1、背景
某移动公司拥有2200万移动用户,月度呼入10086用户超过300万,客服中心已成为移动公司倾听客户心声的首要界面,每天与客户的互动中沉淀了大量客户接触数据。然而,该移动公司在客服中心数据价值挖掘方面,存在两个方面的不足:客服中心自身对客户接触沉淀的数据挖掘不充分;传感器作用不明显,跨部门的数据融合亟待加强。
如何挖掘隐藏在这些数据中价值、提高客服中心的数据影响力,是当下该移动公司客服中心领导关心的重要课题。
2、解决思路
解决以上两个方面问题的关键在于找到合适的切入点。经过项目组和客服中心项目需求人员的充分沟通,最终项目选择了以客户需求智能预测模型为切入点。解决方案主要分为三个板块:一是构建客户需求智能预测模型,二是在模型基础上输出应用,三是建立跨部门的数据聚合与分析应用工作机制。
以下将重点介绍时序关联规则在客户需求智能预测方面的应用。
3、客户需求预测的建模过程
3.1 明确建模框架与原理
美国东北大学教授网络科学研究中心的创始人、主任艾伯特-拉斯洛·巴拉巴西曾指出:人类行为93%是可以预测的。无论是自然界还是人造世界,许多事情遵循幂律分布,一旦幂律出现,爆发点就会出现。客户需求预测模型的基本原理是:通过对已明确表达过需求的客户进行分类,聚合提炼出某类需求背后的“固定”行为模式,也就是形成样本客户的行为模式DNA库,再通过目标预测客户行为模式与DNA库中的行为模式进行匹配,根据行为模式的吻合度来预测客户将要表达的高概率需求是什么。据此原理,需要先找到样本客户、定义样本客户的行为模式。
3.2 数据的提取与整理
取数对象为移动公司的全网用户,时间窗口为13年7月-14年2月。取数需求分为9张表:客户基本属性表、拨打10086明细表、人工服务明细表、拨打1008611明细表、下发知识短信明细表、拨打路径明细表、查询办理明细表、拨打节点配置表、月度统计表。涉及字段近200个。
获得数据后,进行数据质量审核,并完成数据的清洗和整理。首先剔除缺失及明显逻辑错误数据,然后分月整合各平台各渠道清单级数据集,并形成统一格式,最后通过客户编码、业务代码联接不同平台渠道的数据集,合并生成宽表。
3.3 样本集客户名单筛选
样本客户界定:12月通过拨打人工、知识短信等方式明确表达过呼入需求的所有客户。
样本客户时间选取原则:承前启后、能进能退。亦即往前退3-5个月可追溯客户行为轨迹,往后推1-2个月可验证预测结果。本次取数的月份为13年8月—14年2月,选12月份为样本集的取数时间段。同时,定义8-12月为样本客户观察窗口,其中12月为样本客户号码提取窗口;定义1月、2月为规则验证窗口。这样就可以分析样本客户在8-12月的行为特征,形成特征规则,并在1月、2月进行规则验证。
样本客户筛选:提取12月份已通过10086明确表达过的需求(投诉、咨询和办理)的客户名单,将这部分客户作为样本集来研究其行为模式特征。其中,咨询业务通过业务编码与知识短信下发流水号来匹配识别,投诉业务通过工单流水号与投诉导航问卷来匹配识别,业务办理通过知识短信、10086人工办理明细表匹配识别。通过以上方法,共提取样本客户150万人,约占12月份所有呼入客户的17%。
3.4 确定模型技术方案
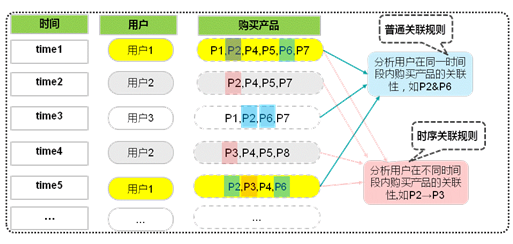
客户需求预测实际上属于客户行为模式识别领域。通常在持续时间长、接触范围广、涉及业务多的情况下,研究客户行为模式的算法主要有三种:即普通关联规则、路径分析、时序关联规则。通过对比三种算法的优点与不足,最终选择的是时序关联规则。
| 普通关联规则 | 路径分析 | 时序关联规则 |
优点 | 能够得出客户表达需求前的关键节点(大的支持度节点) | 能够准确描述各节点的时序; | 时序关联规则既能体现各节点间的时序,又能将随机的非共性节点剔除; |
不足 | 业务可解释性不强,不能体现各节点间的时序,与分析需求不符 | 易将非共性节点纳入路径中,不易得出关键节点 | 从模型结果中挑选出符合业务要求的规则稍显费力 |
时序关联规则简介:
时序关联规则基本思想是在原先的事务记录的基础上,构造出项目集序列,由按照时间先后顺序排列的项目集构成。
时序关联规则的特点:
(1)数据是离散的。由于关联规则方法本身的特征.它要求数据必须是离散化的,这样才能进行技术统计。
(2)得到的结果是以规则形式表达的,而不可能得到函数形式的模式,这也是关联规则方法本身的特点造成。
(3)所谓时序关系,在处理的时候表现为前后的组合关系。
通过一个例子来比较时序关联规则与普通关联规则:
3.5 模型训练与规则输出
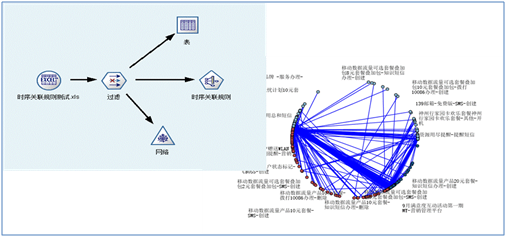
利用SPSS Modeler 进行数据建模,建模的主要字段为userid,time,name,cnt,其中name表示客户发生业务动作的名称,time表示发生该业务动作的时间。
模型训练过程,如下图所示:
经过对置信度和支持度的调整优化后,得到符合业务要求的规则(如下图所示):
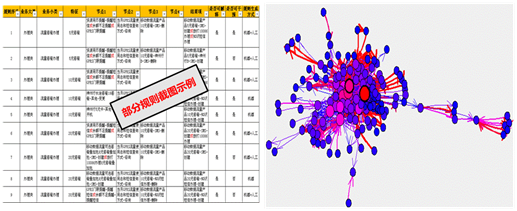
最终, 入模观测数28096203,最小支持度1%,最小置信度50%,最大路径项数为6项,生成规则数2692条,其中需求路径规则数259条,覆盖的需求业务数为25项,业务数为61项。
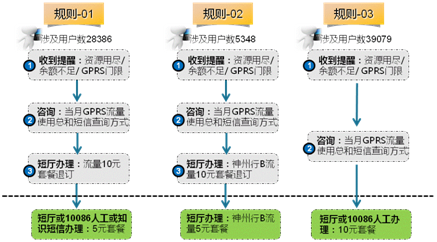
输出规则示例如下:
3.6 模型校验与调整
验证用户:2014年1月拨打人工客服用户(除去黑名单、月日高频拨打用户)
数据周期:用户在2013年9月-2014年1月各渠道行为数据
规则准确率计算过程:使用用户在2013年9月-2014年1月的行为数据,得出用户行为规则,将该规则与训练集规则A→B进行比对,其中,满足规则A→B的用户数在满足A的用户数中的占比即为规则的准确率:规则准确率=sup(A→B)/sup(A)
使用2014年1月的数据对选取规则进行验证,经测算259个规则的平均准确率达65.4%,说明模型有较高精度。
4、客户需求预测模型的应用
4.1 应用场景1:话务分流
基本思想:提前识别客户的需求,并针对客户呼入后可能产生人工话务的环节进行提前干预,抑制客户的人工话务量
应用价值:减少人工话务量,减少人工服务压力,逐步培养客户习惯
步骤1:筛选出可做话务分流的规则和客户。筛选方式是:选取节点和结果项中涉及人工话务的规则,再基于业务经验评估分流的可能性
步骤2:对筛选出的规则进行分类梳理,主要分为5类:提醒触发类、查询后续类、开机重启类、重复动作类、资费变更类
步骤3:针对5类场景提出相应的分流举措
举措1、优化短信内容
1)各类提醒短信中增加流量使用总和查询方式。
2)客户开通流量门限提醒时,可个性化设定提醒的方式、频次、时段、额度,告知客户通过网站定制化提醒。
举措2、IVR个性化设计
1)接收到GPRS门限提醒、资源用尽提醒等流量类提醒短信后,30分钟内呼入10086的客户,首层IVR语音提醒客户办理叠加包或套餐变更的方式,或者直接按3号键办理叠加包或流量套餐。
2)接收到余额不足提醒或月结前提醒,30分钟内呼入10086的客户,首层IVR语音提醒客户充值方式或直接按2号键进行话务充值,如需查询账单请按1号键。
4.2 应用场景2:开展呼入式精确营销
有两种方式实现呼入式精确营销:
预知式:根据客户行为模式、客户画像模型预测客户会存在某类业务需求
触发式:客户电话接入后,人工判断客户在此次诉求表达时隐藏某类业务需求
在预知式精确营销模式下,客服中心可根据客户预测模型的规则来筛选符合某项业务的目标客户,通过热线外呼或前台推荐等方式开展主动营销。只要预测的准确度够高,营销的时机把握得当的话,这种方式还是可以达到较好的成功率的。
5、客户需求预测模型的不足与优化方向
客户需求预测模型是基于已有的、且有一定频次的事务进行运算的,对新增的需求及业务办理敏感度,样本集的规则库需要根据预测的精准度和可预测的客户范围进行适时的调整。另外,该模型不能自动给规则节点自动生成时间标签,只能体现先后顺序。
客户需求预测模型下一步可考虑增加模型的智能性,引入机器学习算法,能够实现模型的自学习、自优化。另外,可以进一步扩展模型的应用场景。