为返回值。如果我们在替换过程中,需要对匹配的组进行引用(正如之前的\1,\2方式那样),需要怎么做呢?还是上边这个例子,我们要在替换的过程中,将 Welcome 和 John 两个单词调换顺序,编程 John, Welcome:
var result = str.replace(/(\w+),\s(\w+)/g, "$2, $1");
print(result);可以得到这样的结果:
<span>John, Welcome</span> 因此,我们可以通过$n来对第 n 个分组进行引用。
var str = "john : tomorrow :remove:file";
var result = str.split(/\s*:\s*/);
print(str);
print(result);得到结果:
john : tomorrow :remove:file
john,tomorrow,remove,file注意此处 split 方法的返回值 result 是一个数组。其中包含了 4 个元素。
var str = "Tomorrow is another day";
var index = str.search(/another/);
print(index);//12 search 方法会返回查找到的文本在模式中的位置,如果查找不到,返回-1。
实例:JSFilter
本小节提供一个实例,用以展示在实际应用中正则表达式的用途,当然,一个例子不可能涵盖所有的内容,只是一个最常见的场景。
考虑这样一种情况,我们在UI上为用户提供一种快速搜索的能力,使得随着用户的键入,结果集不断的减少,直到用户找到自己需要的关键字对应的栏目。在这个过程中,用户可以选择是否区分大小写,是否全词匹配,以及高亮一个记录中的所有匹配。
显然,正则表达式可以满足这个需求,我们在这个例子中忽略掉诸如高亮,刷新结果集等部分,来看看正则表达式在实际中的应用:
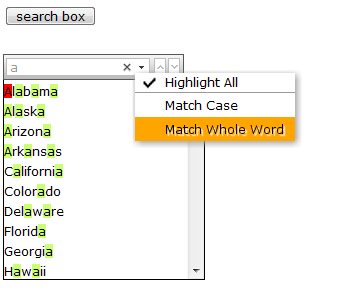
图1 在列表中使用 JSFilter(结果集随用户输入而变化)
来看一个代码片段:
this.content.each(function(){
var text = $(this).text();
var pattern = new RegExp(keyword, reopts);
if(pattern.test(text)){
var item = text.replace(pattern, function(t){
return "<span class=\""+filterOptions.highlight+"\">"+t+"</span>";
});
$(this).html(item).show();
}else{//clear previous search result
$(this).find("span."+filterOptions.highlight).each(function(){
$(this).replaceWith($(this).text());
});
}
});其中,content 是结果集,是一个集合,其中的每一个项目都可能包含用户输入的关键字,keyword 是用户输入的关键字序列,而 reopts 为正则表达式的选项,可能为(i,g,m),each 是 jQuery 中的遍历集合的方式,非常方便。程序的流程是这样的:
- 进入循环,取得结果集中的一个值作为当前值
- 使用正则表达式对象的test方法进行测试
- 如果测试通过,则高亮标注记录中的关键字
- 否则跳过,进行下一条的检测
遍历完所有的结果集,生成了一个新的,高亮标注的结果集,然后将其呈现给用户。而且可以很好的适应用户的需求,比如是否忽略大小写检查,是否高亮所有,是否全词匹配,如果自行编写程序进行分析,则需要耗费极大的时间和精力。

图2 在表格中使用 JSFilter(不减少结果集)