摘要:
- Splash简介
- Splash安装
- Splash与Scrapy结合
- 使用Splash执行Javascript
- 参考资料
使用Javascript渲染和处理网页是种非常常见的做法,如何处理一个大量使用Javascript的页面是Scrapy爬虫开发中一个常见的问题,这篇文章将说明如何在Scrapy爬虫中使用Splash来处理页面中得Javascript。
Splash简介
Splash是一个Javascript渲染服务。它是一个实现了HTTP API的轻量级浏览器,Splash是用Python实现的,同时使用Twisted和QT。Twisted(QT)用来让服务具有异步处理能力,以发挥webkit的并发能力。
Splash安装
安装Splash最简单的方式是使用Docker,只需要执行下面命令
$ docker pull scrapinghub/splash
$ docker run -p 8050:8050 scrapinghub/splash
Splash与Scrapy结合
Scrapy爬虫中如何使用Splash服务?使用ScrapyJS是官方推荐的方式。
1.安装ScrapyJS:
pip install scrapyjs
2.修改Scrapy项目配置
在Scrapy项目的settings.py中添加下面代码:

3.请求中添加Splash参数
在Scrapy请求的meta中使用splash参数,则该请求会发送的Splash服务进行渲染
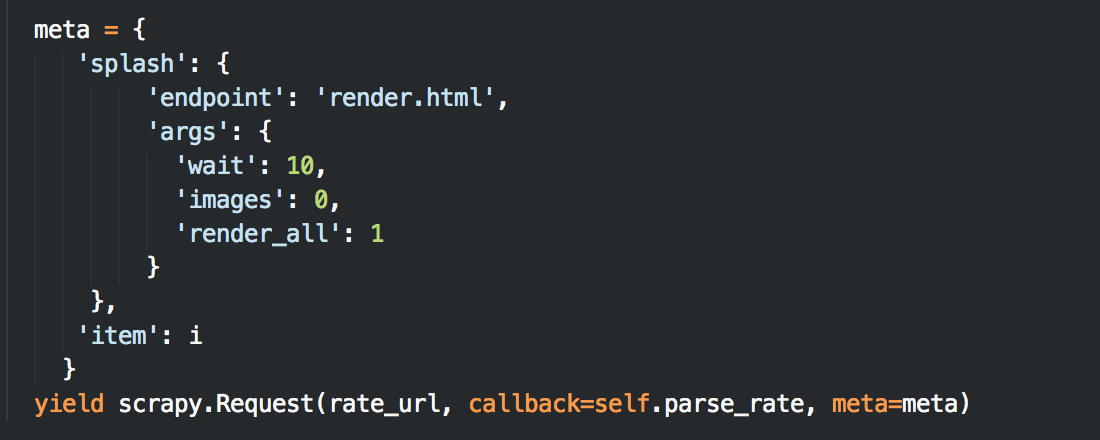
如果需要从起始url就进行渲染,则需要修改start_requests方法

请求中具体的参数参考http://splash.readthedocs.org/en/latest/api.html
使用Splash执行Javascript
Splash官方推荐使用Splash Scripts(Lua脚本)执行Javascript,示例如下:
示例中script为一个Splash Scripts,该脚本跳转到http://example.com,等待0.5秒,执行一个Javascript(document.title),返回{title=Javascript执行结果}的一个lua table;
parse方法中将获得一个JSON返回值
{
"title": "Some title"
}
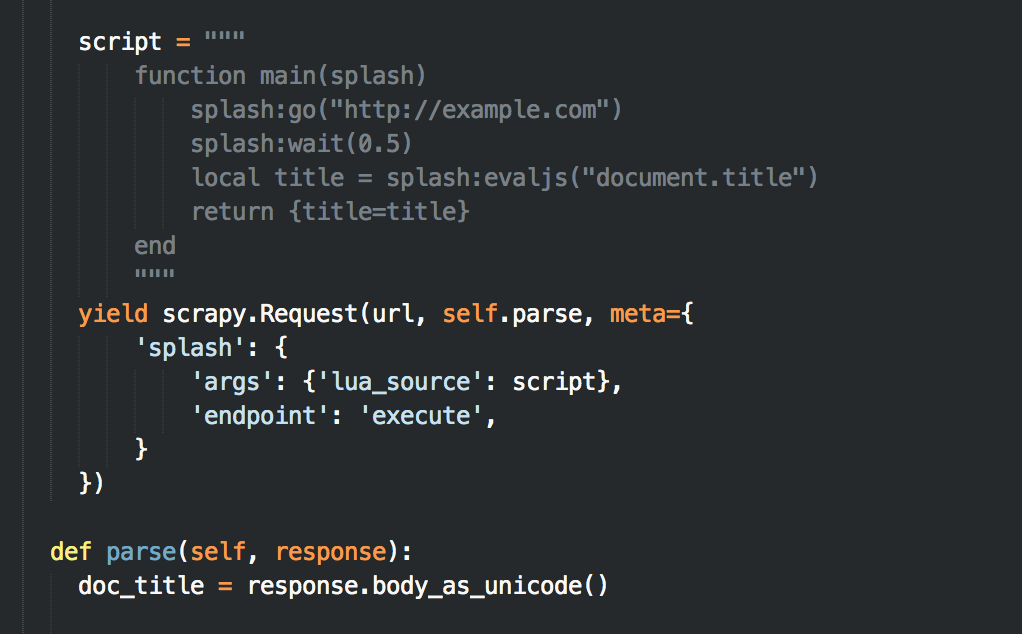
每个Splash Scripts都需要一个main方法作为入口。返回值中Lua table将会转为JSON
很多场景下都需要页面点击一个按钮,然后获取页面中的一部分数据;可以使用JQuery点击实践来实现,Splash Script示例如下:
function main(splash)
splash:autoload("https://ajax.googleapis.com/ajax/libs/jquery/2.1.3/jquery.min.js")
splash:go("http://example.com")
splash:runjs("$('#some-button').click()")
return splash:html()
end
参考资料
Scrapinghub博客:http://blog.scrapinghub.com/
Splash官方文档:http://splash.readthedocs.org/en/latest/scripting-tutorial.html
Github中ScrapyJS项目:https://github.com/scrapinghub/scrapyjs