摘要
1.验证码
2.验证码识别思路
3.验证码的强弱
4.Tesseract
5.Tesseract识别验证码示例
1.验证码
Wikipedia中验证码定义如下:
A CAPTCHA (an acronym for "Completely Automated Public Turing test to tell Computers and Humans Apart") is a type of challenge-response test used in computing to determine whether or not the user is human.
翻译为中文就是:
全自动区分计算机和人类的公开图灵测试,是一种区分用户是计算机和人的公共全自动程序。
验证码有很多种形式,最常见的就是图片验证码(输入图片中的文本进行验证),其他形式还有音频验证码、动画验证码、短信验证码、视频验证码等形式,本文只讨论图片验证码。
2.验证码识别思路
通用的验证码识别是很难做到的,在识别与反识别的斗争中,不同的验证码都演化出了不同的反识别方式,不同的验证码往往需要使用不同的方式来破解验证码的反识别手段。
下面看一组不同展现方式的图片验证码:
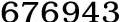 |  |  |  |
 |  |  |  |
 |  |  |  |
验证码识别的步骤如下:
a.二值化
去噪,去掉图片中的噪点,干扰线,干扰字符等,将图片转为二进制的矩阵
b.分割
将图片中的单个字符切分出来
c.标准化
还原旋转、扭曲,骨架细化
d.识别单字符
单字符识别
上面的步骤只是一个大概的思路,对于某些验证码可能一些步骤是不必要的,对于某些验证码可能一些步骤是不可实现的,对于某些验证码可能要改变步骤的顺序或者将一些步骤合并。
3.验证码的强弱
验证码通常会采取一定手段使验证码识别在二值化、分割、标准化三个步骤中增加识别的难度。下面看不同步骤的例子
a.加干扰(对应二值化)
| 几乎没有干扰,很容易二值化 |
| 干扰线,可以剔除固定颜色宽度的横竖线段来消除,二值化比较容易 |
| 干扰线、点与文字颜色相近,二值化比较困难 |
b.防分割
| 垂直字符像素加和为0处分割,很容易 |
| 部分字符粘连,分割比较困难 |
| 全部字符粘连,很难分割 |
c.扭曲(对应标准化)
| 印刷体,没有扭曲 |
| 印刷体,所有字符扭曲一致 |
| 手写体,扭曲不一致 |
加干扰、防分割、扭曲中,干扰通常可以使用特定的方式去掉,可以使用Shape Contents匹配扭曲字符,
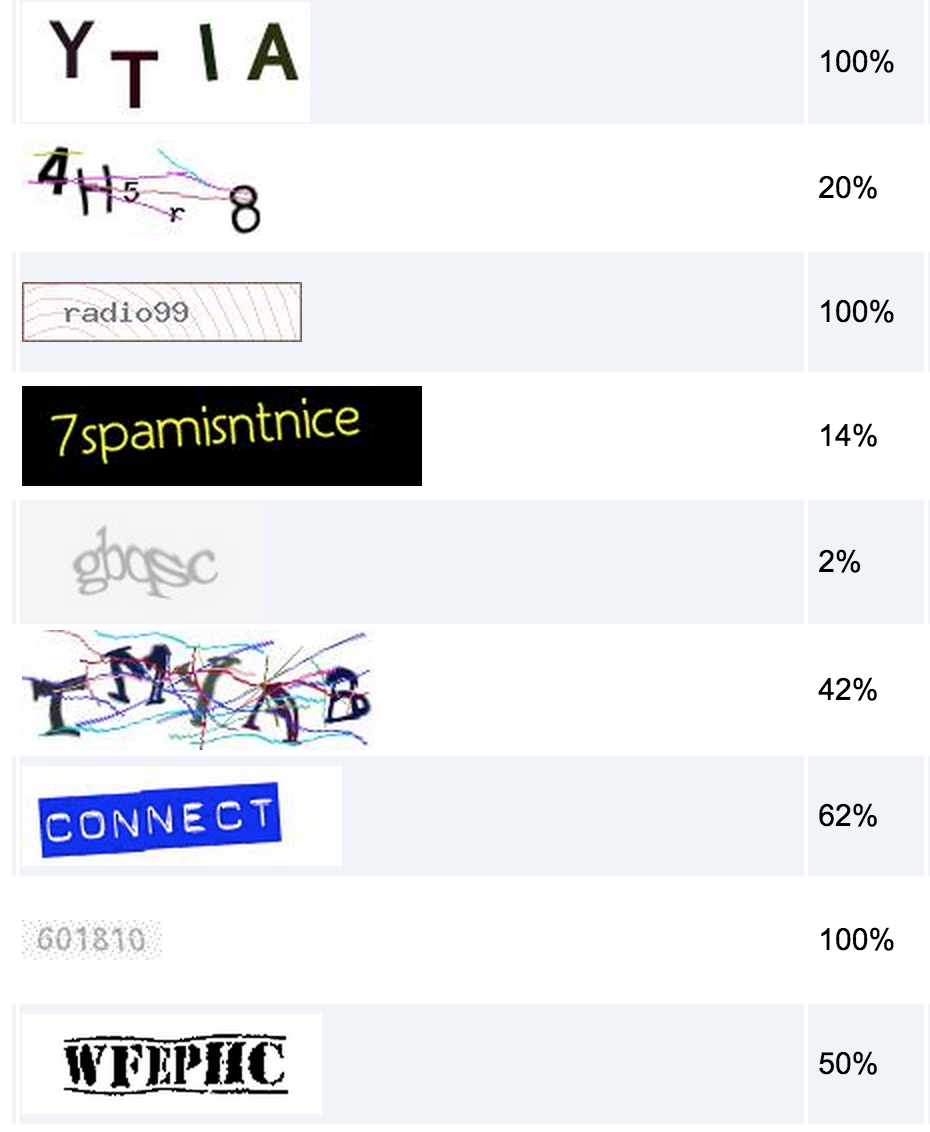
分割的难度往往决定了验证码识别的难度,对于颜色相同又完全粘连的字符,比如google的验证码,目前是没法做到5%以上的识别率的,不过google的验证码基本上人类也只有30%的识别率
下面给出某国外验证码识别服务的一部分验证码识别率数据:
4.Tesseract
Wikipedia介绍:
Tesseract is probably the most accurate open source OCR engine available. Combined with the Leptonica Image Processing Library it can read a wide variety of image formats and convert them to text in over 60 languages. It was one of the top 3 engines in the 1995 UNLV Accuracy test. Between 1995 and 2006 it had little work done on it, but since then it has been improved extensively by Google. It is released under the Apache License 2.0.
项目地址:
https://code.google.com/p/tesseract-ocr/
5.Tesseract识别验证码示例
需要的工具:tesseract-ocr、pytesseract(python模块)、PIL或pillow(python模块)
代码示例:
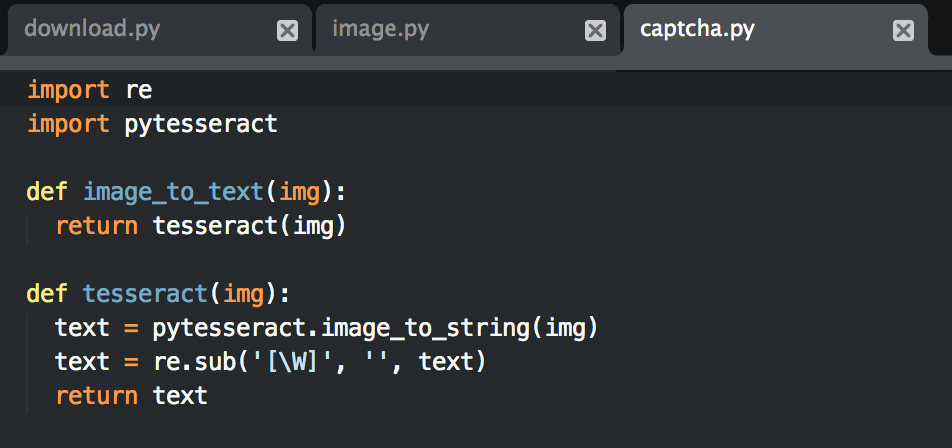
二值化、分割、标准化三个步骤中,对于粘连不严重的验证码Tesseract能很好地处理分割和标准化步骤,我们可以自己处理二值化,然后把剩下的所有工作交给Tesseract处理;
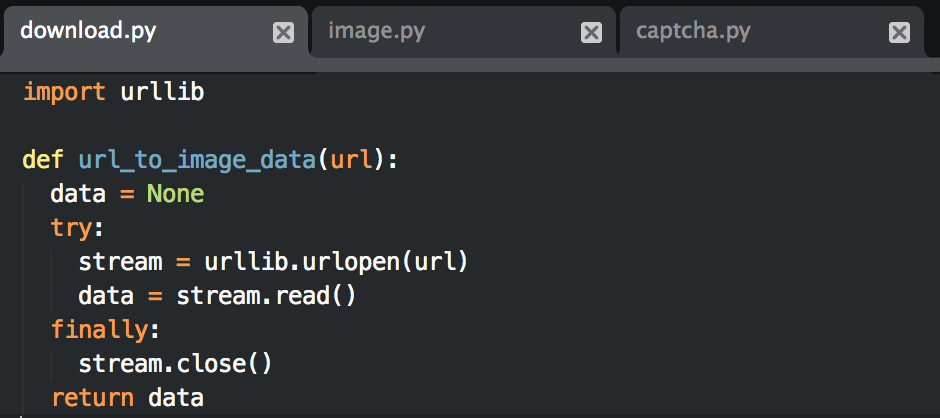
首先写一个pycaptcha模块,负责图片验证码的下载、转换、识别

然后编写测试代码
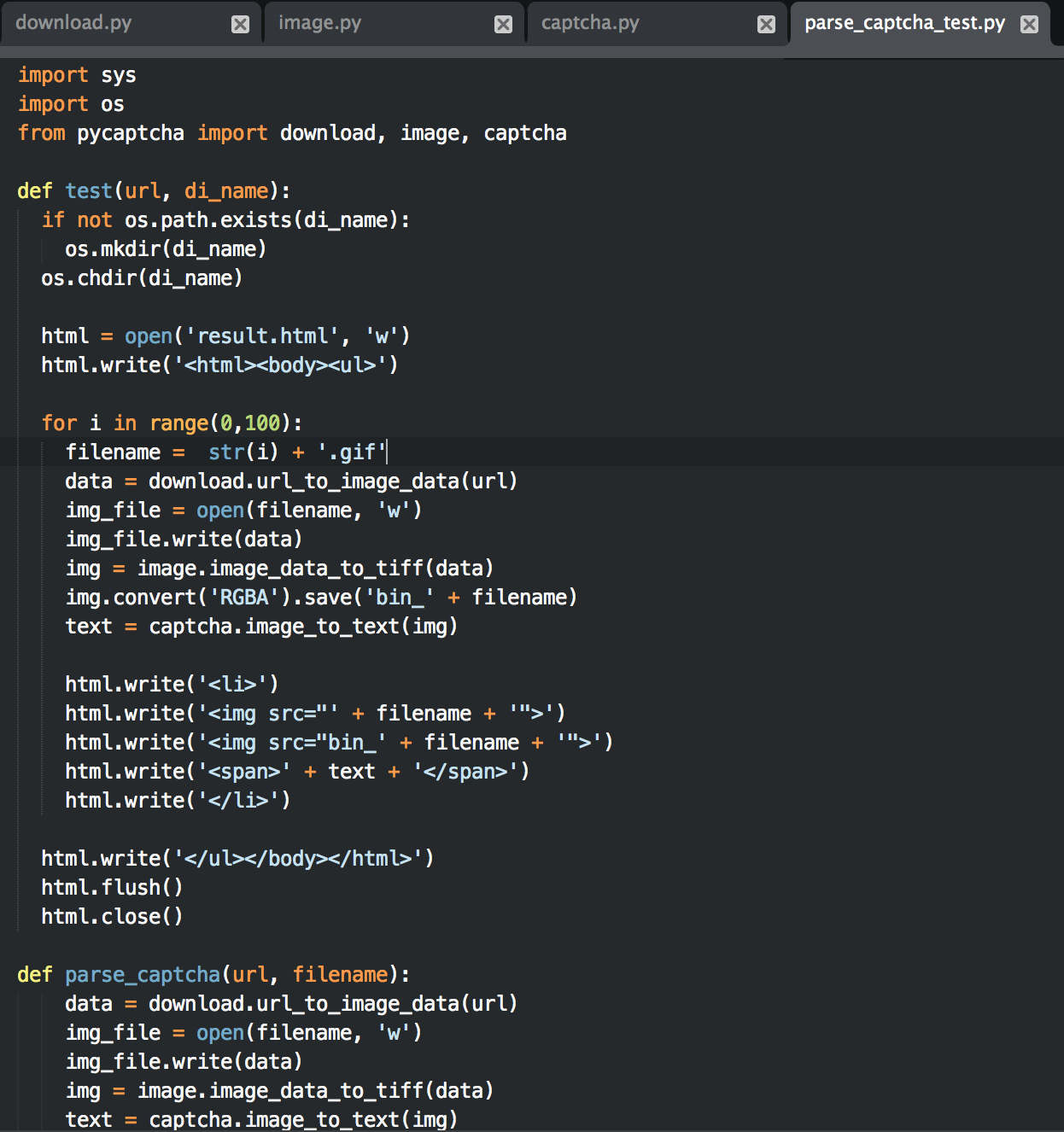

某招聘网站的验证码测试结果如下:

{kind=link}