架构概览
本文档介绍了 Scrapy 架构及其组件之间的交互。
概述
接下来的图表展现了 Scrapy 的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示)。下面对每个组件都做了简单介绍,并给出了详细内容的链接。数据流如下所描述。
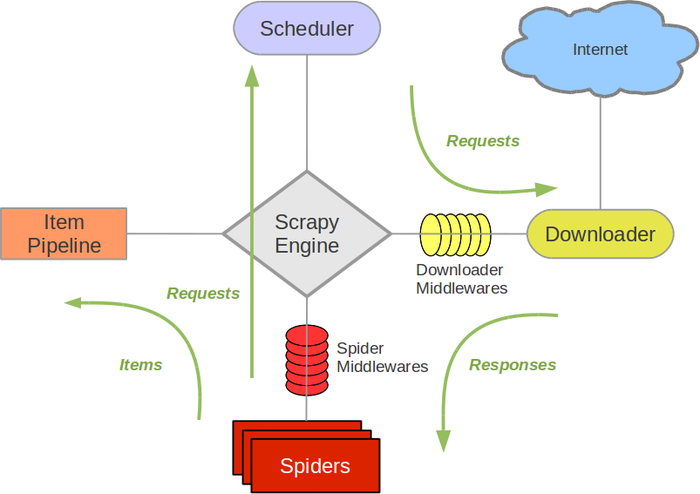
组件
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受 request 并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给 spider。
Spiders
Spider 是 Scrapy 用户编写用于分析 response 并提取 item(即获取到的 item)或额外跟进的 URL 的类。 每个 spider 负责处理一个特定(或一些)网站。更多内容请看 Spiders。
Item Pipeline
Item Pipeline 负责处理被 spider 提取出来的 item。典型的处理有清理、验证及持久化(例如存取到数据库中)。更多内容查看 Item Pipeline。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理 Downloader 传递给引擎的 response。 其提供了一个简便的机制,通过插入自定义代码来扩展 Scrapy 功能。更多内容请看下载器中间件(Downloader Middleware)。
Spider 中间件(Spider middlewares)
Spider 中间件是在引擎及 Spider 之间的特定钩子(specific hook),处理 spider 的输入(response)和输出(items 及 requests)。其提供了一个简便的机制,通过插入自定义代码来扩展 Scrapy 功能。更多内容请看 Spider 中间件(Middleware)。
数据流(Data flow)
Scrapy 中的数据流由执行引擎控制,其过程如下:
- 引擎打开一个网站(open a domain),找到处理该网站的 Spider 并向该 spider 请求第一个要爬取的 URL(s)。
- 引擎从 Spider 中获取到第一个要爬取的 URL 并在调度器(Scheduler)以 Request 调度。
- 引擎向调度器请求下一个要爬取的 URL。
- 调度器返回下一个要爬取的 URL 给引擎,引擎将 URL 通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的 Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到 Response 并通过 Spider 中间件(输入方向)发送给 Spider 处理。
- Spider 处理 Response 并返回爬取到的 Item 及(跟进的)新的 Request 给引擎。
- 引擎将(Spider 返回的)爬取到的 Item 给 Item Pipeline,将(Spider 返回的)Request 给调度器。
- (从第二步)重复直到调度器中没有更多地 request,引擎关闭该网站。
事件驱动网络(Event-driven networking)
Scrapy 基于事件驱动网络框架 Twisted 编写。因此,Scrapy 基于并发性考虑由非阻塞(即异步)的实现。
关于异步编程及 Twisted 更多的内容请查看下列链接: