文本挖掘(text mining),是指抽取有效、新颖、有用、可理解的、散布在文本文件中的有价值知识,并且利用这些知识更好地组织信息的过程。具体说来,文本挖掘以文本型信息源为分析对象,利用智能算法,如神经网络、基于案例的推理等,并结合文字处理技术,分析大量的非结构化文本源(如文档、网页、企业管理日志等),从中寻找信息的结构、模型、模式等各种隐含的知识。
在现实世界中,知识不仅以传统数据库中的结构化数据的形式出现,还以诸如书籍、研究论文、新闻文章、WEB页面及电子邮件等各种各样的形式出现。面对以这些形式出现的、浩如烟海的信息源,人类的阅读能力、时间精力等等往往不够,需要借助计算机的智能处理技术来帮助人类及时、方便的获取这些数据源中隐藏的有用信息。因此,文本挖掘技术就在这种背景下产生和发展起来的。
文本挖掘的根本价值在于能把从文本中抽取出的特征词进行量化来表示文本信息。将它们从一个无结构的原始文本转化为结构化的计算机可以识别处理的信息,即对文本进行科学的抽象,建立它的数学模型,用以描述和代替文本。使计算机能够通过对这种模型的计算和操作来实现对文本的识别。
文本挖掘是数据挖掘的一个分支,在各方面存在着一些差异,如下表所示:
| 数据挖掘 | 文本挖掘 |
|---|---|---|
研究对象 | 用数字表示的、结构化数据 | 无结构或半结构的文本 |
对象结构 | 关系数据库 | 自由开放的文本 |
目标 | 获取知识、建立应用模型 预测以后的状态 | 提取概念和知识 |
方法 | 归纳学习、决策树、神经网络、关联规则等 | 提取短语、形成概念, 关联分析、聚类、分类 |
成熟度 | 1994年开始得到广泛应用 | 从2000年开始得到广泛应用 |
文本挖掘的作用在于提高了海量非结构化信息源的利用价值,使得人们能够更加方便地从海量文本中发现隐含的知识。因此,文本挖掘广泛应用于以下领域:
1、网上有害信息监测、过滤和跟踪
2、科技文献分析
3、网上论坛/社交媒体的实时监控
4、电子邮件分类与过滤
文本挖掘主要涉及四个方面的内容,即文本分类、文本聚类、文本结构分析、web文本数据挖掘,分别简介如下:
文本分类指按照预先定义的主题类别,为文档集合中的每个文档确定一个类别。这样用户不但能够方便地浏览文档,而且可以通过限制搜索范围来使文档的查找更容易、快捷。目前,用于英文文本分类的分类方法较多,用于中文文本分类的方法较少,主要有朴素贝叶斯分类(Naïve Bayes),向量空间模型(Vector Space Model)以及线性最小二乘LLSF(Linear Least Square Fit)。
聚类与分类的不同之处在于,聚类没有预先定义好的主体类别,它的目标是将文档集合分成若干个簇,要求同一簇内文档内容的相似度尽可能的大,而不同簇之间的相似度尽可能的小。
作为一种无监督的机器学习方法,文本聚类由于不需要训练过程,以及不需要预先对文档手工标注类别,因此具有一定的灵活性和较高的自动化处理能力,已经成为对文本信息进行有效地组织、摘要和导航的重要手段,为越来越多的研究人员所关注。
文本结构分析的目的是为了更好地理解文本的主题思想,了解文本表达的内容以及采用的方式,最终结果是建立文本的逻辑结构,即文本结构树,根结点是文本主题,依次为层次和段落。文本结构分析可以有效地改进文本摘要、文本检索以及文本过滤的精度。
近年来,随着因特网技术的快速普及和迅猛发展,各种信息可以以非常低的成本在网络上获得,由于因特网在全球互联互通,可以从中取得的数据量难以计算,人类正处于海量网络信息的包围之中,如何在因特网这个全球最大的数据集合中发现有用信息无疑将成为数据挖掘研究的热点。但是Web页面过于复杂,而且是无结构的、动态的,导致人们难以迅速、方便地在Web上找到所需要的数据和信息。
Web数据挖掘是数据挖掘技术在Web环境下的应用,是涉及Web技术、数据挖掘、计算机技术、信息科学等多个领域的一项技术。Web数据挖掘能帮助人们从Web上快速、有效的发现资源和知识。当前,文本挖掘正面临着挖掘算法的效率和可扩展性、遗漏及噪声数据的处理、私有数据的保护与数据安全性等问题。
六、文本挖掘涉及到的常用术语
词的频率 (Team Frequency, TF):就是将词在文本中出现的频率作为词的权重。这种方法使得不同长度的文本模型有统一的取值空间,但无法解决“高频无意义词汇权重大的问题”
词频 - 逆向文本频率 (Term Frequency -Inverse Document Frequency, TF-IDF):它是对 TF 方法的一种加强,字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在所有文本中出现的频率成反比下降。举个例子,对于“高频无意义词汇”,因为它们大部分会出现在所有的文本中,所以它们的权重会大打折扣,这样就使得文本模型在描述文本特征上更加精确。在信息检索领域,TF-IDF 是对文本信息建模的最常用的方法。
经典的向量空间模型(VSM: Vector Space Model)由Salton等人于60年代提出,并成功地应用于著名的SMART文本检索系统。VSM把对文本内容的处理简化为向量空间中的向量运算,并且它以空间上的相似度表达语义的相似度,直观易懂。当文档被表示为文档空间的向量,就可以通过计算向量之间的相似性来度量文档间的相似性。
文本处理中最常用的相似性度量方式是余弦距离。文本挖掘系统采用向量空间模型,用特征词条(T1 ,T2 ,…Tn) 及其权值Wi 代表目标信息,在进行信息匹配时,使用这些特征项评价未知文本与目标样本的相关程度。特征词条及其权值的选取称为目标样本的特征提取,特征提取算法的优劣将直接影响到系统的运行效果。设D为一个包含m个文档的文档集合,Di为第i个文档的特征向量,则有
D={D1,D2,…,Dm}, Di=(di1,di2,…,din),i=1,2,…,m
其中dij(i=1,2,…,m;j=1,2,…,n)为文档Di中第j个词条tj的权值,它一般被定义为tj在Di中出现的频率tij的函数,例如采用TFIDF函数,即dij=tij*log(N/nj)其中,N是文档数据库中文档总数,nj是文档数据库含有词条tj的文档数目。假设用户给定的文档向量为Di,未知的文档向量为Dj,则两者的相似程度可用两向量的夹角余弦来度量,夹角越小说明相似度越高。相似度的计算公式如下:
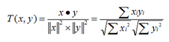
通过上述的向量空间模型,文本数据就转换成了计算机可以处理的结构化数据,两个文档之间的相似性问题转变成了两个向量之间的相似性问题。
一般来说网络文本的获取,主要是网页的形式。我们要把网络中的文本获取形成一个文本数据库(数据集)。利用爬虫技术抓取到网络中的信息。爬虫可以有主题爬虫和通用爬虫之分,主题爬取主要是在相关站点爬取或者爬取相关主题的文本 ,而通用爬虫则一般对此不加限制。
由于网页中存在很多不必要的信息,比如说一些广告,导航栏,html、js代码,注释等等,接下来还需要对文本中的信息进行筛选,也就是对文本进行预处理。
经过上面的步骤,能得到比较干净、可用的文本信息。我们知道,文本中起到关键作用的是一些关键词,这些关键词决定着文本的取向。这里就会用到一个分词系统或者说分词工具。现在常见分词的算法有最大匹配法、最优匹配法、机械匹配法、逆向匹配法、双向匹配法等。目前国内普遍用到的是中科院的分词工具ICTCLAS ,该算法经过众多科学家的认定是当今中文分词中最好的,并且支持用户自定义词典,加入词典。对新词、人名、地名等的发现也具有良好的效果。
经过上面的步骤,基本能够得到有意义的一些词。但是这些所有的词都有意义吗?显然不是这样的,有些词会在这个文本集中大量出现,有些只是出现少数几次而已。他们往往也不能决定文章的内容。还有一个原因就是,如果对所有词语都保留,维度会特别高,矩阵将会变得特别特别稀疏,严重影响到挖掘结果。那么对这些相对有意义的词语选取哪一本分比较合理呢?针对特征选择也有很多种不同的方式,但是改进后的 TF*IDF 往往起到的效果是最好的。tf-idf 模型的主要思想是:如果词w在一篇文档d中出现的频率高,并且在其他文档中很少出现,则认为词w具有很好的区分能力,适合用来把文章d和其他文章区分开来。
经过上面的步骤之后就可以把文本集转化成一个矩阵。然后再利用各种算法进行挖掘,比如说如果要对文本集进行分类,我们可以利用 KNN算法、贝叶斯算法、决策树算法等等。文本挖掘的结果可以通过各种可视化的技术展现出有意义的图表,比如:人物关系图、力导向布局图、和弦图等,这些带有业务意义的、表现力丰富的图表能帮助人们对文本挖掘结构的理解。