Actors
Actor模型为编写并发和分布式系统提供了一种更高的抽象级别。它将开发人员从显式地处理锁和线程管理的工作中解脱出来,使编写并发和并行系统更加容易。Actor模型是在1973年Carl Hewitt的论文中定义的,不过直到被Erlang语言采用后才变得流行起来,一个成功案例是爱立信使用Erlang非常成功地创建了高并发的可靠的电信系统。
Akka Actor的API与Scala Actor类似,它们都借鉴了Erlang的一些语法。
创建Actor
注意
由于Akka采用强制性的父子监管,每一个actor都被监管着,并且(可能)是别的actor的监管者;我们建议你熟悉一下Actor系统 和 监管与监控,阅读 Actor引用,路径与地址也有帮助。
定义一个Actor类
要定义自己的Actor类,需要继承Actor并实现receive方法。receive方法需要定义一系列case语句(类型为PartialFunction[Any, Unit])来描述你的Actor能够处理哪些消息(使用标准的Scala模式匹配),以及消息如何被处理。
如下例:
import akka.actor.Actor
import akka.actor.Props
import akka.event.Logging
class MyActor extends Actor {
val log = Logging(context.system, this)
def receive = {
case "test" => log.info("received test")
case _ => log.info("received unknown message")
}
}
请注意Akka Actor的receive消息循环是完全的,这与Erlang和Scala的Actor行为不同。这意味着你需要提供一个模式匹配,来处理这个actor所能够接受的所有消息的规则,如果你希望处理未知的消息,你需要象上例一样提供一个缺省的case分支。否则会有一个akka.actor.UnhandledMessage(message,
sender, recipient)被发布到Actor系统(ActorSystem)的事件流(EventStream)中。
进一步注意到上面定义行为的返回类型是Unit;如果该actor应该回应收到的消息,则必须明确写出,如下文所述。
receive方法的结果是一个偏函数对象,它存储在actor中作为其"最初的行为",对actor构造完成后改变行为的进一步信息,请参阅Become/Unbecome。
Props
Props是一个用来在创建actor时指定选项的配置类,可以把它看作是不可变的,因此在创建包含相关部署信息的actor时(例如使用哪一个调度器(dispatcher),详见下文),是可以自由共享的。以下是如何创建Props实例的示例.
import akka.actor.Props
val props1 = Props[MyActor]
val props2 = Props(new ActorWithArgs("arg")) // careful, see below
val props3 = Props(classOf[ActorWithArgs], "arg")
第二个变量props2演示了创建actor时,怎样将构造函数参数传进去,但它只应在actor之外使用,详见下文。
最后一行展示了一种可能性,它在不关注上下文的情况下传递构造函数参数。在构造Props对象的时候,会检查是否存在匹配的构造函数,如果没有或存在多个匹配的构造函数,则会导致IllegalArgumentEception。
危险的变量
// 不建议在另一个actor内使用:
// 因为它鼓励封闭作用域
val props7 = Props(new MyActor)
该方法不建议在另一个actor内使用,因为它鼓励封闭作用域,从而导致不可序列化的Props和可能的竞态条件(破坏了actor封装)。我们将提供一个基于宏的解决方案,在将来的版本中没有头痛地支持类似的语法,届时该变量将被恰当的废弃。另一方面在actor的伴生对象下,在一个Props工厂中使用该变量是完全没问题的,如下面"推荐做法"所述。
这些方法有两个用例:将构造函数的参数传递给该actor——由新推出的Props.apply(clazz, args)方法解决了,如上面或下面的推荐做法所示——和作为匿名类创建"临时性"的actor。后者应通过命名这些actor,而非匿名来解决(如果他们未在顶级object中声明,则封闭的实例的this引用需要作为第一个参数传入)。
警告
在另一个actor中声明一个actor是非常危险的,会打破actor的封装。永远不要将一个actor的
this引用传进Props!
推荐做法
在每一个Actor的伴生对象中提供工厂方法是一个好主意,这有助于保持创建合适的Props,尽可能接近actor的定义。这也避免了使用Props.apply(...)方法将采用一个“按名”(by-name)参数的缺陷,因为伴生对象的给定代码块中将不会保留包含作用域的引用:
object DemoActor {
/**
* Create Props for an actor of this type.
* @param magciNumber The magic number to be passed to this actor’s constructor.
* @return a Props for creating this actor, which can then be further configured
* (e.g. calling `.withDispatcher()` on it)
*/
def props(magicNumber: Int): Props = Props(new DemoActor(magicNumber))
}
class DemoActor(magicNumber: Int) extends Actor {
def receive = {
case x: Int => sender() ! (x + magicNumber)
}
}
class SomeOtherActor extends Actor {
// Props(new DemoActor(42)) would not be safe
context.actorOf(DemoActor.props(42), "demo")
// ...
}
使用Props创建Actor
Actor可以通过将Props实例传入actorOf工厂方法来创建,ActorSystem和ActorContext中都有该方法。
import akka.actor.ActorSystem
// ActorSystem is a heavy object: create only one per application
val system = ActorSystem("mySystem")
val myActor = system.actorOf(Props[MyActor], "myactor2")
使用ActorSystem将创建顶级actor,由actor系统提供的守护actor监管;如果使用的是actor的上下文,则创建一个该actor的子actor。
class FirstActor extends Actor {
val child = context.actorOf(Props[MyActor], name = "myChild")
// plus some behavior ...
}
推荐创建一个树形结构,包含子actor、孙子等等,使之符合应用的逻辑错误处理结构,见Actor系统。
对actorOf的调用返回一个ActorRef实例。它是actor实例的句柄,并且是与之进行交互的唯一方法。ActorRef是不可变的,与其代表的actor有一一对应关系。ActorRef也是可序列化,并能通过网络传输。这意味着你可以将其序列化,通过网线发送,并在远程主机上使用它,而且虽然跨网络,它将仍然代表在原始节点上相同的actor。
名称参数是可选的,不过你应该良好命名你的actor,因为名称将被用于日志打印和标识actor。名称不能为空,且不能以$开头,不过它可以包含URL编码字符(如空格用%20表示)。如果给定的名称已经被同一个父亲下的另一个子actor使用,则会抛出一个InvalidActorNameException。
actor在创建时,会自动异步启动。
依赖注入
如果你的actor有带参数的构造函数,则这些参数也需要成为Props的一部分,如上文所述。但有些情况下必须使用工厂方法,例如,当实际构造函数的参数由依赖注入框架决定。
import akka.actor.IndirectActorProducer
class DependencyInjector(applicationContext: AnyRef, beanName: String)
extends IndirectActorProducer {
override def actorClass = classOf[Actor]
override def produce =
// obtain fresh Actor instance from DI framework ...
}
val actorRef = system.actorOf(
Props(classOf[DependencyInjector], applicationContext, "hello"),
"helloBean")
警告
你有时可能倾向于提供一个
IndirectActorProducer始终返回相同的实例,例如通过使用lazy val。这是不受支持的,因为它违背了actor重启的意义。当使用依赖注入框架时,actor bean必须不是单例作用域。
关于依赖注入极其Akka集成的更多内容情参见“在Akka中使用依赖注入”指南和Typesafe Activator的“Akka Java Spring”教程。
收件箱
当在actor外编写与actor交互的代码时,ask模式可以作为一个解决方案(见下文),但有两件事它不能做:接收多个答复(例如将ActorRef订阅到一个通知服务)和查看其他actor的生命周期。为达到这些目的可以使用Inbox类:
implicit val i = inbox()
echo ! "hello"
i.receive() should be("hello")
有一个从收件箱到actor引用的一个隐式转换,意味着在这个例子中,发送者引用将成为收件箱隐藏的actor。这就允许了收件箱收到回应,如最后一行所示。监控一个actor也相当简单:
val target = // some actor
val i = inbox()
i watch target
Actor API
Actor trait只定义了一个抽象方法,就是上面提到的receive,用来实现actor的行为。
如果当前actor的行为与收到的消息不匹配,则会调用 unhandled,其缺省实现是向actor系统的事件流中发布一条akka.actor.UnhandledMessage(message, sender, recipient)(将配置项akka.actor.debug.unhandled设置为on来将它们转换为实际的调试消息)。
另外,它还包括:
self引用代表本actor的ActorRefsender引用代表最近收到消息的发送actor,通常用于下面将讲到的消息回应中supervisorStrategy用户可重写它来定义对子actor的监管策略该策略通常在actor内声明,这样决定函数就可以访问actor的内部状态:因为失败通知作为消息发送给监管者,并像普通消息一样被处理(尽管不是正常行为),所有的值和actor变量都是可用的,以及
sender引用 (报告失败的将是直接子actor;如果原始失败发生在遥远的后裔,它仍然是一次向上报告一层)。context暴露actor和当前消息的上下文信息,如:- 用于创建子actor的工厂方法(
actorOf) - actor所属的系统
- 父监管者
- 所监管的子actor
- 生命周期监控
- hotswap行为栈,见Become/Unbecome
- 用于创建子actor的工厂方法(
你可以import context的成员来避免总加上context.前缀
class FirstActor extends Actor {
import context._
val myActor = actorOf(Props[MyActor], name = "myactor")
def receive = {
case x => myActor ! x
}
}
其余的可见方法是可以被用户重写的生命周期hook,描述如下:
def preStart(): Unit = ()
def postStop(): Unit = ()
def preRestart(reason: Throwable, message: Option[Any]): Unit = {
context.children foreach { child ⇒
context.unwatch(child)
context.stop(child)
}
postStop()
}
def postRestart(reason: Throwable): Unit = {
preStart()
}
以上代码所示的是Actor trait的缺省实现。
Actor生命周期
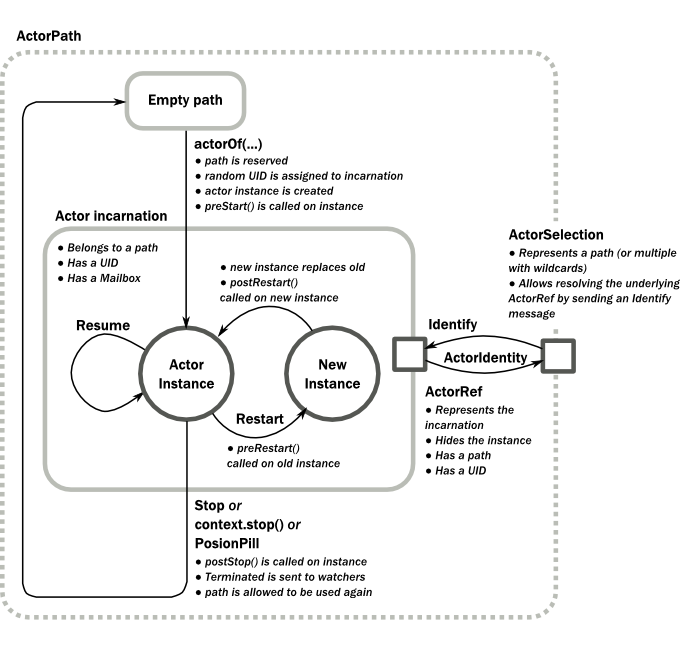
actor系统中的路径代表一个"地方",这里可能会被活着的actor占据。最初(除了系统初始化actor)路径都是空的。在调用actorOf()时它将为指定路径分配根据传入Props创建的一个actor化身。actor化身是由路径和一个UID标识的。重新启动只会替换有Props定义的Actor实例,但不会替换化身,因此UID保持不变。
当actor停止时,其化身的生命周期结束。在这一时间点上相关的生命周期事件被调用,监视该actor的actor都会获得终止通知。当化身停止后,路径可以重复使用,通过actorOf()创建一个actor。在这种情况下,除了UID不同外,新化身与老化身是相同的。
ActorRef始终表示化身(路径和UID)而不只是一个给定的路径。因此如果actor停止,并且创建一个新的具有相同名称的actor,则指向老化身的ActorRef将不会指向新的化身。
相对地,ActorSelection指向路径(或多个路径,如果使用了通配符),且完全不关注有没有化身占据它。因此ActorSelection 不能被监视。获取某路径下的当前化身ActorRef是可能的,只要向该ActorSelection发送Identify,如果收到ActorIdentity回应,则正确的引用就包含其中(详见通过Actor Selection确定Actor)。也可以使用ActorSelection的resolveOne方法,它会返回一个包含匹配ActorRef的Future。
使用DeathWatch进行生命周期监控
为了在其它actor终止时 (即永久停止,而不是临时的失败和重启)收到通知,actor可以将自己注册为其它actor在终止时所发布的Terminated消息的接收者(见停止 Actor)。这个服务是由actor系统的DeathWatch组件提供的。
注册一个监视器很简单:
import akka.actor.{ Actor, Props, Terminated }
class WatchActor extends Actor {
val child = context.actorOf(Props.empty, "child")
context.watch(child) // <-- this is the only call needed for registration
var lastSender = system.deadLetters
def receive = {
case "kill" =>
context.stop(child); lastSender = sender()
case Terminated(`child`) => lastSender ! "finished"
}
}
要注意Terminated消息的产生与注册和终止行为所发生的顺序无关。特别地,即使在注册时,被观察的actor已经终止了,监视actor仍然会受到一个Terminated消息。
多次注册并不表示会有多个消息产生,也不保证有且只有一个这样的消息被接收到:如果被监控的actor已经生成了消息并且已经进入了队列,在这个消息被处理之前又发生了另一次注册,则会有第二个消息进入队列,因为对一个已经终止的actor的监控注册操作会立刻导致Terminated消息的产生。
可以使用context.unwatch(target)来停止对另一个actor生存状态的监控。即使Terminated已经加入邮箱,该操作仍有效;一旦调用unwatch,则被观察的actor的Terminated消息就都不会再被处理。
启动Hook
actor启动后,它的preStart方法会被立即执行。
override def preStart() {
// registering with other actors
someService ! Register(self)
}
在actor第一次创建时,将调用此方法。在重新启动期间,它被postRestart的默认实现调用,这意味着通过重写该方法,你可以选择是仅仅在初始化该actor时调用一次,还是为每次重新启动都调用。actor构造函数中的初始化代码将在每个actor实例创建的时候被调用,这也发生在每次重启时。
重启Hook
所有的actor都是被监管的,即与另一个使用某种失败处理策略的actor绑定在一起。如果在处理一个消息的时候抛出了异常,Actor将被重启(详见监管与监控)。这个重启过程包括上面提到的Hook:
要被重启的actor被通知是通过调用
preRestart,包含着导致重启的异常以及触发异常的消息;如果重启并不是因为消息处理而发生的,则所携带的消息为None,例如,当一个监管者没有处理某个异常继而被其监管者重启时,或者因其兄弟节点的失败导致的重启。如果消息可用,则消息的发送者通常也可用(即通过调用sender)。这个方法是用来完成清理、准备移交给新actor实例等操作的最佳位置。其缺省实现是终止所有子actor并调用
postStop。- 最初调用
actorOf的工厂将被用来创建新的实例。 - 新的actor的
postRestart方法被调用时,将携带着导致重启的异常信息。默认实现中,preStart被调用时,就像一个正常的启动一样。
actor的重启只会替换掉原来的actor对象;重启不影响邮箱的内容,所以对消息的处理将在postRestart hook返回后继续。触发异常的消息不会被重新接收。在actor重启过程中,所有发送到该actor的消息将象平常一样被放进邮箱队列中。
警告
要知道失败通知与用户消息的相关顺序不是决定性的。尤其是,在失败以前收到的最后一条消息被处理之前,父节点可能已经重启其子节点了。详细信息请参见“讨论:消息顺序”。
终止 Hook
一个Actor终止后,其postStop hook将被调用,它可以用来,例如取消该actor在其它服务中的注册。这个hook保证在该actor的消息队列被禁止后才运行,即之后发给该actor的消息将被重定向到ActorSystem的deadLetters中。
通过Actor Selection定位Actor
如Actor引用, 路径与地址中所述,每个actor都拥有一个唯一的逻辑路径,此路径是由从actor系统的根开始的父子链构成;它还拥有一个物理路径,如果监管链包含有远程监管者,此路径可能会与逻辑路径不同。这些路径用来在系统中查找actor,例如,当收到一个远程消息时查找收件者,但是它们更直接的用处在于:actor可以通过指定绝对或相对路径(逻辑的或物理的)来查找其它的actor,并随结果获取一个ActorSelection:
// will look up this absolute path
context.actorSelection("/user/serviceA/aggregator")
// will look up sibling beneath same supervisor
context.actorSelection("../joe")
其中指定的路径被解析为一个java.net.URI,它以/分隔成路径段。如果路径以/开始,表示一个绝对路径,且从根监管者("/user"的父亲)开始查找;否则是从当前actor开始。如果某一个路径段为..,会找到当前所遍历到的actor的上一级,否则则会向下一级寻找具有该名字的子actor。 必须注意的是actor路径中的..总是表示逻辑结构,即其监管者。
一个actor selection的路径元素中可能包含通配符,从而允许向匹配模式的集合广播该条消息:
// will look all children to serviceB with names starting with worker
context.actorSelection("/user/serviceB/worker*")
// will look up all siblings beneath same supervisor
context.actorSelection("../*")
消息可以通过ActorSelection发送,并且在投递每条消息时 ActorSelection的路径都会被查找。如果selection不匹配任何actor,则消息将被丢弃。
要获得ActorSelection的ActorRef,你需要发送一条消息到selection,然后使用答复消息的sender()引用即可。有一个内置的Identify消息,所有actor会理解它并自动返回一个包含ActorRef的ActorIdentity消息。此消息被遍历到的actor特殊处理为,如果一个具体的名称查找失败(即一个不含通配符的路径没有对应的活动actor),则会生成一个否定结果。请注意这并不意味着应答消息有到达保证,它仍然是一个普通的消息。
import akka.actor.{ Actor, Props, Identify, ActorIdentity, Terminated }
class Follower extends Actor {
val identifyId = 1
context.actorSelection("/user/another") ! Identify(identifyId)
def receive = {
case ActorIdentity(`identifyId`, Some(ref)) =>
context.watch(ref)
context.become(active(ref))
case ActorIdentity(`identifyId`, None) => context.stop(self)
}
def active(another: ActorRef): Actor.Receive = {
case Terminated(`another`) => context.stop(self)
}
}
你也可以通过ActorSelection的resolveOne方法获取ActorSelection的一个ActorRef。如果存在这样的actor,它将返回一个包含匹配的ActorRef的Future。如果没有这样的actor
存在或识别没有在指定的时间内完成,它将以失败告终——akka.actor.ActorNotFound。
如果开启了远程调用,则远程actor地址也可以被查找:
context.actorSelection("akka.tcp://app@otherhost:1234/user/serviceB")
一个关于actor查找的示例见远程查找。
注意
actorFor因被actorSelection替代而废弃,因为actorFor对本地和远程的actor表现有所不同。对一个本地actor引用,被查找的actor需要在查找之前就存在,否则获得的引用是一个EmptyLocalActorRef。即使后来与实际路径相符的actor被创建,所获得引用仍然是这样。对于actorFor行为获得的远程actor 引用则不同,每条消息的发送都会在远程系统中进行一次按路径的查找。
消息与不可变性
重要:消息可以是任何类型的对象,但必须是不可变的。(目前) Scala还无法强制不可变性,所以这一点必须作为约定。String、Int、Boolean这些原始类型总是不可变的。 除了它们以外,推荐的做法是使用Scala case class,它们是不可变的(如果你不专门暴露状态的话),并与接收侧的模式匹配配合得非常好。
以下是一个例子:
// define the case class
case class Register(user: User)
// create a new case class message
val message = Register(user)
发送消息
向actor发送消息需使用下列方法之一。
!意思是“fire-and-forget”,即异步发送一个消息并立即返回。也称为tell。?异步发送一条消息并返回一个Future代表一个可能的回应。也称为ask。
对每一个消息发送者,分别有消息顺序保证。
注意
使用
ask有一些性能内涵,因为需要跟踪超时,需要有桥梁将Promise转为ActorRef,并且需要在远程情况下可访问。所以为了性能应该总选择tell,除非只能选择ask。
Tell: Fire-forget
这是发送消息的推荐方式。 不会阻塞地等待消息。它拥有最好的并发性和可扩展性。
actorRef ! message
如果是在一个Actor中调用 ,那么发送方的actor引用会被隐式地作为消息的sender(): ActorRef成员一起发送。目的actor可以使用它来向源actor发送回应, 使用sender() ! replyMsg。
如果不是从Actor实例发送的,sender成员缺省为 deadLetters actor引用。
Ask: Send-And-Receive-Future
ask模式既包含actor也包含future,所以它是一种使用模式,而不是ActorRef的方法:
import akka.pattern.{ ask, pipe }
import system.dispatcher // The ExecutionContext that will be used
case class Result(x: Int, s: String, d: Double)
case object Request
implicit val timeout = Timeout(5 seconds) // needed for `?` below
val f: Future[Result] =
for {
x <- ask(actorA, Request).mapTo[Int] // call pattern directly
s <- (actorB ask Request).mapTo[String] // call by implicit conversion
d <- (actorC ? Request).mapTo[Double] // call by symbolic name
} yield Result(x, s, d)
f pipeTo actorD // .. or ..
pipe(f) to actorD
上面的例子展示了将ask与future上的pipeTo模式一起使用,因为这是一种非常常用的组合。 请注意上面所有的调用都是完全非阻塞和异步的:ask产生 Future,三个Future通过for-语法组合成一个新的future,然后用pipeTo在future上安装一个onComplete-处理器来完成将收集到的Result发送到另一个actor的动作。
使用ask将会像tell一样发送消息给接收方, 接收方必须通过sender() ! reply发送回应来为返回的Future填充数据。ask操作包括创建一个内部actor来处理回应,必须为这个内部actor指定一个超时期限,并且过期销毁该内部actor以防止内存泄露。
警告
如果要以异常来完成future你需要发送一个
Failure消息给发送方。这个操作不会在actor处理消息发生异常时自动完成。
try {
val result = operation()
sender() ! result
} catch {
case e: Exception =>
sender() ! akka.actor.Status.Failure(e)
throw e
}
如果actor没有完成future,它会在超时时限到来时过期,以AskTimeoutException结束。超时的时限是按下面的代码来设置的:
- 显式指定超时:
import akka.util.duration._
import akka.pattern.ask
val future = myActor.ask("hello")(5 seconds)
- 提供类型为
akka.util.Timeout的隐式参数,例如,
import scala.concurrent.duration._
import akka.util.Timeout
import akka.pattern.ask
implicit val timeout = Timeout(5 seconds)
val future = myActor ? "hello"
参阅 Futures (Scala) 了解更多关于等待和查询future的信息。
Future的onComplete、onSuccess或onFailure方法可以用来注册一个回调,以便在Future完成时得到通知。从而提供一种避免阻塞的方法。
警告
在使用future回调如
onComplete、onSuccess和onFailure时, 在actor内部你要小心避免捕捉该actor的引用,即不要在回调中调用该actor的方法或访问其可变状态。这会破坏actor的封装,会引用同步bug和竞态条件,因为回调会与此actor一同被并发调度。不幸的是目前还没有一种编译时的方法能够探测到这种非法访问。参阅: Actor与共享可变状态
转发消息
你可以将消息从一个actor转发给另一个。虽然经过了一个“中间人”,但最初的发送者地址/引用将保持不变。当实现类似路由器、负载均衡器、复制器等功能的actor时会很有用。
myActor.forward(message)
接收消息
Actor必须实现receive方法来接收消息:
protected def receive: PartialFunction[Any, Unit]
这个方法应返回一个PartialFunction,例如一个“match/case”子句,消息可以与其中的不同分支进行scala模式匹配。如下例:
import akka.actor.Actor
import akka.actor.Props
import akka.event.Logging
class MyActor extends Actor {
val log = Logging(context.system, this)
def receive = {
case "test" => log.info("received test")
case _ => log.info("received unknown message")
}
}
回应消息
如果你需要一个用来发送回应消息的目标,可以使用sender(),它返回一个Actor引用。你可以用sender() ! replyMsg向这个引用发送回应消息。你也可以将这个ActorRef保存起来,将来再作回应或传给其它actor。如果没有sender(不是从actor发送的消息或者没有future上下文)那么sender缺省为 “死信”actor引用.
case request =>
val result = process(request)
sender() ! result // will have dead-letter actor as default
接收超时
ActorContext的setReceiveTimeout定义一个不活动时间,在这个时间到达后后,将触发一个ReceiveTimeout消息的发送。当指定超时时,接收函数应该能够处理akka.actor.ReceiveTimeout消息。最低支持的超时是 1 毫秒。
请注意接收超时引发的ReceiveTimeout消息可能在另一条消息后加入队列;因此不能保证收到的接收超时必须与设置的空闲时间长度一致。
一旦进行了设置,接收超时将一直有效(即继续在空闲期后重发)。通过传入Duration.Undefined关掉此功能。
import akka.actor.ReceiveTimeout
import scala.concurrent.duration._
class MyActor extends Actor {
// To set an initial delay
context.setReceiveTimeout(30 milliseconds)
def receive = {
case "Hello" =>
// To set in a response to a message
context.setReceiveTimeout(100 milliseconds)
case ReceiveTimeout =>
// To turn it off
context.setReceiveTimeout(Duration.Undefined)
throw new RuntimeException("Receive timed out")
}
}
终止Actor
通过调用ActorRefFactory(即ActorContext或ActorSystem)的stop方法来终止一个actor。通常context用来终止子actor,而 system用来终止顶级actor。实际的终止操作是异步执行的,即stop可能在actor被终止之前返回。
如果当前有正在处理的消息,对该消息的处理将在actor被终止之前完成,但是邮箱中的后续消息将不会被处理。缺省情况下这些消息会被送到ActorSystem的deadLetters中,但是这取决于邮箱的实现。
actor的终止分两步: 第一步actor将挂起对邮箱的处理,并向所有子actor发送终止命令,然后处理来自子actor的终止消息直到所有的子actor都完成终止,最后终止自己(调用postStop,清空邮箱,向DeathWatch发布Terminated,通知其监管者)。这个过程保证actor系统中的子树以一种有序的方式终止,将终止命令传播到叶子结点并收集它们回送的确认消息给被终止的监管者。如果其中某个actor没有响应(即由于处理消息用了太长时间以至于没有收到终止命令),整个过程将会被阻塞。
在ActorSystem.shutdown()被调用时,系统根监管actor会被终止,以上的过程将保证整个系统的正确终止。
postStop() hook 是在actor被完全终止以后调用的。这是为了清理资源:
override def postStop() {
// clean up some resources ...
}
注意
由于actor的终止是异步的,你不能马上使用你刚刚终止的子actor的名字;这会导致
InvalidActorNameException。你应该 监视watch()正在终止的actor,并在Terminated最终到达后作为回应创建它的替代者。
PoisonPill
你也可以向actor发送akka.actor.PoisonPill消息,这个消息处理完成后actor会被终止。PoisonPill与普通消息一样被放进队列,因此会在已经入队列的其它消息之后被执行。
优雅地终止
如果你需要等待终止过程的结束,或者组合若干actor的终止次序,可以使用gracefulStop:
import akka.pattern.gracefulStop
import scala.concurrent.Await
try {
val stopped: Future[Boolean] = gracefulStop(actorRef, 5 seconds, Manager.Shutdown)
Await.result(stopped, 6 seconds)
// the actor has been stopped
} catch {
// the actor wasn't stopped within 5 seconds
case e: akka.pattern.AskTimeoutException =>
}
object Manager {
case object Shutdown
}
class Manager extends Actor {
import Manager._
val worker = context.watch(context.actorOf(Props[Cruncher], "worker"))
def receive = {
case "job" => worker ! "crunch"
case Shutdown =>
worker ! PoisonPill
context become shuttingDown
}
def shuttingDown: Receive = {
case "job" => sender() ! "service unavailable, shutting down"
case Terminated(`worker`) =>
context stop self
}
}
当gracefulStop()成功返回时,actor的postStop() hook将会被执行:在postStop()结束和gracefulStop()返回之间存在happens-before边界。
在上面的示例中自定义的Manager.Shutdown消息是发送到目标actor来启动actor的终止过程。你可以使用PoisonPill,但之后在停止目标actor之前,你与其他actor的互动的机会有限。在postStop中,可以处理简单的清理任务。
警告
请记住,actor停止和其名称被注销是彼此异步发生的独立事件。因此,在
gracefulStop()返回后。你会发现其名称仍可能在使用中。为了保证正确注销,只在你控制的监管者内,并且只在响应Terminated消息时重用名称,即不是用于顶级actor。
Become/Unbecome
升级
Akka支持在运行时对Actor消息循环(即其实现)进行实时替换:在actor中调用context.become方法。become要求一个PartialFunction[Any, Unit]参数作为新的消息处理实现。 被替换的代码被保存在一个栈中,可以被push和pop。
警告
请注意actor被其监管者重启后将恢复其最初的行为。
使用become替换Actor的行为:
class HotSwapActor extends Actor {
import context._
def angry: Receive = {
case "foo" => sender() ! "I am already angry?"
case "bar" => become(happy)
}
def happy: Receive = {
case "bar" => sender() ! "I am already happy :-)"
case "foo" => become(angry)
}
def receive = {
case "foo" => become(angry)
case "bar" => become(happy)
}
}
become方法的变种还有很多其它的用处,例如实现一个有限状态机(FSM,例子见Dining Hakkers)。它将取代当前的行为 (即行为堆栈的顶部),这意味着你不需要使用unbecome,相反下一个行为总是被显式安装。
其他使用become的方式不是替换,而是添加到行为堆栈的顶部。在这种情况下必须小心,以确保长远而言,“pop”操作(即unbecome)与“push”操作相当,否则会导致内存泄漏 (这就是为什么这种行为不是默认的)。
case object Swap
class Swapper extends Actor {
import context._
val log = Logging(system, this)
def receive = {
case Swap =>
log.info("Hi")
become({
case Swap =>
log.info("Ho")
unbecome() // resets the latest 'become' (just for fun)
}, discardOld = false) // push on top instead of replace
}
}
object SwapperApp extends App {
val system = ActorSystem("SwapperSystem")
val swap = system.actorOf(Props[Swapper], name = "swapper")
swap ! Swap // logs Hi
swap ! Swap // logs Ho
swap ! Swap // logs Hi
swap ! Swap // logs Ho
swap ! Swap // logs Hi
swap ! Swap // logs Ho
}
对Scala Actors 嵌套接收消息进行编码而不会造成意外的内存泄露
参阅解嵌套接收消息示例。
贮藏(Stash)
Stash特质使actor可以暂时贮藏消息,来跳过当前行为不能或不应该处理的消息。在actor的消息处理程序改变时,即调用context.become或context.unbecome前,所有贮藏的消息可以是“unstashed”,从而前置到actor的邮箱中。这种方式下,贮藏消息可以按照其原始接收顺序被处理。
注意
Stash特质继承自标记特质RequiresMessageQueue[DequeBasedMessageQueueSemantics],它要求系统自动为actor选择一个基于deque的邮箱实现。如果你想更好地控制该邮箱,参阅文档邮箱。
这里是Stash的一个实际例子:
import akka.actor.Stash
class ActorWithProtocol extends Actor with Stash {
def receive = {
case "open" =>
unstashAll()
context.become({
case "write" => // do writing...
case "close" =>
unstashAll()
context.unbecome()
case msg => stash()
}, discardOld = false) // stack on top instead of replacing
case msg => stash()
}
}
调用stash()将当前消息(actor最后接收到的消息)添加到actor的贮藏处。通常在其它case语句不能处理该消息时,在默认处理中调用来把消息贮藏起来。两次贮藏同一个消息是非法的;这样做会抛出IllegalStateException。贮藏操作也可能是有界的,在这种情况下调用stash()可能会导致超出容量,结果抛出StashOverflowException。可以使用邮箱配置中的stash-capacity(一个Int)配置贮存能力。
调用unstashAll()将把贮藏的消息转移到actor的邮箱中,直到邮箱满(请注意消息从贮藏处被前置到邮箱中的)。万一有界的邮箱溢出,则抛出MessageQueueAppendFailedException。贮藏箱被保证在调用unstashAll()后被清空。
贮藏箱由scala.collection.immutable.Vector支持。其结果是,即使有很大数目的消息被贮藏也不会对性能有大的影响。
警告
Stash特质必须在preRestart回调被任何一个特质/类重写之前,被混入到Actor(的一个子类)中。这意味着如果MyActor重写preRestart,则不可能这样写——Actor with MyActor with Stash。
请注意贮藏箱是actor的瞬时状态,不同于邮箱。因此,它应该像actor中其他具有相同属性的状态一样被管理。Stash的preRestart实现将调用unstashAll(),这通常也是期望的行为。
注意
如果你想强制你的actor只能在无界贮藏箱下工作,则你应该换用
UnboundedStash特质。
杀死actor
你可以发送Kill消息来杀死actor。这将导致actor抛出ActorKilledException,触发失败。该actor将暂停操作,其主管也将会被问及如何处理这一失败,这可能意味着恢复actor、 重新启动或完全终止它。更多的信息,请参阅监管的意思。
像这样使用Kill:
// kill the 'victim' actor
victim ! Kill
Actor与异常
在消息被actor处理的过程中可能会抛出异常,例如数据库异常。
消息会怎样
如果消息处理过程中(即从邮箱中取出并交给当前行为后)发生了异常,这个消息将被丢失。必须明白它不会被放回到邮箱中。所以如果你希望重试对消息的处理,你需要自己抓住异常然后在异常处理流程中重试。请确保限制重试的次数,因为你不会希望系统产生活锁 (从而消耗大量CPU而于事无补)。另一种可能性请参见PeekMailbox 模式。
邮箱会怎样
如果消息处理过程中发生异常,邮箱没有任何变化。如果actor被重启,仍然是相同的邮箱在那里。邮箱中的所有消息不会丢失。
actor会怎样
如果actor代码抛出了异常,actor会被暂停并启动监管过程(参见监管与监控)。根据监管者的策略,actor可以被恢复(好像什么也没有发生过)、重启(消灭其内部状态并从零开始)或终止。
使用PartialFunction链来扩展actor
有时在一些actor中分享共同的行为,或通过若干小的函数构成一个actor的行为是很有用的。这由于actor的receive方法返回一个Actor.Receive(PartialFunction[Any,Unit]的类型别名)而使之成为可能,多个偏函数可以使用PartialFunction#orElse链接在一起。你可以根据需要链接尽可能多的功能,但是你要牢记"第一个匹配"获胜——这在组合可以处理同一类型的消息的功能时会很重要。
例如,假设你有一组actor是生产者Producers或消费者Consumers,然而有时候需要actor分享这两种行为。这可以很容易实现而无需重复代码,通过提取行为的特质和并将actor的receive实现为这些偏函数的组合。
trait ProducerBehavior {
this: Actor =>
val producerBehavior: Receive = {
case GiveMeThings =>
sender() ! Give("thing")
}
}
trait ConsumerBehavior {
this: Actor with ActorLogging =>
val consumerBehavior: Receive = {
case ref: ActorRef =>
ref ! GiveMeThings
case Give(thing) =>
log.info("Got a thing! It's {}", thing)
}
}
class Producer extends Actor with ProducerBehavior {
def receive = producerBehavior
}
class Consumer extends Actor with ActorLogging with ConsumerBehavior {
def receive = consumerBehavior
}
class ProducerConsumer extends Actor with ActorLogging
with ProducerBehavior with ConsumerBehavior {
def receive = producerBehavior orElse consumerBehavior
}
// protocol
case object GiveMeThings
case class Give(thing: Any)
不同于继承,相同的模式可以通过组合实现——可以简单地通过委托的偏函数组合成receive方法。
初始化模式
actor丰富的生命周期钩子(hook)提供一个有用的工具包,可用于实现各种初始化模式。在ActorRef的生命中,actor可能会经历多次重启,老的实例被替换为新的实例,除观察者以外是觉察不到的,只能看到一个ActorRef。
一个人可能把新实例看做是"化身"。初始化对actor每个化身都是必要的,但有时你需要初始化只在第一个实例创建时,即ActorRef创建时发生。以下各节提供了满足不同的初始化需求的模式。
通过构造函数初始化
使用构造函数初始化有各种好处。首先,使得用val字段来存储在actor实例的生命周期内不变的状态成为可能,使actor的实现更加健壮。对actor的每个化身都会调用一次构造函数,因此,actor内部总是可以假定正确地完成初始化。这也是这种方法的缺点,例如当想要避免在重启时重新初始化内部状态的情况下。例如,跨重启保留子actor经常很有用。下面提供了该情况的一种模式。
通过preStart初始化
actor的preStart()方法只在第一个实例的初始化时调用一次,即ActorRef创建时。在重新启动后,preStart()是由postRestart()调用,因此如果重写,preStart()对每个化身都会被调用。然而,重写postRestart()可以禁用此行为,并确保只有一个对preStart()的调用。
这种模式的一个有用用法是禁止在重启期间为子actor创建新ActorRefs。这可以通过重写preRestart()实现:
override def preStart(): Unit = {
// Initialize children here
}
// Overriding postRestart to disable the call to preStart()
// after restarts
override def postRestart(reason: Throwable): Unit = ()
// The default implementation of preRestart() stops all the children
// of the actor. To opt-out from stopping the children, we
// have to override preRestart()
override def preRestart(reason: Throwable, message: Option[Any]): Unit = {
// Keep the call to postStop(), but no stopping of children
postStop()
}
请注意,子actor仍会重新启动,但不会创建新的ActorRef。可以以递归方式为子actor应用相同的原则,确保其preStart()方法只在创建引用时被调用一次。
有关更多信息,请参见重启的含义。
通过消息传递初始化
有些情况下不可能在构造函数中传入actor初始化所需要的所有信息,例如存在循环依赖关系。在这种情况下actor应该监听初始化消息,并使用become()或一个有限状态机状态转换来编码actor的初始化和未初始化状态。
var initializeMe: Option[String] = None
override def receive = {
case "init" =>
initializeMe = Some("Up and running")
context.become(initialized, discardOld = true)
}
def initialized: Receive = {
case "U OK?" => initializeMe foreach { sender() ! _ }
}
如果actor在初始化之前可能收到消息,一个有用的Stash工具可以用来存储消息直到初始化完成,并在actor完成初始化后回放这些消息。
警告
此模式应小心使用,并且仅当上述模式都不适用时才应用。其潜在的问题之一是当发送到远程的actor时,消息可能会丢失。此外,发布一个处于未初始化状态的
ActorRef可能会导致竞态条件,即在初始化完成前它接收到一个用户消息。