1. Scrapy简介
Scrapy是使用Python语言编写的开源爬虫框架,可对互联网中的网页内容进行抓取,并从中提取出结构化数据,提取到的数据可用于资料收集、舆情分析、数据挖掘等多个领域。
Scrapy基于由事件驱动的网络引擎框架Twisted编写,可以对网站页面进行大量非阻塞的异步请求,能够对目标网站按照网站结构的层级次序逐级向下采集,并可以在已采集到的页面中提取其他符合要求的目标网页地址资源,从而实现从单个或多个入口进入,对目标网站进行全面扫描并获取所需的数据。
目前我们已经基于Scrapy编写了65个不同种类的爬虫,所采集的内容涵盖新闻、微博、博客、论坛、报告、会议、宏观数据指标、上市公司信息、汇率、电商、招聘职位等多种数据。
2. 组件
在Scrapy中定义了多种不同类型的组件,按照功能和职责的不同可将组件分为以下几类:
2.1 Scrapy引擎(Scrapy Engine)
Scrapy引擎负责控制数据流在整个系统的各个组件间的流动过程,并在特定动作发生时触发相应事件。
2.2 调度器(Scheduler)
调度器负责调度爬虫的抓取过程,接受Scrapy引擎传递过来的Request对象,并将该对象加入队列中,下次Scrapy引擎发出请求时再将对象传递给引擎。
2.3 下载器(Downloader)
下载器负责对目标页面发出请求并获取页面反馈的数据,之后传递给Scrapy引擎,最终传递给爬虫进行数据提取。
2.4 爬虫(Spiders)
爬虫是Scrapy的用户自行编写的一段数据提取程序,针对下载器返回的数据结构进行分析(一般为HTML),并提取出其中的结构化数据,并可以指定其他需要跟进的URL和处理方法。
每个爬虫负责处理一个或多个特定的网站。
2.5 爬虫结果数据(Item)
Item是爬虫针对网页数据做解析后返回的数据,需要在使用之前预先定义好Item的数据结构,爬虫的解析程序负责将提取到的数据填充到Item中,并将Item返回,传递给数据管道进行后续处理。
2.6 数据管道(Item Pipeline)
数据管道负责处理被爬虫提取出来的Item数据,可定义多个数据管道来做多种不同的处理操作,比如数据清理、验证、写入数据库、写入数据文件等等操作。Item可以在不同的数据管道中进行传递,可以设置每个数据管道的优先级,Item会按照优先级依次经过所有的数据管道。
3. 数据流
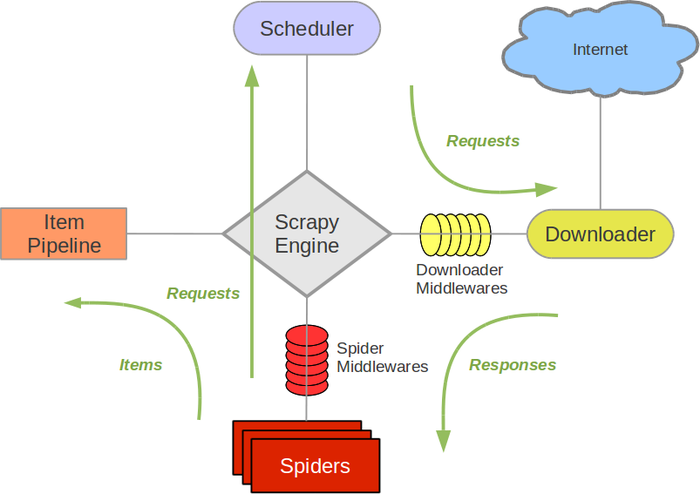
上图展现了Scrapy内部各组件间数据流转的情况。参照上图,可将数据流转的整个过程梳理成如下步骤:
- 在启动爬虫程序时,Scrapy引擎找到处理该网站的爬虫,并向该爬虫请求第一个要抓取的URL地址(该地址在爬虫中进行定义)。
- Scrapy引擎从爬虫中获取到第一个要抓取的URL,并通过调度器将该URL地址传递给下载器。
- 下载器对URL发出请求,并获得页面返回的数据,将返回的数据以Response的形式传递给爬虫。
- 爬虫针对Response中的数据进行分析,提取出结构化数据后,将数据填充到Item中,并传递给数据管道。
- 数据管道根据优先级顺序对Item依次进行处理,经过数据清理、验证等处理过程, 最终将Item中的数据写入数据库或文件中。
- Scrapy引擎从爬虫获取下一个需要抓取的URL,从第二步开始继续执行处理过程。
- 处理过程一直重复,直到没有更多的URL可被抓取时,Scrapy引擎将关闭对该网站的处理过程。
4. 参考资料
l Scrapy的官网地址:http://scrapy.org
l Scrapy在Github上的项目地址:https://github.com/scrapy/scrapy.git
l Scrapy的官方文档地址:http://doc.scrapy.org/