拓扑模式
这个文档描述了一些 NSQ 模式,解决不同的问题。
免责申明: 已经有一些明显的技术建议,但是这个文档通常会忽略,深层的个人选择合适工具的细节,获取软件安装到生产环境,管理服务在哪里运行,服务配置,并管理运行进程 (daemontools ,supervisord,init.d等等)。
指标收集
无论你编译的是哪个类型的 Web 服务,多数情况下你会想收集各种指标,来了解你的基础架构,你的用户,你的业务。
对于 Web 服务,多数指标是由 HTTP 请求事件产生的,比如 API。本地的方法可能会结构化这个异步操作,通过 API 请求直接写到你的指标系统。
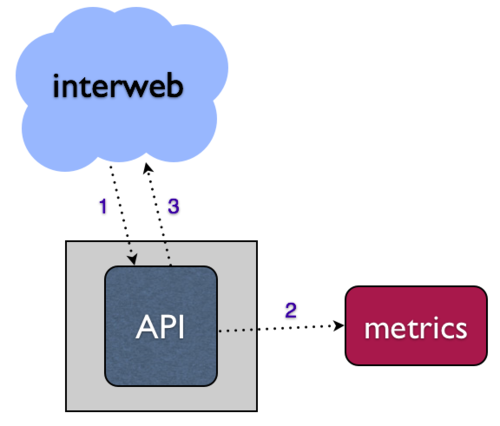
- 当你的指标系统下降的时候会发生什么?
- 你的 API 请求是否挂起和/或失败?
- 你如何处理增长 API 请求挑战?
解决这些问题的一个方法是设法异步写入到你的指标系统,就是说,将数据放到本地队列中,并通过其他进程写到你的下行系统(消费这个队列)。这个独立操作让系统更加健壮,容错性更强。在 bitly,我们使用 NSQ 完成这个目标。
NSQ 有话题(topic)和通道(channel)两个概念。假设将话题当做消息的唯一流(如同我们的 API 事件流)。假设,将通道当做这个消息流的指定消费者集合的拷贝。话题和通道都是独立队列。这些特性允许 NSQ 支持多播(话题拷贝每个消息到 N 通道)并且分发消息投递(通道平分它的消息到 N 个消费)。
更多细节参考design doc 和 slides from our Golang NYC talk,尤其 slides 19 through 33 描述了话题(topic)和通道(channel)的细节。
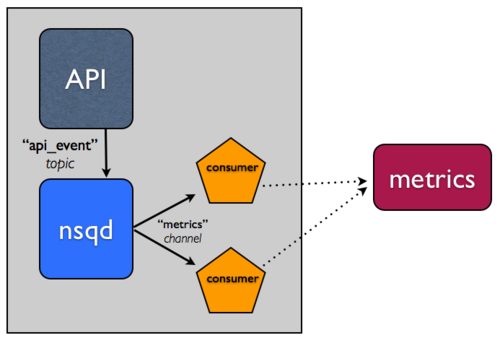
完整的 NSQ 比较简单,注意两点:
- 在 API 应用所运行的主机上,运行
nsqd实例。 - 更新你的 API 应用,写到本地
nsqd实例队列事件,而不是写到指标系统。能够容易的内审和操作流,我们通常将数据格式化为 line-oriented JSON。写到nsqd可以简单的执行一个 HTTP post 请求到/put端点。 - 用 client libraries 在你的语言创建一个消费者。这个"工作者"将会订阅数据流,并会处理事件,写到你的指标系统。它也能运行在主机上,运行你的 API 应用和
nsqd。
这有一个使用官方Python client library 写的例子:
除了解耦之外,通过使用我们官方的客户端库,当消息处理错误的时候,消费者可以优雅的降级。我们的库有 2 个关键特性:
- 重试 - 当你的消息处理函数返回失败,这个消息将会以
REQ(re-queue) 命令形式发送给nsqd。同时,如果在时间窗里消息还没被响应,nsqd将会自动将消息超时(并重新队列)。这两个特性对于消息投递保障非常关键。 - Backoff指数 - 当消息处理失败,读取库将会延迟附加信息的收据,放大建立在 # 连续的失败指数。当读取者处于 backoff 状态,并且开始处理成功,直到为 0 时,会发生相反序列.
从概念上来说,这两个特性允许系统优雅的自动响应下行失败。
持久化
好,现在你可以应付你的指标系统因为没有数据并且没有 degraded 的 API 服务到其他端点,导致的不可用。你也可以通过从同一个通道(channel)添加更多的工作实例给消费者,放大这个流系统的水平线。
但是,提前想清楚所有的 API 事件的指标,也不太可能。
是否有数据流系统的 log,能满足未来任何操作?日志会很容易导致冗余备份,可以把它作为 downstream 系统发生灾难时的 "plan z"。但是,你会希望消费者来完成消息数据的备份?也许不是,因为这是整个 "separation of concerns" 的事情。
归档 NSQ 话题(topic)非常常见,所以我们建了一个工具,nsq_to_file(使用 NSQ 打包),你可用它来完成。
记住,在 NSQ 中,每个话题(topic)的通道(channel)是独立的,并且接收所有消息的拷贝。你可以利用这个特性,来完成流的归档。实际上,这意味着如果你的指标系统已经有这些问题,并且 metrics 通道得到支持,它就不会影响到独立的 archive 通道,你将会持久化消息到磁盘。
所以,添加一个 nsq_to_file 实例到同一个主机,并且使用命令行如下:
/usr/local/bin/nsq_to_file --nsqd-tcp-address=127.0.0.1:4150 --topic=api_requests --channel=archive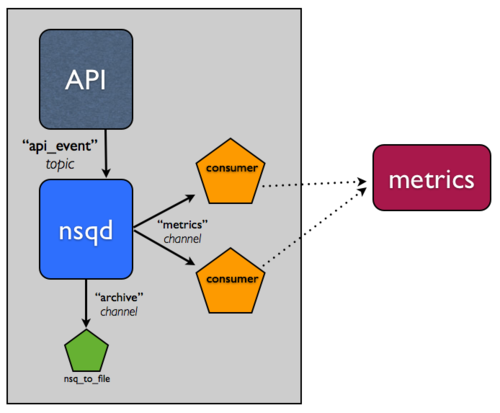
分布式系统
可能你已经注意到了,目前系统还没有超出单机,这是明显的错误。
不幸的是,要建立一个分布式系统很难。幸运的是,NSQ 可以帮助你。底下的改变演示了 NSQ 如何减轻建立分布式系统的痛苦,以及如何完成高可用性和容错。
假设这个事件流非常重要。你希望能容忍主机错误,并保证消息最终能到归档,所以你增加了另一个主机。
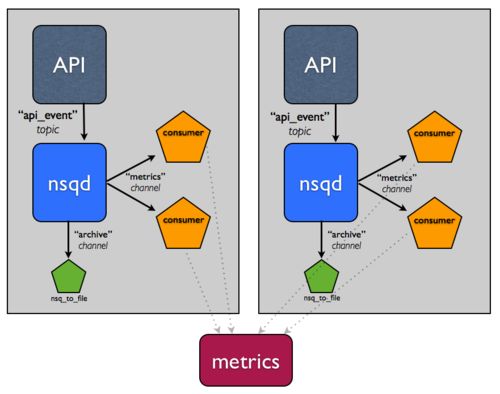
假设你已经在这两个主机间负载平衡,这样你就可以容忍单个主机错误。
现在,我们觉的持久化处理,压缩,传输这些日志会影响性能。如何切割这些责任到这些主机上,让它们拥有更高的 IO 能力?
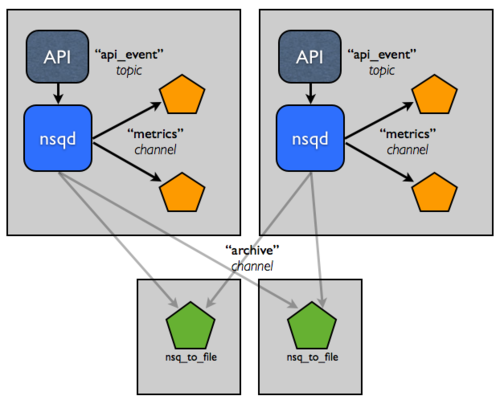
这个拓扑结构和配置可以容易放大到双位主机,但是你仍然手工管理这些服务配置。尤其对于每个消费者,这个创建过程很难从代码上确定 nsqd 实例在哪里。你真正希望的是配置能进化,并且在 NSQ 集群的状态基础上运行时可访问。这是我们建立 nsqlookupd 的目的。
nsqlookupd 是一个守护进程记录并传播 NSQ 集群运行时候的状态。nsqd 实例维护 TPC 连接的持久化来 nsqlookupd,并且推送状态变化。具体来说,nsqd 将自己注册为某个话题(topic)的生产者,以及所有它知道的通道(channel)。它允许消费者查询 nsqlookupd,来确定谁是感兴趣的话题(topic)的生产者。久而久之,他们将会知道新的生产者的存在,并能路由失败。
你需要做的改变仅仅是,nsqlookupd 时指出存在的 nsqd 和消费者实例(每个人都知道 nsqlookupd 实例在哪里,但是消费者不会明确的知道生产者在哪里,反之亦然)。现在拓扑结构如下:
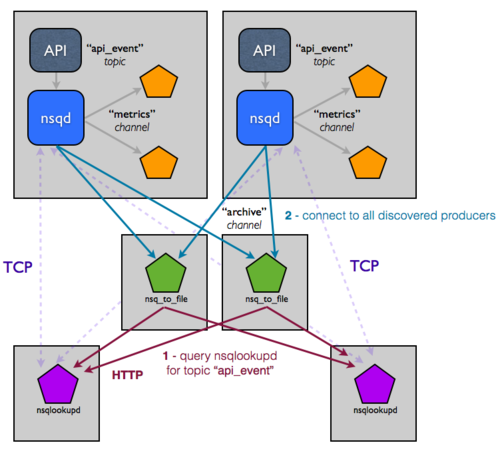
乍一看,这个图变复杂了。这图具有误导性,整个图节点变多了,导致很难直接通讯。因为 nsqlookupd 能作为文件夹服务,你能高效的把生产者和消费者解耦。依赖于已有的流添加一个下行服务非常简单,只需指定你感兴趣的话题(topic)(通过 nsqlookupd 可以找到生产者)。
如何保证查找数据的可用性和一致性?nsqlookupd 并不会占用大量资源,并且能很容易和其他服务器在一起工作。同时 nsqlookupd 实例不需要调整,或者和其他组合。消费者通常只需要一个 nsqlookupd(它们将会联合它们所知的nsqlookupd 实例响应)。这样就很容易迁移到新的 nsqlookupd 组合中。