脚本类、文件 I/O 和 XML 操作
最后,我们来看一下 Groovy 中比较高级的用法。
脚本类
1.脚本中 import 其他类
Groovy 中可以像 Java 那样写 package,然后写类。比如在文件夹 com/cmbc/groovy/目录中放一个文件,叫 Test.groovy,如图 10 所示:
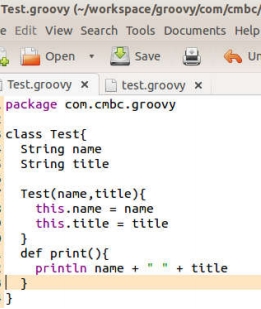
你看,图 10 中的 Test.groovy 和 Java 类就很相似了。当然,如果不声明 public/private 等访问权限的话,Groovy 中类及其变量默认都是 public 的。
现在,我们在测试的根目录下建立一个 test.groovy 文件。其代码如下所示:
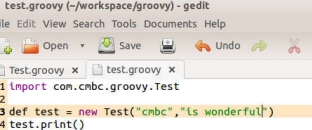
你看,test.groovy 先 import 了 com.cmbc.groovy.Test 类,然后创建了一个 Test 类型的对象,接着调用它的 print 函数。
这两个 groovy 文件的目录结构如图 12 所示:

在 groovy 中,系统自带会加载当前目录/子目录下的 xxx.groovy 文件。所以,当执行 groovy test.groovy 的时候,test.groovy import 的 Test 类能被自动搜索并加载到。
2.脚本到底是什么
Java 中,我们最熟悉的是类。但是我们在 Java 的一个源码文件中,不能不写 class(interface 或者其他....),而 Groovy 可以像写脚本一样,把要做的事情都写在 xxx.groovy 中,而且可以通过 groovy xxx.groovy 直接执行这个脚本。这到底是怎么搞的?
既然是基于 Java 的,Groovy 会先把 xxx.groovy 中的内容转换成一个 Java 类。比如:
test.groovy 的代码是:
println 'Groovy world!'Groovy 把它转换成这样的 Java 类:
执行 groovyc -d classes test.groovy
groovyc 是 groovy 的编译命令,-d classes 用于将编译得到的 class 文件拷贝到 classes 文件夹下
图 13 是 test.groovy 脚本转换得到的 java class。用 jd-gui 反编译它的代码:
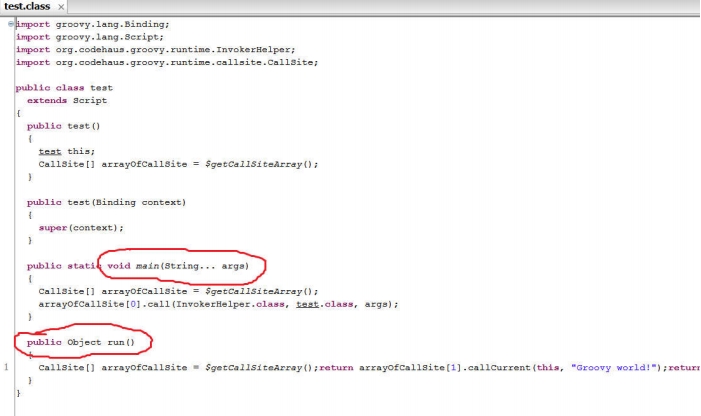
图 13 中:
- test.groovy 被转换成了一个 test 类,它从 script 派生。
- 每一个脚本都会生成一个 static main 函数。这样,当我们 groovy test.groovy 的时候,其实就是用 java 去执行这个 main 函数
- 脚本中的所有代码都会放到 run 函数中。比如,println 'Groovy world',这句代码实际上是包含在 run 函数里的。
- 如果脚本中定义了函数,则函数会被定义在 test 类中。
groovyc 是一个比较好的命令,读者要掌握它的用法。然后利用 jd-gui 来查看对应 class 的 Java 源码。
3.脚本中的变量和作用域
前面说了,xxx.groovy 只要不是和 Java 那样的 class,那么它就是一个脚本。而且脚本的代码其实都会被放到 run 函数中去执行。那么,在 Groovy 的脚本中,很重要的一点就是脚本中定义的变量和它的作用域。举例:
def x = 1 <==注意,这个 x 有 def(或者指明类型,比如 int x = 1)
def printx(){
println x
}
printx() <==报错,说 x 找不到 为什么?继续来看反编译后的 class 文件。
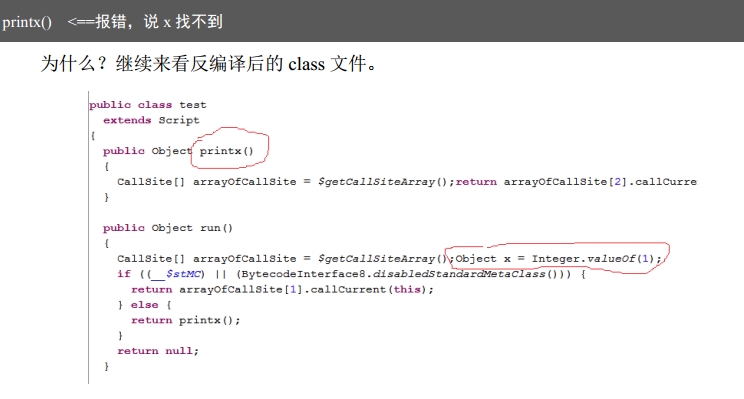
图 14 中:
- printx 被定义成 test 类的成员函数
- def x = 1,这句话是在 run 中创建的。所以,x=1 从代码上看好像是在整个脚本中定义的,但实际上 printx 访问不了它。printx 是 test 成员函数,除非 x 也被定义成 test 的成员函数,否则 printx 不能访问它。
那么,如何使得 printx 能访问 x 呢?很简单,定义的时候不要加类型和 def。即:
x = 1 <==注意,去掉 def 或者类型
def printx(){
println x
}
printx() <==OK这次 Java 源码又变成什么样了呢?
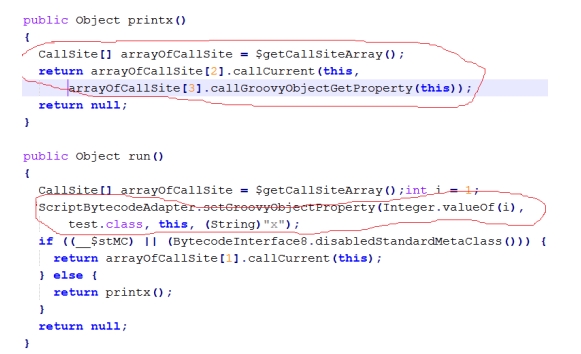
图 15 中,x 也没有被定义成 test 的成员函数,而是在 run 的执行过程中,将 x 作为一个属性添加到 test 实例对象中了。然后在 printx 中,先获取这个属性。
注意,Groovy 的文档说 x = 1 这种定义将使得 x 变成 test 的成员变量,但从反编译情况看,这是不对得.....
虽然 printx 可以访问 x 变量了,但是假如有其他脚本却无法访问 x 变量。因为它不是 test 的成员变量。
比如,我在测试目录下创建一个新的名为 test1.groovy。这个 test1 将访问 test.groovy 中定义的 printx 函数:

这种方法使得我们可以将代码分成模块来编写,比如将公共的功能放到 test.groovy 中,然后使用公共功能的代码放到 test1.groovy 中。
执行 groovy test1.groovy,报错。说 x 找不到。这是因为 x 是在 test 的 run 函数动态加进去的。怎么办?
import groovy.transform.Field; //必须要先 import
@Field x = 1 <==在 x 前面加上@Field 标注,这样,x 就彻彻底底是 test 的成员变量了。 查看编译后的 test.class 文件,得到:

这个时候,test.groovy 中的 x 就成了 test 类的成员函数了。如此,我们可以在 script 中定义那些需要输出给外部脚本或类使用的变量了!
文件 I/O 操作
本节介绍下 Groovy 的文件 I/O 操作。直接来看例子吧,虽然比 Java 看起来简单,但要理解起来其实比较难。尤其是当你要自己查 SDK 并编写代码的时候。
整体说来,Groovy 的 I/O 操作是在原有 Java I/O 操作上进行了更为简单方便的封装,并且使用 Closure 来简化代码编写。主要封装了如下一些了类:
1.读文件
Groovy 中,文件读操作简单到令人发指:
def targetFile = new File(文件名) <==File 对象还是要创建的。
然后打开 http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/File.html 看看 Groovy 定义的 API:
1 读该文件中的每一行:eachLine 的唯一参数是一个 Closure。Closure 的参数是文件每一行的内容
其内部实现肯定是 Groovy 打开这个文件,然后读取文件的一行,然后调用 Closure...
targetFile.eachLine{
String oneLine ->
println oneLine
} <==是不是令人发指??! 2 直接得到文件内容
targetFile.getBytes() <==文件内容一次性读出,返回类型为 byte[] 注意前面提到的 getter 和 setter 函数,这里可以直接使用 targetFile.bytes //....
3 使用 InputStream.InputStream 的 SDK 在 http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/InputStream.html
def ism = targetFile.newInputStream()
//操作 ism,最后记得关掉 ism.close
4 使用闭包操作 inputStream,以后在 Gradle 里会常看到这种搞法
targetFile.withInputStream{ ism ->
操作 ism. 不用 close。Groovy 会自动替你 close
}确实够简单,令人发指。我当年死活也没找到 withInputStream 是个啥意思。所以,请各位开发者牢记 Groovy I/O 操作相关类的 SDK 地址:
java.io.File: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/File.html
java.io.InputStream: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/InputStream.html
java.io.OutputStream: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/OutputStream.html
java.io.Reader: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/Reader.html
java.io.Writer: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/io/Writer.html
java.nio.file.Path: http://docs.groovy-lang.org/latest/html/groovy-jdk/java/nio/file/Path.html
2.写文件
和读文件差不多。不再啰嗦。这里给个例子,告诉大家如何 copy 文件。
def srcFile = new File(源文件名)
def targetFile = new File(目标文件名)
targetFile.withOutputStream{ os->
srcFile.withInputStream{ ins->
os << ins //利用 OutputStream 的<<操作符重载,完成从 inputstream 到 OutputStream
//的输出
}
}尼玛....关于 OutputStream 的<<操作符重载,查看 SDK 文档后可知:
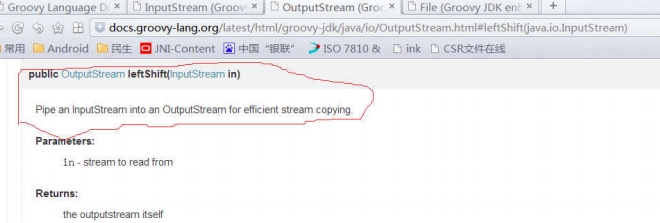
再一次向极致简单致敬。但是,SDK 恐怕是离不开手了...
XML 操作
除了 I/O 异常简单之外,Groovy 中的 XML 操作也极致得很。Groovy 中,XML 的解析提供了和 XPath 类似的方法,名为 GPath。这是一个类,提供相应 API。关于 XPath,请脑补 https://en.wikipedia.org/wiki/XPath。
GPath 功能包括:给个例子好了,来自 Groovy 官方文档。
test.xml 文件:
<response version-api="2.0">
<value>
<books>
<book available="20" id="1">
<title>Don Xijote</title>
<author id="1">Manuel De Cervantes</author>
</book>
<book available="14" id="2">
<title>Catcher in the Rye</title>
<author id="2">JD Salinger</author>
</book>
<book available="13" id="3">
<title>Alice in Wonderland</title>
<author id="3">Lewis Carroll</author>
</book>
<book available="5" id="4">
<title>Don Xijote</title>
<author id="4">Manuel De Cervantes</author>
</book>
</books>
</value>
</response>- 现在来看怎么玩转 GPath:
//第一步,创建 XmlSlurper 类
def xparser = new XmlSlurper()
def targetFile = new File("test.xml")
//轰轰的 GPath 出场
GPathResult gpathResult = xparser.parse(targetFile)
//开始玩 test.xml。现在我要访问 id=4 的 book 元素。
//下面这种搞法,gpathResult 代表根元素 response。通过 e1.e2.e3 这种
//格式就能访问到各级子元素....
def book4 = gpathResult.value.books.book[3]
//得到 book4 的 author 元素
def author = book4.author
//再来获取元素的属性和 textvalue
assert author.text() == ' Manuel De Cervantes '
获取属性更直观
author.@id == '4' 或者 author['@id'] == '4'
属性一般是字符串,可通过 toInteger 转换成整数
author.@id.toInteger() == 4好了。GPath 就说到这。再看个例子。我在使用 Gradle 的时候有个需求,就是获取 AndroidManifest.xml 版本号(versionName)。有了 GPath,一行代码搞定,请看:
def androidManifest = new XmlSlurper().parse("AndroidManifest.xml")
println androidManifest['@android:versionName']
或者
println androidManifest.@'android:versionName'