摘要:
网站为什么要反爬虫
网站反爬虫的方式
如何应付反爬虫的网站
网站为什么要反爬虫
1.不希望爬虫获得网站中的数据;比如说像taobao这种网站,本身有一个开发平台,里边有些api是收费的,如果不采取反爬虫的手段,就会失去大部分付费api的收入

2.减小服务器压力,网站支持请求处理速度是有限的,支持大规模用户的并发访问需要投入很多资源,而爬虫发送请求的速度可以远远超过正常用户发送请求的速度,尤其是一些处理逻辑简单,比如直接抓取全部页面的爬虫,会给服务器增加一些压力
网站反爬虫的方式
1.Robots协议:
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
按照Robots协议,robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。
下面是Tmall的robots.txt,禁止来自baidu的爬虫抓取网站中任何页面
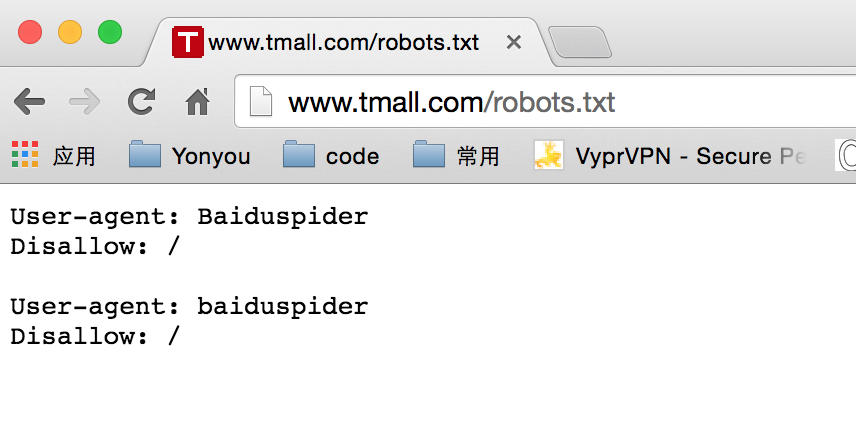
Robots协议是国际互联网界通行的道德规范,不是强制规定,是否遵守Robots协议,完全取决于爬虫的开发者,使用Robots协议不能保证站内的页面不被爬虫抓取
2.识别爬虫,进行处理:
识别爬虫:
用户使用浏览器访问网站,识别爬虫就是识别收到的请求与真正人使用浏览器发出的请求是否有差异;比如说请求速度的差异,人使用浏览器发送请求一般比较慢,如果一个ip在单位时间内发出大量的请求,则有可能是爬虫
处理可疑请求:
可以直接返回服务器错误、返回到禁止爬虫的提示页面、返回302让浏览器跳转的登录页面(用户名密码登录、用户名密码验证码登录、短信验证登录)
如何应付重度反爬虫的网站
如果网站的反爬虫机制有漏洞,则可以针对这个漏洞来破解该网站的反爬虫机制,比如简单登录成功设置cookie,每次请求验证cookie,可以模拟post请求登录,保存cookie,在请求中发送cookie中内容;如果网站反爬虫机制没有漏洞,或者找不到漏洞,或者破解方法成本太高,则需要让爬虫的请求尽量和人使用浏览器请求一致。
下面给出使用selenium的半自动爬虫抓取tmall的商品数据的示例
tmall的反爬虫机制:
通过单位时间的请求数识别爬虫,具体规则未知,第一次识别为疑似爬虫的阀值比较低,真人使用浏览器频繁点击也会被识别,识别为疑似爬虫的处理方法依次为用户名、密码验证,用户名、密码、验证码验证,短信验证
爬虫的处理方式:
1.识别登录页面:
爬虫发送的请求被识别为疑似爬虫都会跳到登录页面进行用户验证,分析登录页面也商品列表页面、商品页面的差异,来找到识别登录页面的方法
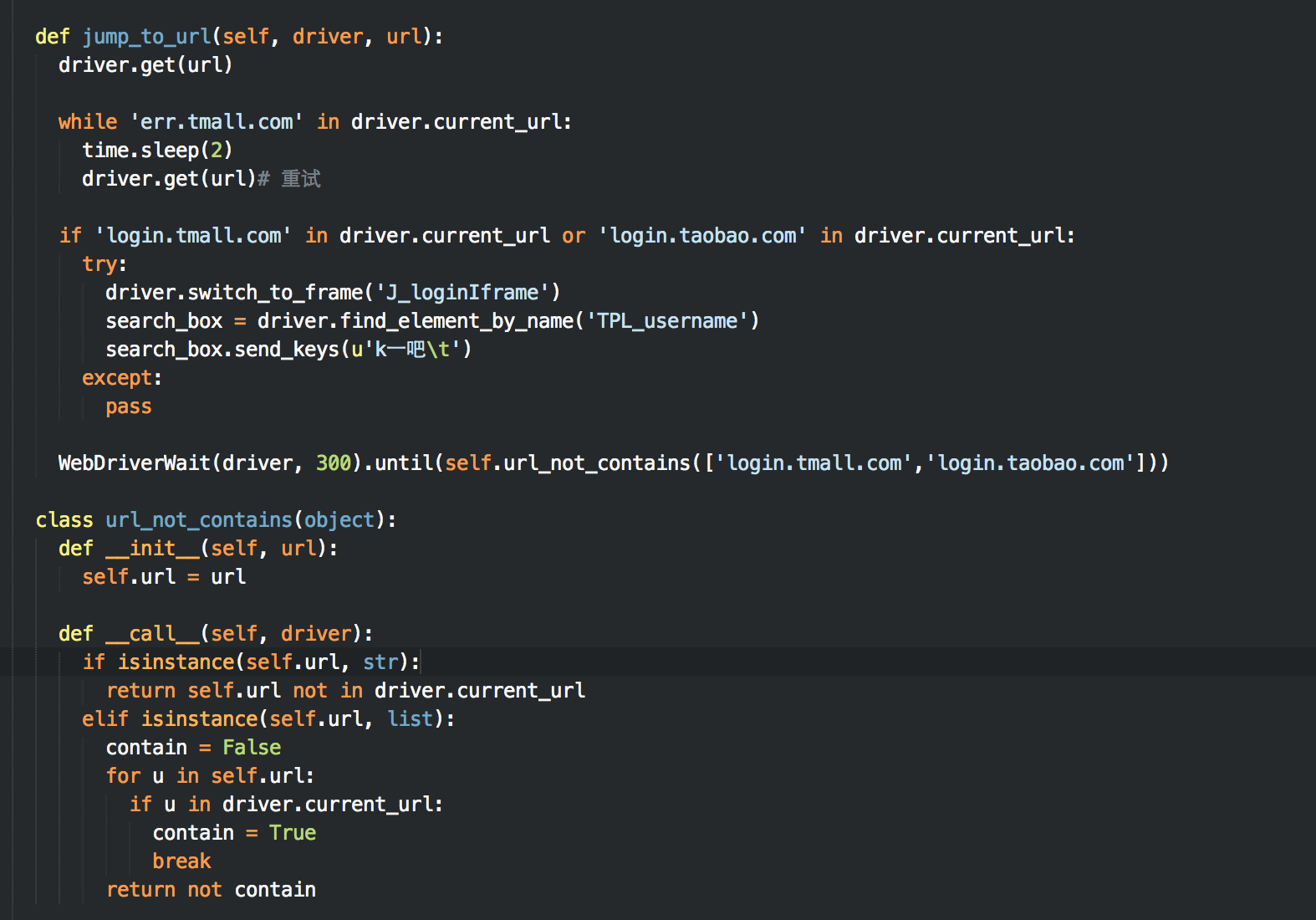
这里当前url来识别是否为登录页
2.登录页面的处理:
Tmall的登录页面可能验证用户名、密码、验证码、短信验证码,前两个为固定值,后两个比较难处理,所以采用半自动的方式人工进行处理;当登录页面的url不是登录url时再继续抓取网页
示例代码如下:
每次抓取网页使用jump_to_url方法请求页面,进行登录验证(如果重定向到了登录页面),jump_to_url方法之后,浏览器处于已登录状态,可以使用selenium正常抓取数据
{kind=link}